“Not hotdog” vs. mission-critical AI applications for the enterprise
Drawing parallels and distinctions around neural networks, data sets, and hardware.
 Parallel melt pools and ice floes (source: NOAA on Flickr)
Parallel melt pools and ice floes (source: NOAA on Flickr)
Artificial intelligence has come a long way since the concept was introduced in the 1950s. Until recently, the technology had an aura of intrigue, and many believed its place was strictly inside research labs and science fiction novels. Today, however, the technology has become very approachable. The popular TV show Silicon Valley recently featured an app called “Not Hotdog,” based on cutting-edge machine learning frameworks, showcasing how easy it is to create a deep learning application.
Gartner has named applied AI and machine-learning-powered intelligent applications as the top strategic technology trend for 2017, and reports that by 2020, 20% of companies will dedicate resources to AI. CIOs are under serious pressure to commit resources to AI and machine learning. It is becoming easier to build an AI app like Not Hotdog for fun and experimentation, but what does it take to build a mission-critical AI application that a CIO can trust to help run a business? Let’s take a look.

Learn faster. Dig deeper. See farther.
For the purpose of this discussion, we will limit our focus to applications similar to Not Hotdog, (i.e., applications based on image recognition and classification), although the concepts can be applied to a wide variety of deep learning applications. We will also limit the discussion to systems and frameworks, because personnel requirements can vary significantly based on the application. For example, for an image classification application built for retinal image classification, Google required the assistance of 54 ophthalmologists. Whereas for an application built for recognizing dangerous driving, we are going to require significantly less expertise and fewer people.
Image classification: Widely applicable deep learning use case
At its core, Not Hotdog is an image classification application. It classifies images into two categories: “hotdogs” and “not hotdogs.”

Image classification has many applications across industries. In health care, it can be used for medical imaging and diagnosing diseases. In retail, it can be used to spot malicious activities in stores. In agriculture, it can be used to determine the health of crops. In consumer electronics, it can provide face recognition and autofocus to camera-enabled devices. In the public sector, it can be used to identify dangerous driving with traffic cameras. The list goes on. The fundamental difference between these applications and Not Hotdog is the core purpose of the application. Not Hotdog is intentionally meant to be farcical. As a result, it is an experimental app. However, the applications listed above are meant to be critical to core business processes. Let’s take a look at how “Not Hotdog” is built, and then we will discuss additional requirements for mission-critical deep learning applications.
Not Hotdog: How is it built?
This blog takes us through the wonderful journey of Not Hotdog’s development process. Following is the summary of how it is built.
Not Hotdog uses the following key software components:
- React Native: An app development framework that makes it easy to build mobile apps.
- TensorFlow: An open source software library for machine learning. It makes building deep learning neural networks easy with pre-built libraries.
- Keras: An open source neural network library written in Python. It is capable of running on top of TensorFlow and other machine learning libraries. It presents higher-level abstractions that make it easy to configure neural networks.
The following deep neural networks were considered:
- Inception model: The Inception v3 model is a deep convolutional neural network pre-trained with Google’s ImageNet data set of 14 million images. It gives us a pre-trained image classification model. The model needs “re-training” for specific tasks, but overall, it makes it really easy to build an image classification neural network. This was abandoned due to imbalance in training data and the massive size of the model.
- SqueezeNet: A distributed deep neural network for image classification. Primary benefits over the Inception model are that it requires 1/10th of the parameters, it is much faster to train, and the resulting model is much smaller and faster (it often requires 1/10th of the memory). SqueezeNet also has a pre-trained Keras model, making it easier to retrain for specific requirements. SqueezeNet was abandoned due to accuracy concerns.
- MobileNets (the chosen one): Efficient convolutional neural networks for mobile vision applications. It helps create efficient image classification models for mobile and embedded vision applications. The Not Hotdog team ended up choosing this neural network after strongly considering the two above.
The Not Hotdog team used an extremely economical hardware setup:
- Laptop (yes, a single laptop!): 2015 MacBook Pro (used for training).
- GPU: Nvidia GTX 980 Ti, attached to the laptop (used for training).
- Users’ phones: For running the model. This is a simple example of edge computing where computing happens right at the edge, without relying on a “server.”
And leveraged the following data set:
The training data set consisted of 150K images. Three thousand images were hotdogs, while 147K images were not hotdogs. During model training, these images were processed 240 times, which took 80 hours on the very modest hardware setup. The final model was trained only once. There was no feedback loop for retraining the model for incremental improvements.
Mission-critical AI: Drawing parallels with Not Hotdog
Based on the information above, let’s use a similar construct to understand the requirements for creating AI-enabled core business applications.
The Not Hotdog team selected React Native, which falls under the category of cross-platform native mobile application frameworks. If you are building a mobile app, it is a good idea to investigate this category. Native frameworks provide the flexibility of cross-platform frameworks, at the same time removing unnecessary components (i.e., the mobile browser) from the architecture. As a result, the applications run smoother and faster. A downside of native frameworks is a limited feature set. If you are building a mission-critical web application powered by AI, there are plenty of battle-tested frameworks — such as Django, Ruby on Rails, Angular, React — for back-end and front-end development. One attribute to always check for is the integration with your chosen deep learning libraries.
Another key software component selected by the Not Hotdog team was Keras running on top of TensorFlow. Keras, as mentioned above, is capable of running on top of TensorFlow, CNTK, or Theano. Keras focuses on enabling fast experimentation. One can think of Keras as a better UX for TensorFlow, enabling efficient development of models. Keras also provides the flexibility of choosing the desired deep learning library underneath. Bottomline: Keras provides a better developer experience. However, there are many other deep learning libraries available.
Choosing the right deep neural network for image classification
The Not Hotdog team ended up selecting MobileNets after significant experimentation with Inception model v3 and SqueezeNet. There are a number of deep neural networks available to choose from if you are building an AI-enabled application. More information can be found in the research paper by Alfredo Canziani, Eugenio Culurciello, Adam Paszke, “An Analysis of Deep Neural Network Models for Practical Applications.” If you are planning to build an AI application that utilizes image classification, this paper is a must read—it contains interesting figures that offer a high-level indication about the computing resources required by each neural network, number of parameters used by each neural network, and accuracy-per-parameter (a measure of efficiency) for each neural network.
Key considerations for choosing the deep neural network include: accuracy, number of parameters, processing times for the training set and input images, resulting model size, availability of the pre-trained neural network with the library of choice, and memory utilization. The optimal neural network will depend on your use case. It is a good idea to test a few different neural networks to see which one meets expectations.
Data sets—quantity and quality matters
There are many considerations for data sets to use as you build and deploy your AI application.
- Training data: A model is only as good as the data it is trained on. For mission-critical AI applications, accuracy is much more important than Not Hotdog. The implications of failing to recognize skin cancer are far more serious. As a result, we are going to require data sets that are significantly greater in quantity and quality. The Not Hotdog team trained their model using 150K images. It is likely that we will require data sets much larger to achieve the desired accuracy. Also, the quality of the data is equally important, which means we may have to spend significant time preparing and labeling the data.
- Input data: The input data for prediction using our trained model can also exponentially exceed the amount of data Not Hotdog has to process. Imagine a live camera feed from tens of cameras in a store. We may have to process thousands of images per minute to detect malicious activities. A retail chain may have thousands of outlets. We are talking about around a million images per minute! It is exponentially larger compared to Not Hotdog, which may have to process a few images per minute, for which it uses the mobile device of its users.
- Feedback loop: It is a great idea to provide a feedback loop to improve the model. In the retail store example, if we found false positive or false negative predictions, it would be a good idea to label them and feed them back into the model to retrain it. A continuous feedback loop means the training data size increases significantly over time, and the compute requirements are also significant as we train the model multiple times using additional data.
Hardware setup for production-ready AI applications
The hardware used for running mission-critical applications will depend on SLAs and the massive differences in data set sizes:
- Storage: It is highly unlikely our data set will fit on the disk of a laptop. We will require a number of SSDs and/or HDDs to store the ever-increasing training data.
- Compute (training): It is extremely likely we will need a cluster of GPUs to train a model with a training data set consisting of millions of images.
- Compute (running the model/application): Once a model is trained, depending on size and performance of the model, number of input images, and business SLA expected from the application, we are going to need a cluster of GPUs to meet the application requirements.
Mission-critical AI: Key differentiators from Not Hotdog
The key differences between a mission-critical AI application and Not Hotdog are accuracy, SLAs, scale, and security:
- Accuracy: Mission-critical AI applications will need significantly better accuracy. This means the training data needs to be greater in quality and quantity.
- SLAs: Besides accuracy, an application used for core business processes will have strict SLAs. For example, when an image is fed to a model for prediction, the model should not take more than one second to predict the output. The architecture has to be scalable to accommodate the SLAs.
- Scale: High-accuracy expectation and strict SLAs mean we need an architecture that can effortlessly scale-out, for both compute and storage.
- Security: Certain applications present security and data privacy concerns. The data may include sensitive information and has to be stored securely with enterprise-grade security features to make sure only authorized users have access to the information.
Architectural considerations for mission-critical AI: Distributed computing and storage
To meet the accuracy and SLA requirements, consideration should be made for an architecture that can easily scale-out, for both compute and storage. Distributed computing-based big data platforms may present a viable architecture, summarized below, for scaling AI to meet business requirements.
Distributed storage: Big data stores built using a distributed files system, such as the MapR Converged Data Platform and Apache Hadoop, can provide a scalable and economical storage layer to store millions of images.
Distributed compute: Containerization is a viable architecture for enabling mission-critical AI using distributed computing. Harnessing the models, metadata, and dependencies into Docker containers allows us to scale when needed by deploying additional container images.
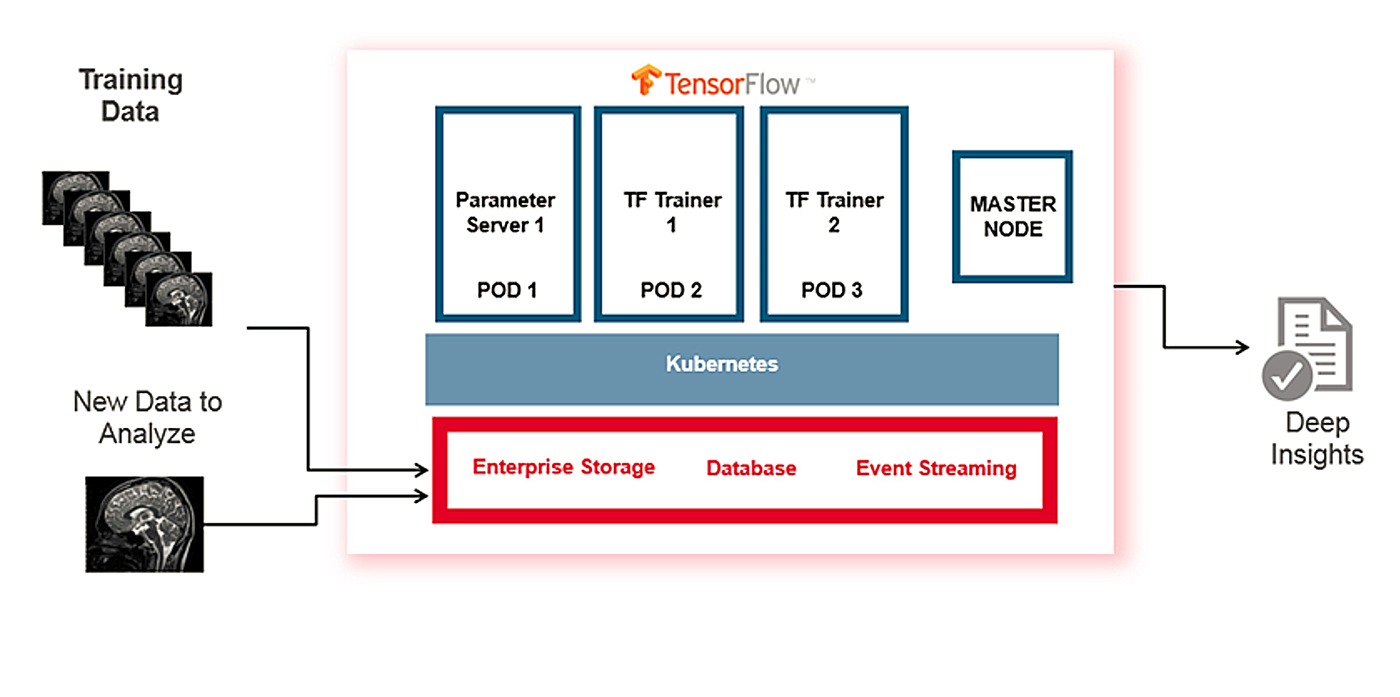
Three-tier architecture for distributed deep learning: In this blog, a three-layer architecture for distributed deep learning is discussed. The bottom layer is the data layer, where data will be stored. The middle layer is the orchestration layer, such as Kubernetes. The top layer is the application layer, where TensorFlow can be used as the deep learning tool. We can containerize the trained model into a Docker image with metadata as image tags to keep the model version information, and all the dependencies/libraries should be included install-free in the container image. Figure 2 represents this example three-tier architecture for deep learning.
Summary
The Not Hotdog team generously allowed us to take a look at their application journey. We can draw parallels to the application and its components and extend the concepts to mission-critical AI applications. However, there are key differences we need to consider—namely, accuracy, scale, strict SLAs, and security. To meet these requirements, we need to consider a distributed deep learning architecture.