Drinking from the industrial IoT data fire hose
Careful choices in data collection and architecture can reduce burdens.
Behind the immense promise offered by the Internet of Things (IoT) lies serious challenges for system and network administrators who have to transmit and store the equally immense quantities of data that will be generated by edge devices and for programmers who have to process that data. These challenges are unprecedented, even in the context of the enormous growth of data during the digital age.
Many people felt the stress of “data overload” in the 1990s when they had to read 50 email messages a day. By the year 2000, we were talking about the overwhelming size of the Web, when it offered an estimated seven million sites. During that time, new words were invented to refer to the exploding data sizes, and I suggested (tongue in cheek) that the size of corporate data is outgrowing the availability of Greek prefixes. In 2013, Cisco estimated “the number of connected objects to reach ~50 billion in 2020.” A typical example of modern IoT volume involves 2.5 terabytes of data per day from 6,000 sensors on a single machine. You can check a ZDNet article for more statistics inducing data vertigo.

Learn faster. Dig deeper. See farther.
It’s far from hopeless, though. I’ve written up a primer on ways you can sop up the output from these data fire hoses to gain value and actionable insight from the data. Let’s look at some basic considerations that lie behind your use of IoT data.
Look for value
Managers and financial planners will want to know what value will be derived from sensors and big data. Ample uses can be reported from numerous fields:
- Shell Oil uses seismic sensors and artificial intelligence to find new sources of fuel, while renewable energy companies combine on-site data with weather forecasts to improve decisions about locating and building facilities.
- The OnFarm company integrates data from multiple sensors, such as crops, winds, and moisture through ThingWorx and combines the results into agricultural applications.
- The All Traffic Solutions company crunches data about traffic and creates visualizations for safety and other applications using ThingWorx.
These examples could be multiplied over many fields and industries. The question is how your organization can use data. What markets would you like to enter? Where are your current products or operations inefficient? What information would help you make such decisions? And are you ready to invest the human resources and money to create major changes in your organization based on the incoming information? If you have satisfactory answers to these questions, you can move to the next step.
Determine what you need to learn from data
Through machine learning, data scientists have turned up fascinating insights that traditional techniques would never have yielded. Dazzled by such results, some web sites collect everything that comes their way, storing huge amounts of raw historical data. Some of the decisions driven by this data have to be made instantly (notably, which ads to present to a visitor), whereas other analytics can be processed at the sites’ leisure.
The Internet of Things is different; although, here too one has decisions that must be made quickly (such as whether to shut down an overheating engine), and others can use historical data to draw long-range conclusions. One difference, as we have seen, is the great quantity of data that edge devices can generate. Another difference is that the IoT has a potentially infinite amount of information to offer. It all depends on which sensors you install, and how many.
So, your organization needs to decide what it has to learn from its environment, and choose sensors wisely. One key decision is granularity. Can you get by with one sensor at one end of a pipe, or do you need sensors at regular intervals? Can a farmer draw useful conclusions from one sensor on a field, or does she need a sensor for each row of plants? These are engineering questions.
Determine which proxies to use
Rarely can you extract the exact answer to your questions from your environment. For instance, few planets from other solar systems can be detected through direct observation, so NASA uses four other methods for finding planets, such as watching for wobble in the stars themselves or in the light that comes from them. Similarly, a common question in manufacturing would be, “How long will this enclosure last?” But you can’t get a timetable directly from the enclosure. You need instead to monitor for cracks, a thinning of the shell, or other proxy measures.
Determine where to process data
The simplest architecture for data processing is to slurp everything into a central data store, probably on a cloud facility, and run large-scale analytics there. But, burdens on your storage and networking can be reduced by processing some data close to where it is gathered.
