
 Email regex (source: Pietrodn on Wikimedia Commons)
Email regex (source: Pietrodn on Wikimedia Commons) Many data science, analyst, and technology professionals have encountered regular expressions at some point. This esoteric, miniature language is used for matching complex text patterns, and looks mysterious and intimidating at first. However, regular expressions (also called “regex”) are a powerful tool that only require a small time investment to learn. They are almost ubiquitously supported wherever there is data. Several analytical and technology platforms support them, including SQL, Python, R, Alteryx, Tableau, LibreOffice, Java, Scala, .NET, and Go. Major text editors and IDE’s like Atom Editor, Notepad++, Emacs, Vim, Intellij IDEA, and PyCharm also support searching files with regular expressions.
The ubiquity of regular expressions must mean they offer universal utility, and, surprisingly, they do not have a steep learning curve. If you frequently find yourself manually scanning documents or parsing substrings just to identify text patterns, you might want to give them a look. Especially in data science and data engineering, they can assist in a wide spectrum of tasks, from wrangling data to qualifying and categorizing it.
In this article, I will cover enough regular expression features to make them useful for a great majority of tasks you may encounter.
Setting up
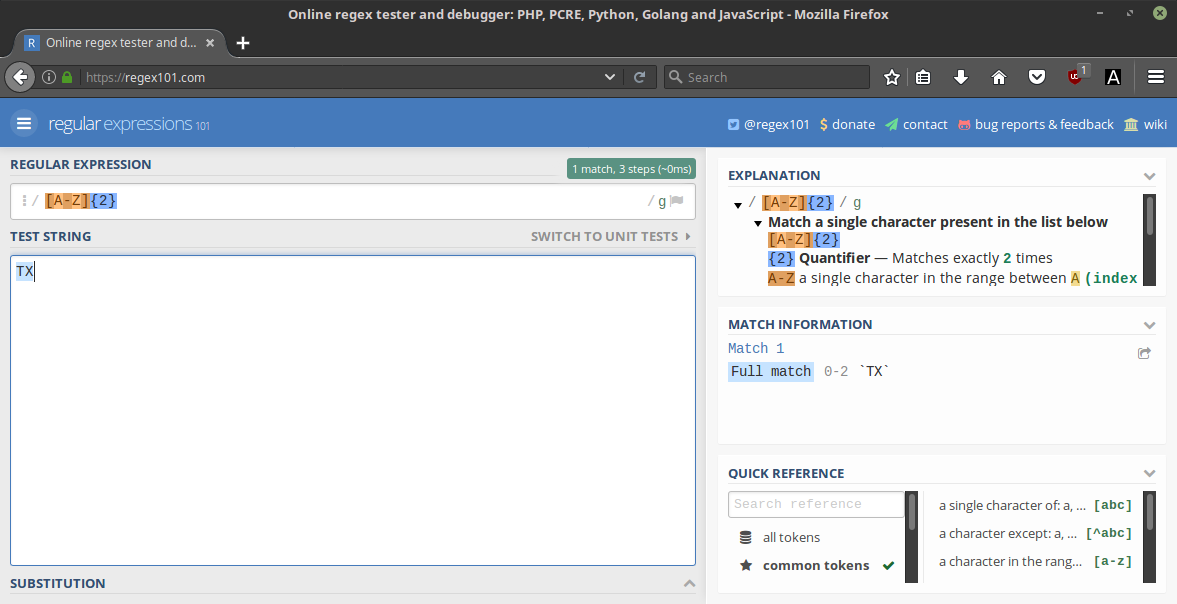
You can test these examples I am about to walk through in a number of places. I recommend using Regular Expressions 101, a free web-based application to test a regular expression against text inputs. As we go through these examples, type in the regular expression pattern in the “Regular Expression” field, and a sample text in the “Test String” field. You will then immediately see in the right panel whether a full or partial match succeeded, as well as a broken down explanation of what your regex is doing (see Figure 1).
