Core technologies and tools for AI, big data, and cloud computing
Highlights and use cases from companies that are building the technologies needed to sustain their use of analytics and machine learning.
 Cubes (source: Pixabay)
Cubes (source: Pixabay)
Profiles of IT executives suggest that many are planning to spend significantly in cloud computing and AI over the next year. This concurs with survey results we plan to release over the next few months. In a forthcoming survey, “Evolving Data Infrastructure,” we found strong interest in machine learning (ML) among respondents across geographic regions. Not only are companies interested in tools, technologies, and people who can advance the use of ML within their organizations, they are beginning to build the core foundational technologies needed to sustain their usage of analytics and ML. With that said, important challenges remain. In other surveys we ran, we found “lack of skilled people,” “lack of data,” and cultural and organizational challenges as the leading obstacles cited for holding back the adoption of machine learning and AI.
In this post, I’ll describe some of the core technologies and tools companies are beginning to evaluate and build. Many companies are just beginning to address the interplay between their suite of AI, big data, and cloud technologies. I’ll also highlight some interesting uses cases and applications of data, analytics, and machine learning. The resource examples I’ll cite will be drawn from the upcoming Strata Data conference in San Francisco, where leading companies and speakers will share their learnings on the topics covered in this post.

Learn faster. Dig deeper. See farther.
AI and machine learning in the enterprise
When asked what holds back the adoption of machine learning and AI, survey respondents for our upcoming report, “Evolving Data Infrastructure,” cited “company culture” and “difficulties in identifying appropriate business use cases” among the leading reasons. Attendees of the Strata Business Summit will have the opportunity to explore these issues through training sessions, tutorials, briefings, and real-world case studies from practitioners and companies. Recent improvements in tools and technologies has meant that techniques like deep learning are now being used to solve common problems, including forecasting, text mining and language understanding, and personalization. We’ve assembled sessions from leading companies, many of which will share case studies of applications of machine learning methods, including multiple presentations involving deep learning:
- Strata Business Summit
- AI and machine learning in the enterprise