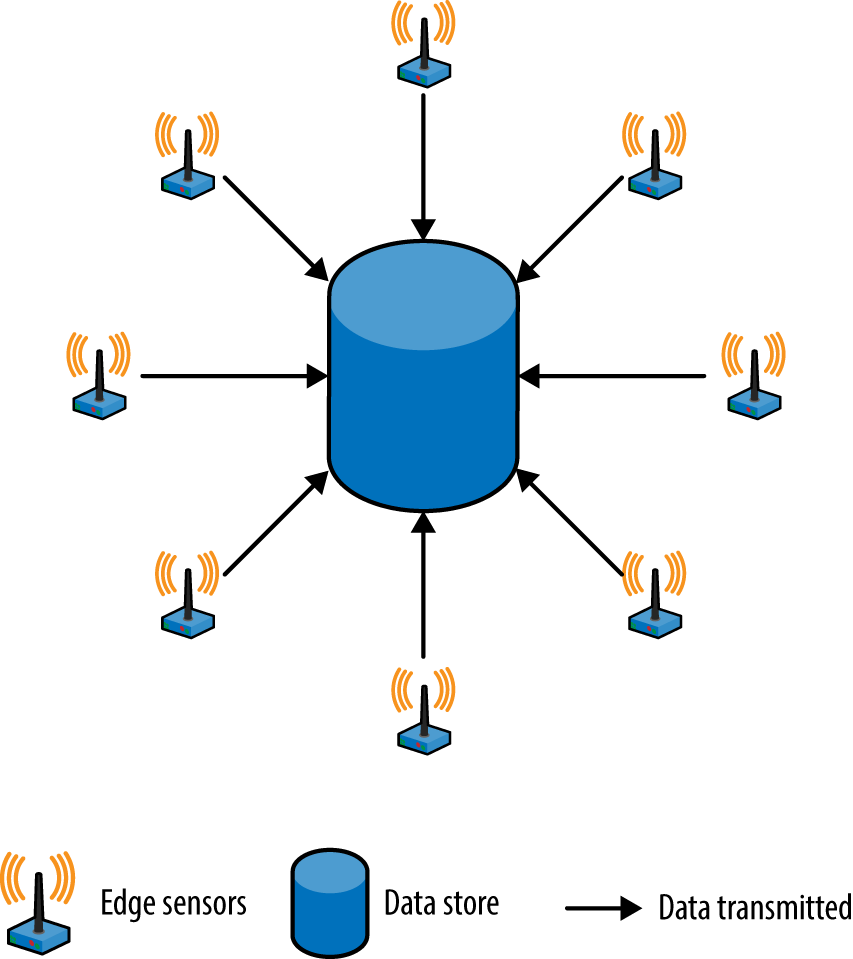
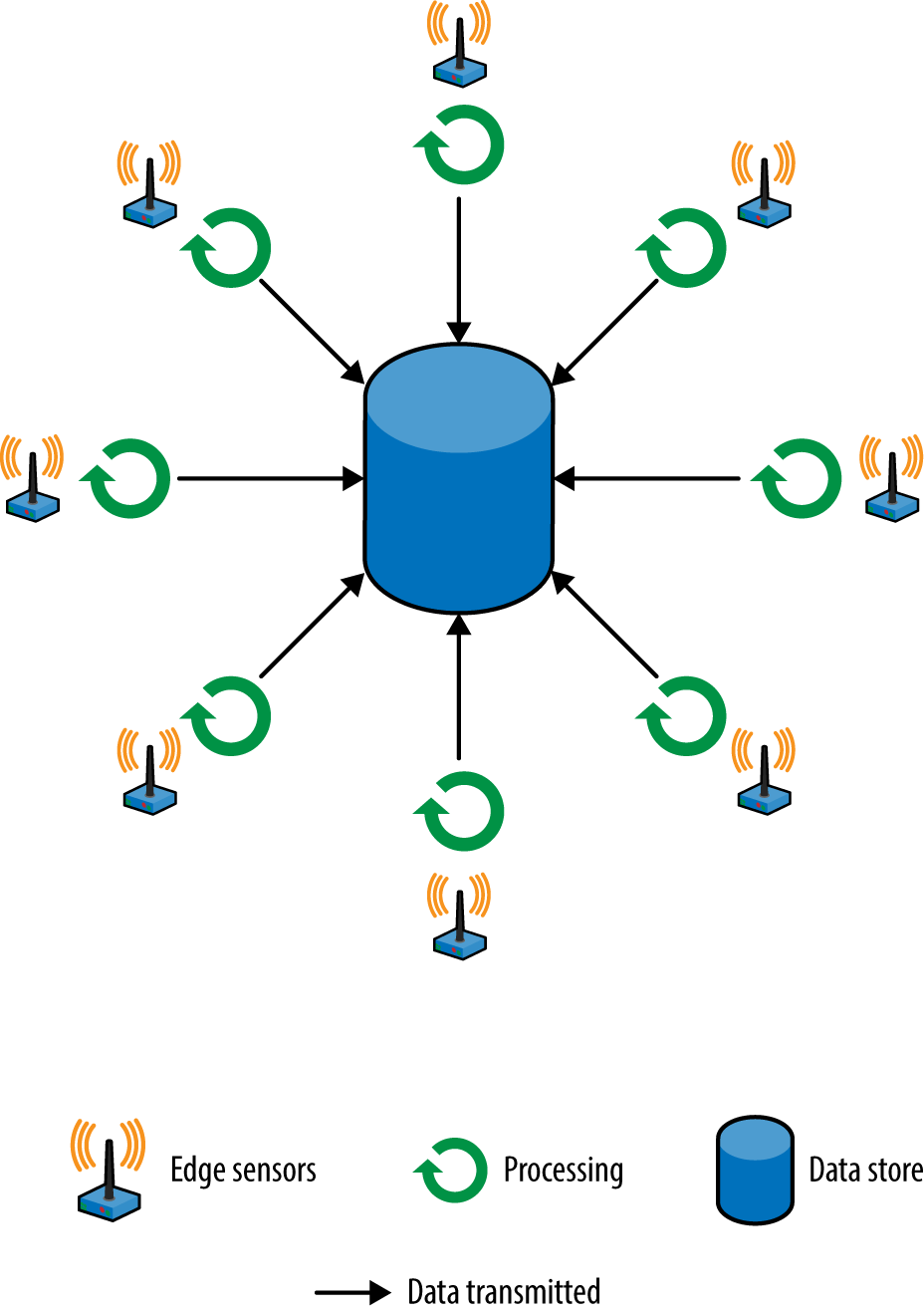
A typical example of processing at the edge is monitoring the values generated by a device to look for anomalies. For instance, an electrocardiogram could check for spikes or drops in the heartbeat and send an alert to the central service only for irregularities. Another option is to send the average of values collected once a second or once a minute, instead of all the raw values.
Another common IoT architecture is for devices at each geographical site to send data to a local hub, generally over a local wireless network. The local hub can partially process the data and send results over the internet to a centralized store that combines data from many sites.