For Python, you can also import and use the native re package as shown below. The fullmatch() function will accept a regex pattern and an input string to test against. It will return a match object if a full match exists.
import re
result = re.fullmatch(pattern="[A-Z]{2}", string="TX")
if result:
print("match")
else:
print("Doesn't match")
Now that you are set up, we will walk through all the major functionalities offered by regular expressions.
Literals and special characters
A regular expression matches a broad or specific text pattern, and is strictly read left-to-right. It is input as a text string itself, and will compile into a mini program built specifically to identify that pattern. That pattern can be used to match, search, substring, or split text.
Most characters, including alphabetic and numeric characters, have no special functionality and literally represent those characters. For instance, a regex of TX will only match the string TX.
REGEX: TX INPUT: TX MATCH: true REGEX: TX INPUT: AZ MATCH: false
However, a small subset of characters have special functionalities we will learn throughout this article. These characters include the following:
[\^$.|?*+()
If you want to treat these characters as literals, you need to precede them with an escape \. To create a literal regex that matches $180, we need to escape that dollar sign so it matches a dollar sign. Otherwise it will treat it as an “end-of-line” character, which we will learn about later.
REGEX: \$180 INPUT: $180 MATCH: true
Conversely, putting a \ on certain letters will yield a special character. One of the most common is \s, which will match any whitespace.
REGEX: Lorem\sIpsum INPUT: Lorem Ipsusm MATCH: true
Character ranges
For a given position in a string, we can qualify only a range of characters. To match a string containing a character of 0, 1, or 3 followed by an F, X, or B, we can declare a regular expression with character ranges inside square brackets [].
REGEX: [013][FXB] INPUT: 1X MATCH: true REGEX: [013][FXB] INPUT: 1Z MATCH: false
You can also define a consecutive span of letters or numbers by putting a – between them. We can qualify a character that is any number between 1 through 4 followed by any character that is A through Z.
REGEX: [1-4][A-Z] INPUT: 1X MATCH: true REGEX: [1-4][A-Z] INPUT: 51 MATCH: false
You can also qualify multiple ranges on a single character. For instance, we can qualify the first character in a two-character string to be an uppercase letter, a lowercase letter, or a number.
REGEX: [A-Za-z0-9][0-9] INPUT: i5 MATCH: true REGEX: [A-Za-z0-9][0-9] INPUT: 1X MATCH: false
To negate characters, meaning you want anything but the specified characters, start your character range with a carrot ^. For example, we can qualify non-vowel letters:
REGEX: [^AEIOU] INPUT: X MATCH: true REGEX: [^AEIOU] INPUT: E MATCH: false
If you want a literal dash – character to be part of the character range, declare it first in the range.
REGEX: [-0-9][0-9] INPUT: -9 MATCH: true REGEX: [-0-9][0-9] INPUT: 99 MATCH: true
Anchors
Sometimes you will want to qualify the start ^ and end $ of a line or string. This can be handy if you are searching a document and want to qualify the start or end of a line as part of your regular expression. You can use this regular expression to match all numbers that start a line in a document as shown here:
^[0-9]
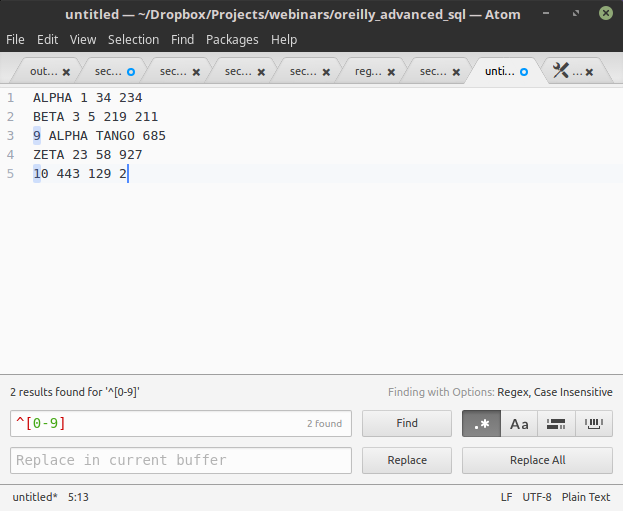
Conversely, an end-of-line $ can be used to qualify the end of a line. Below is a regular expression that will match numbers that are the last character on a line.