- Deep Learning
- Temporal data and time-series analytics
- “Forecasting Financial Time Series with Deep Learning on Azure”
- Text and Language processing and analysis
- Graph technologies and analytics
Foundational data technologies
Machine learning and AI require data—specifically, labeled data for training models. There are many articles that point to the explosion of data, but in order for that data that be useful for analytics and ML, it has to be collected, transported, cleaned, stored, and combined with other data sources. Thus, our surveys have shown that companies tend to apply machine learning and AI in areas where they have prior simpler use cases (business intelligence and analytics) that required data technologies to already be in place. In our upcoming report, “Evolving Data Infrastructure,” respondents indicated they are beginning to build essential components needed to sustain machine learning and AI within their organizations:
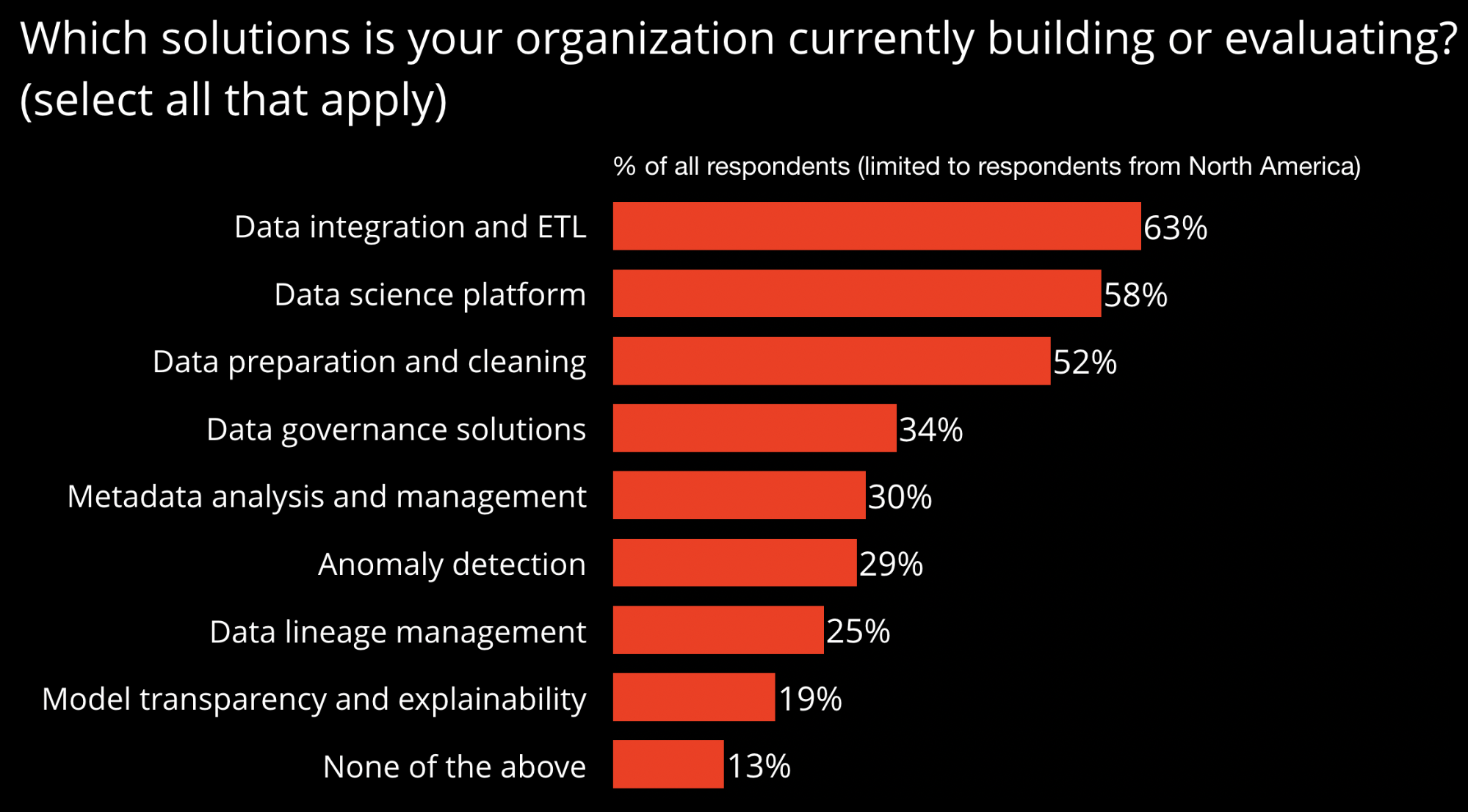
Take data lineage, an increasingly important consideration in an age when machine learning, AI, security, and privacy are critical for companies. At Strata Data San Francisco, Netflix, Intuit, and Lyft will describe internal systems designed to help users understand the evolution of available data resources. As companies ingest and use more data, there are many more users and consumers of that data within their organizations. Data lineage, data catalog, and data governance solutions can increase usage of data systems by enhancing trustworthiness of data. Moving forward, tracking data provenance is going to be important for security, compliance, and for auditing and debugging ML systems.
- Data Platforms
- Data Integration and Data Pipelines
- Model lifecycle management
- Automation in data science and big data
- Data preparation, data governance, and data lineage
- Open Data, Data Generation and Data Networks
Companies are embracing AI and data technologies in the cloud
In the survey behind our upcoming report, “Evolving data infrastructure,” we found 85% of respondents indicated they had data infrastructure in at least one of the seven cloud providers we listed, with two-thirds (63%) using Amazon Web Services (AWS) for some portion of their data infrastructure. We found companies run a mix of open source technologies and managed services, and many respondents indicated they used more than one cloud provider.
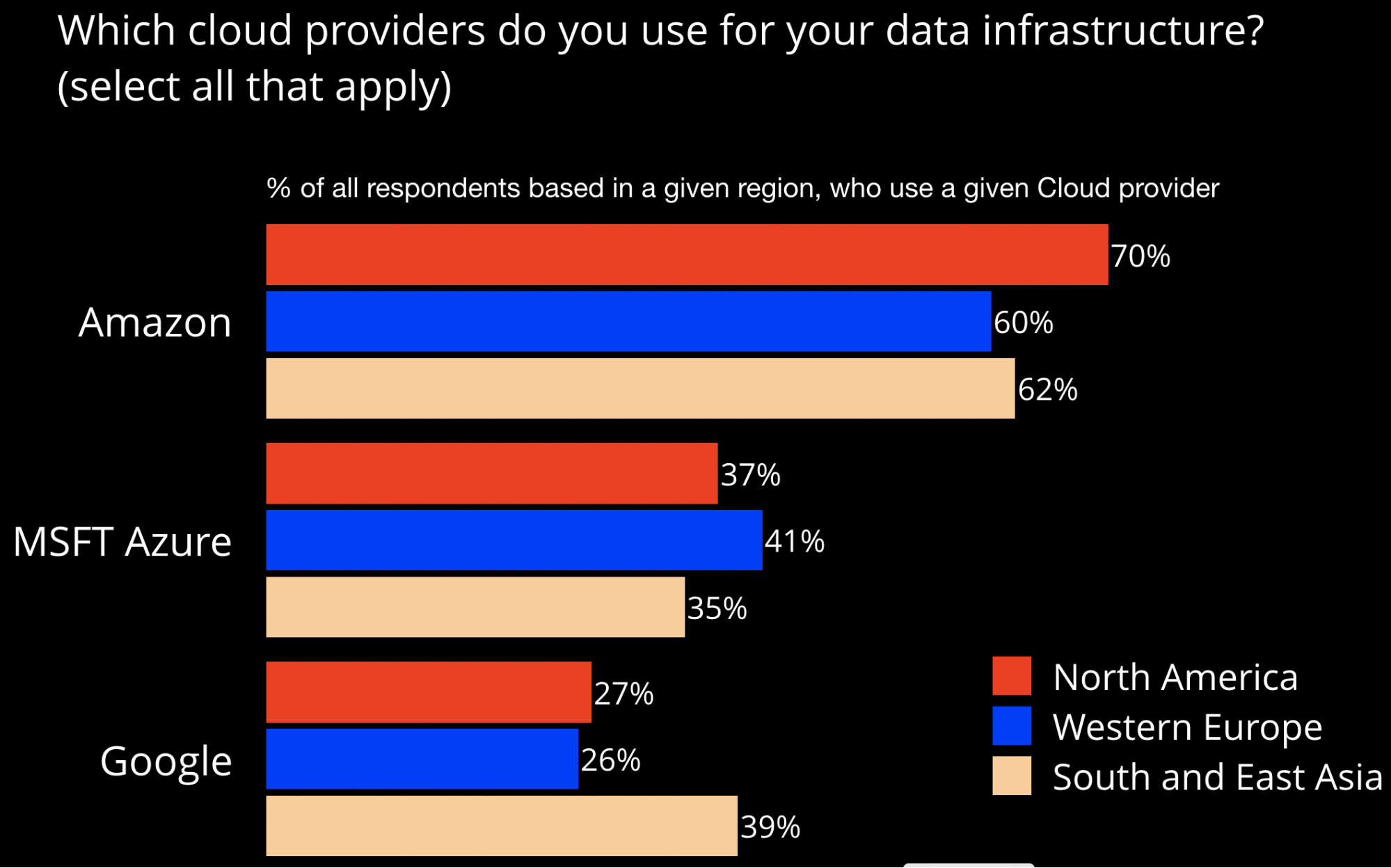
This agrees with other surveys I’ve come across that indicated IT executives plan to invest a significant portion of their budgets in cloud computing resources and services.