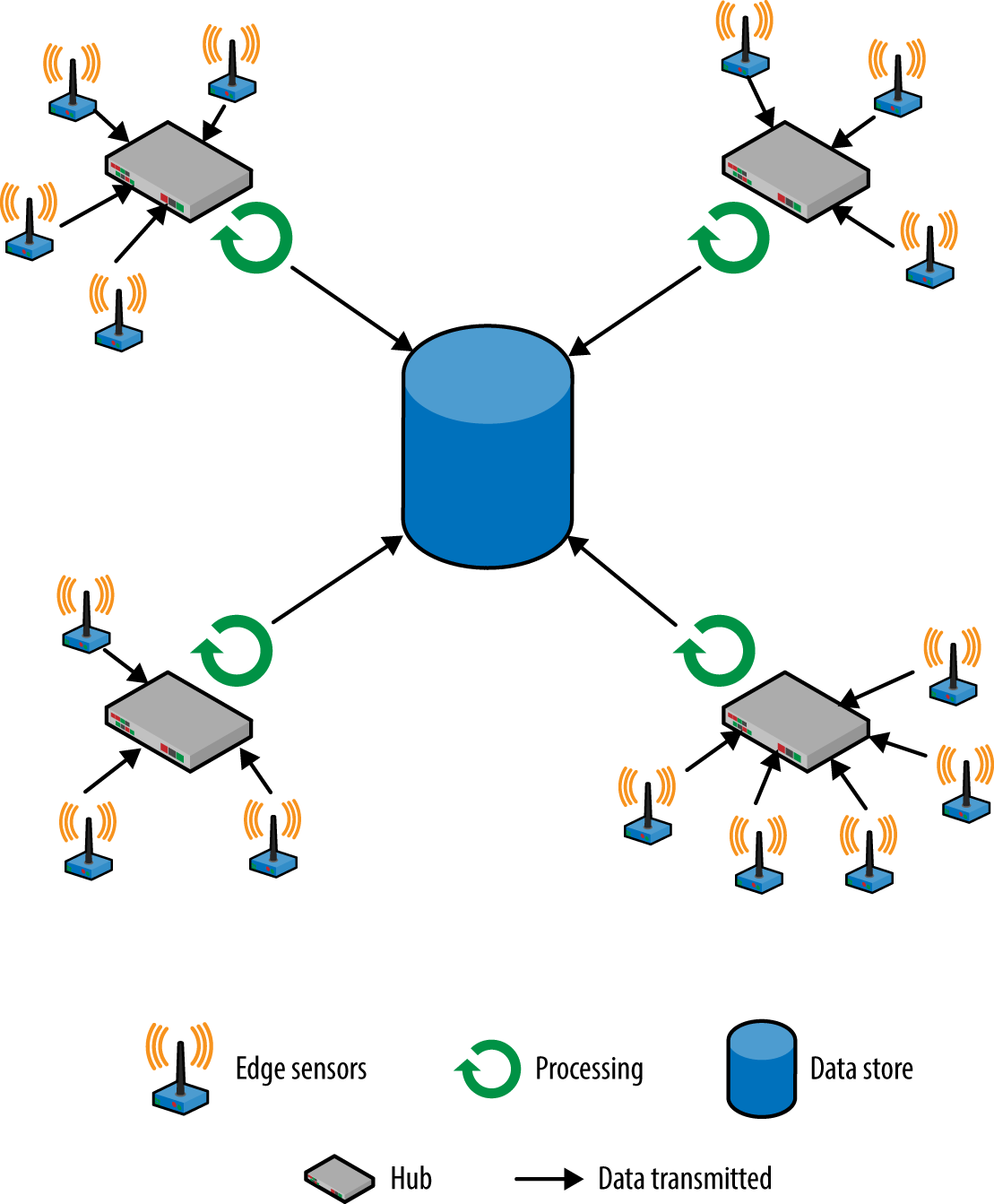
The decisions about where to process data depend on several factors:
- Can useful insights be generated from the data at a single device or a single site, or do analytics require combined data from a large number of devices?
- Do the edge devices have sufficient CPU power, data storage, and energy sources to do the processing?
- Does your network have the bandwidth to transmit the data?
- Do you want to preserve the data for future processing?
- How quickly do you need results? Urgent changes to data that require real-time action are more likely to take place in a timely manner if they are processed close to the edge.
- How sensitive are your analytics to missing data? Edge devices are liable to fail or to stop reporting data for other reasons.
These are some of the considerations for data handling in IoT applications. Read my report, Scaling Data Science for the Industrial Internet: Advanced Analytics in Real Time, for more insights and guidance.
This post is a collaboration between ThingWorx and O’Reilly. See our statement of editorial independence.