[0-9]$
Depending on your environment, using both the start-of-line ^ and end-of-line $ together can be helpful to force a full match and ignore partial ones. This is because qualifying the start ^ and end $ of a string forces everything between them to be the only contents allowed in the input.
REGEX: [0-9][0-9] INPUT: 1432 MATCH: true REGEX: ^[0-9][0-9]$ INPUT: 1432 MATCH: false
Quantifiers
A critical feature of regular expressions is quantifiers, which repeat the preceding clause of a regular expression.
For instance, it is a bit redundant to express [A-Z] three times to match three uppercase letters.
Fixed repetitions
REGEX: [A-Z][A-Z][A-Z] INPUT: YCA MATCH: true
Instead, we can follow the [A-Z] with a quantifier {3} to specify repeating that character range three times, as in [A-Z]{3}. This accomplishes the same task as [A-Z][A-Z][A-Z], but more succinctly expresses it as three repetitions.
REGEX: [A-Z]{3}
INPUT: YCA
MATCH: true
We can use the regular expression below to match a 10-digit phone number with dashes.
REGEX: [0-9]{3}-[0-9]{3}-[0-9]{4}
INPUT: 470-127-7501
MATCH: true
REGEX: [0-9]{3}-[0-9]{3}-[0-9]{4}
INPUT: 75663-2372
MATCH: false
Min and max repetitions
You can also express a minimum and maximum number of allowable repetitions. [A-Z]{2,3} will require a minimum of 2 repetitions but a maximum of 3.
REGEX: [A-Z]{2,3}
INPUT: YCA
MATCH: true
REGEX: [A-Z]{2,3}
INPUT: AZ
MATCH: true
Leaving the second argument empty and having a comma still present will result in an infinite maximum, and therefore specify a minimum. Below, we have a regex that will match on a minimum of two alphanumeric characters.
REGEX: [A-Za-z0-9]{2,}
INPUT: YZ1
MATCH: true
REGEX: [A-Za-z0-9]{2,}
INPUT: YZSDjhfhSBH2342SDFSDFsdfw123412
MATCH: true
0 or 1 repetition (a.k.a., optional)
There are a couple of shorthand symbols for common quantifiers. For instance, a question mark ? is the same as {0,1}, which makes that part of the regex optional. If you wanted two uppercase alphabetic characters to optionally be preceded with a number, you can do so like this:
REGEX: [0-9]?[A-Z]{2}
INPUT: BC
MATCH: true
REGEX: [0-9]?[A-Z]{2}
INPUT: 3BC
MATCH: true
As you start combining different operations, a regular expression can start to look overwhelming. But the secret is to read a regex left-to-right, and looking at the case above you can interpret it as, “I’m looking for a number that is optional, followed by an uppercase alphabetic character repeated two times.”
Taking our phone number example earlier, we can make the dashes now optional as shown here:
REGEX: [0-9]{3}-?[0-9]{3}-?[0-9]{4}
INPUT: 470-127-7501
MATCH: true
REGEX: [0-9]{3}-?[0-9]{3}-?[0-9]{4}
INPUT: 4701277501
MATCH: true
1 or more repetitions
A + is a shorthand for {1,}, which requires a minimum of 1 repetition, but will capture any number of repetitions after that.
REGEX: [XYZ]+ INPUT: Z MATCH: true REGEX: [XYZ]+ INPUT: XYZZZYZXXX MATCH: true REGEX: [XYZ]+[0-9]+ INPUT: XYZZZYZXXX2374676128963453452990 MATCH: true
0 or more repetitions
A * is a shorthand for {0,}, which makes whatever it is quantifying completely optional, but will capture as many repetitions it can if they do exist.
REGEX: [0-3]+[XYZ]* INPUT: 34 MATCH: true REGEX: [0-3]+[XYZ]* INPUT: 34YYXZZ MATCH: true
Wildcards
A dot . is a wildcard for any character, making it the broadest operator you can use. It will match not just alphabetic or numeric characters, but also whitespaces, newlines, punctuation, and any other symbols.
REGEX: ...
INPUT: B/C
MATCH: true
REGEX: .{3}
INPUT: B/C
MATCH: true
REGEX: H.{3}O
INPUT: HELLO
MATCH: true
A common operation you may see is .*, which allows 0 or more repetitions of any character. This is often used to match any text, making it function as an “everything” wildcard. This can be helpful when using regular expressions as qualifiers, and if you do not want that parameter to restrict anything just make it a .*.
REGEX: .* INPUT: AsdfSJDFJSVdsfBLKJXCasdBNVJWB$TJ$@#ASDFSD@ MATCH: true REGEX: .* INPUT: Alpha MATCH: true
Grouping
It can be helpful to group up parts of a regular expression in parentheses, often to use a quantifier on that whole group. For instance, if you want to qualify an uppercase letter followed by three numeric digits, but want to repeat that whole operation with a quantifier, you can do so like this:
REGEX: ([A-Z][0-9]{3})+
INPUT: A563
MATCH: true
REGEX: ([A-Z][0-9]{3})+
INPUT: A563X264
MATCH: true
REGEX: ([A-Z][0-9]{3}-?)+
INPUT: A563-X264-C578
MATCH: true
If we wanted to identify phone numbers (with optional dashes -), but make the area code (the first three digits) optional, we can do so like this:
REGEX: ([0-9]{3}-)?[0-9]{3}-?[0-9]{4}
INPUT: 470-127-7501
MATCH: true
REGEX: ([0-9]{3}-?)?[0-9]{3}-?[0-9]{4}
INPUT: 127-7501
MATCH: true
Alternation
Alternation is expressed with a | and essentially operates as an “OR”. It alternates two or more valid patterns where at least one of those patterns must match in that position.
For instance, if we want to capture 5-digit U.S. ZIP codes that end in “35” or “75,” we can tail a repeated numeric range with a (35|75). We must group that in parentheses so the | does not mangle the 35 with the repeated numeric range.
REGEX: [0-9]{3}(35|75)
INPUT: 75035
MATCH: true
REGEX: [0-9]{3}(35|75)
INPUT: 75062
MATCH: false
Sometimes an alternator is used simply to qualify a set of literal values. For instance, if I want to only match ALPHA, BETA, and GAMMA, I can use an alternator to achieve this.
REGEX: ALPHA|BETA|GAMMA INPUT: BETA MATCH: true REGEX: ALPHA|BETA|GAMMA INPUT: DELTA MATCH: false
Prefixes and suffixes
Especially when you are scanning documents, it can be helpful to qualify something that precedes or follows your targeted text without capturing it. Prefixes and suffixes allow this, and can be leveraged with (?<=regex) and (?=regex) respectively, where “regex” is the pattern for the head or tail you want to qualify but not include.
For instance, if I want to extract numbers that are preceded by uppercase letters, but I don’t want to include those letters, I can use a prefix like this:
REGEX: (?<=[A-Z]+)[0-9]+ INPUT: ALPHA12 MATCH: 12 REGEX: (?<=[A-Z]+)[0-9]+ INPUT: 167 MATCH: false
A suffix works similarly, but matches a tail without including that tail.
REGEX: [0-9]+(?=[A-Z]+) INPUT: 12ALPHA MATCH: 12 REGEX: [0-9]+(?=[A-Z]+) INPUT: 167 MATCH: false
Conclusions
It is important to remember that you often only need to make a regular expression as specific as it needs to be, depending on how predictable your data is. Qualifying a number with [0-9.]+ will work to match an IP address such as 172.18.83.200. But keep in mind it will also match 237476231.345342342334.23423756756856234, which is definitely not an IP address. If you do not know your data well, you should probably err on being more specific, as demonstrated in this Stack Overflow question.
Regular expressions may seem niche, but they can rise up heroically to the most unexpected tasks in your day-to-day work. Hopefully this article has helped you feel more comfortable with regular expressions and find them useful. They can assist in data munging, qualification, categorization, and parsing as well as document editing.