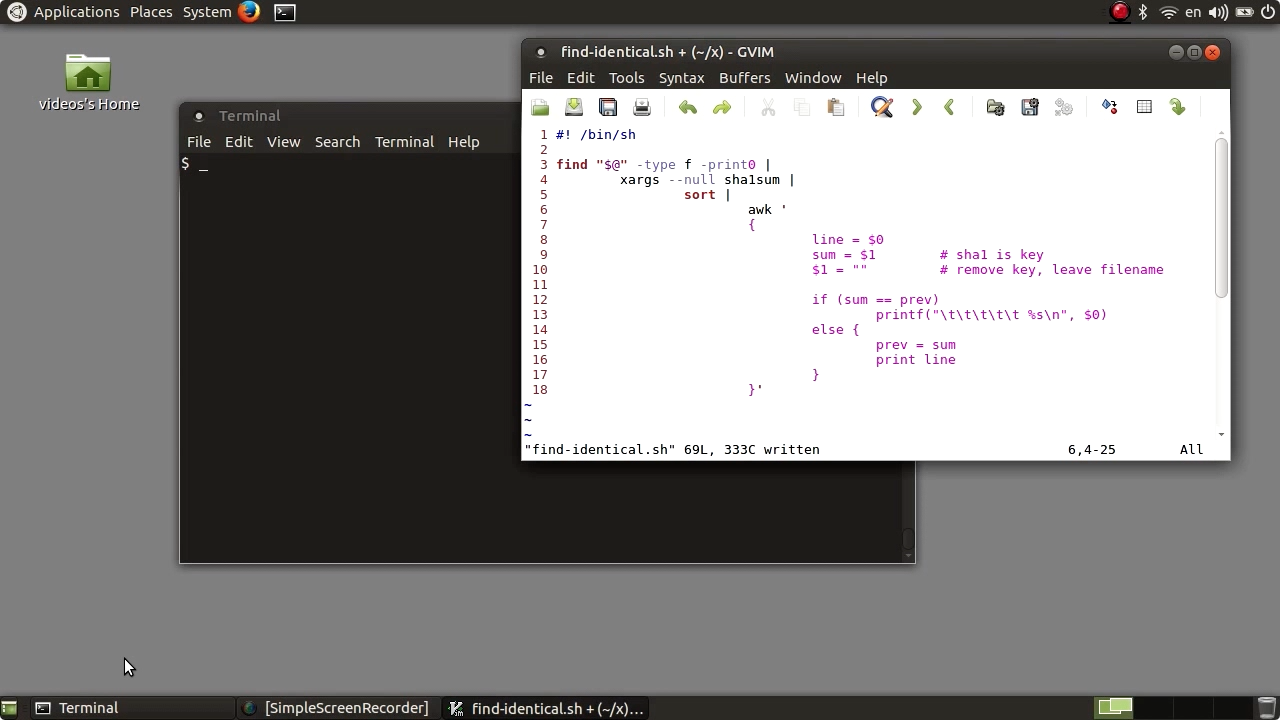
 Screen from "How can I find duplicate files in Linux?" (source: O'Reilly)
Screen from "How can I find duplicate files in Linux?" (source: O'Reilly) Over the years, any Linux user will tend to collect multiple copies of files in their system. This could be from from unpacking distributions in different areas, copying files for safekeeping, or any number of other reasons. In this training video Arnold Robbins shows you how to clean up your system. He will walk you through a file tree to identify duplicate files by:
Using the find command to walk a directory tree.
Actioning the results with xargs.
Sorting, and then printing the duplicate files found.
All of this is accomplished using a simple 20-line shell script; and is explained in a way that any level of Linux user can understand and replicate.
Get in-depth shell scripting training from Arnold Robbins.
Arnold Robbins is a professional software engineer who has worked with UNIX systems since 1980. The author of more than a dozen O’Reilly titles, including Linux in a Nutshell, Effective awk Programming, and the Bash Pocket Reference, Arnold is a master communicator who holds a BA in Information Science from Yeshiva University and an MS in Computer and Information Science from Georgia Tech.