- AI and Data technologies in the cloud
- “Building a Serverless Big Data Application on AWS”
- Streaming and realtime analytics
- “Architecture and Algorithms for End-to-End Streaming Data Processing”
- “Running multidisciplinary big data workloads in the cloud”
Security and privacy
Regulations in Europe (GDPR) and California (Consumer Privacy Act) have placed concepts like “user control” and “privacy-by-design” at the forefront for companies wanting to deploy ML. With these new regulations in mind, the research community has stepped up and new privacy-preserving tools and techniques—including differential privacy—are becoming available for both business intelligence and ML applications. Strata Data San Francisco will feature sessions on important topics including: data security and data privacy; the use of data, analytics, and ML in (cyber)security; privacy-preserving analytics ; and secure machine learning.
- Security and Privacy
- “Manage the Risks of ML – In Practice”
- “Machine Learning on Encrypted Data: Challenges and Opportunities”
- “Framework to quantitatively assess ML Safety – Technical Implementation & Best Practices”
Ethics
When it come to ethics, it’s fair to say the data community (and the broader technology community) is very engaged. As I noted in an earlier post, the next-generation data scientists and data engineers are undergoing training and engaging in discussions pertaining to ethics. Many universities are offering courses; some like UC Berkeley have multiple courses. We’re at the point where companies are beginning to formulate and share some best practices and processes. We are pleased to announce that we have a slate of tutorials and sessions—and a full day of presentations dedicated to ethics—at the upcoming Strata Data conference in San Francisco.
- Ethics
- Strata Data Ethics Summit – a day of presentations from leading experts and practitioners
- “The Measure and Mismeasure of Fairness in Machine Learning”
Use cases and solutions
Data, machine learning, and AI are impacting companies across industries and geographic locations. Companies are beginning to build key components including solutions that address data lineage and data governance, as well as tools that can increase the productivity of their data scientists (“data science platforms”). Many technologies and techniques are general purpose and cut across domains and industries. However, there are tools and methods that are used more heavily in certain verticals, and more importantly, we all like learning what our industry peers have been building and thinking about. Here are some related talks from a few verticals: