Why a data scientist is not a data engineer
Or, why science and engineering are still different disciplines.
 Comparing apples and oranges (source: frankieleon on Flickr)
Comparing apples and oranges (source: frankieleon on Flickr)
“A scientist can discover a new star, but he cannot make one. He would have to ask an engineer to do it for him.”
–Gordon Lindsay Glegg, The Design of Design (1969)

Learn faster. Dig deeper. See farther.
A few months ago, I wrote about the differences between data engineers and data scientists. I talked about their skills and common starting points.
An interesting thing happened: the data scientists started pushing back, arguing that they are, in fact, as skilled as data engineers at data engineering. That was interesting because the data engineers didn’t push back saying they’re data scientists.
So, I’ve spent the past few months gathering data and observing the behaviors of data scientists in their natural habitat. This post will offer more information about why a data scientist is not a data engineer.
Why does this even matter?
Some people complained that this data scientist versus data engineer is a mere focus on titles. “Titles shouldn’t hold people back from learning or doing new things,” they argued. I agree; learn as much as you can. Just know that your learning may only scratch the surface of what’s necessary to put something in production. Otherwise, this leads to failure with big data projects.
It’s also feeding into the management level at companies. They’re hiring data scientists expecting them to be data engineers.
I’ve heard this same story from a number of companies. They all play out the same: a company decides that data science is the way to get VC money, tons of ROI, mad street cred in their business circle, or some other reasons. This decision happens at C-level or VP-level. Let’s call this C-level person Alice.
The company goes on an exhaustive search to find the best data scientist ever. Let’s call this data scientist Bob.
It’s Bob’s first day. Alice comes up to Bob and excitedly tells him about all the projects she has in mind.
“That’s great. Where are these data pipelines and where is your Spark cluster?” Bob asks.
Alice responds, “That’s what we’re expecting you to do. We hired you to do data science.”
“I don’t know how to do any of that,” says Bob.
Alice looks at him quizzically, “But you’re a data scientist. Right? This is what you do.”
“No, I use the data pipelines and data products that are already created.”
Alice goes back to her office to figure out what happened. She stares at overly simplistic diagrams like the one shown in Figure 1 and can’t figure out why Bob can’t do the simple big data tasks.
The limelight
There are two questions that come out of these interactions:
- Why doesn’t management understand that data scientists aren’t data engineers?
- Why do some data scientists think they’re data engineers?
I’ll start with the management side. Later on, we’ll talk about the data scientists themselves.
Let’s face it. Data engineering is not in the limelight. It isn’t being proclaimed as the best job of the 21st century. It isn’t getting all of the media buzz. Conferences aren’t telling CxOs about the virtues of data engineering. If you only look at the cursory message, it’s all about data science and hiring data scientists.
This is starting to change. We have conferences on data engineering. There is a gradual recognition of the need for data engineering. I’m hoping pieces like this one shed light on this necessity. I’m hoping my body of work will educate organizations on this critical need.
Recognition and appreciation
Even when organizations have data science and data engineering teams, there is still a lack of appreciation for the work that went into the data engineering side.
You even see this lack of credit during conference talks. The data scientist is talking about what they’ve created. I can see the extensive data engineering that went into their model, but it’s never called out during the talk. I don’t expect the talk to cover it in detail, but it would be nice to acknowledge the work that went into enabling their creation. Management and beginners to data science perceive that everything was possible with the data scientist’s skill set.
How to get appreciation
Lately, I’ve been getting questions from data engineers on how to get into their company’s limelight. They’re feeling that when a data scientist goes to show their latest creation, they’re either taking all of the credit or they’re given all of the credit by the management. Their basic question is: “How can I get the data scientists to stop taking credit for something that was both of our work?”
That’s a valid question from what I’m seeing at companies. Management doesn’t realize (and it isn’t socialized) the data engineering work that goes into all things data science. If you’re reading this and you’re thinking:
- My data scientists are data engineers
- My data scientists are creating really complicated data pipelines
- Jesse must not know what he’s talking about
…you probably have a data engineer in the background who isn’t getting any limelight.
Similar to when data scientists quit without a data engineer, data engineers who don’t get recognition and appreciation will quit. Don’t kid yourself; there’s an equally hot job market for qualified data engineers as there is for data scientists.
Data science only happens with a little help from our friends

You might have heard about the myth of Atlas. He was punished by having to hold up the world/sky/celestial spheres. The earth only exists in its current form because Atlas holds it up.
In a similar way, data engineers hold up the world of data science. There isn’t much thought or credit that goes to the person holding up the world, but there should be. All levels of an organization should understand that data science is only enabled through the work of the data engineering team.
Data scientists aren’t data engineers
That brings us to why data scientists think they’re data engineers.
A few caveats to head off comments before we continue:
- I think data scientists are really smart, and I enjoy working with them.
- I’m wondering if this intelligence causes a higher IQ Dunning-Kruger effect.
- Some of the best data engineers I’ve known have been data scientists, though this number is very small.
- There is a consistent overestimation when assessing our own skills.
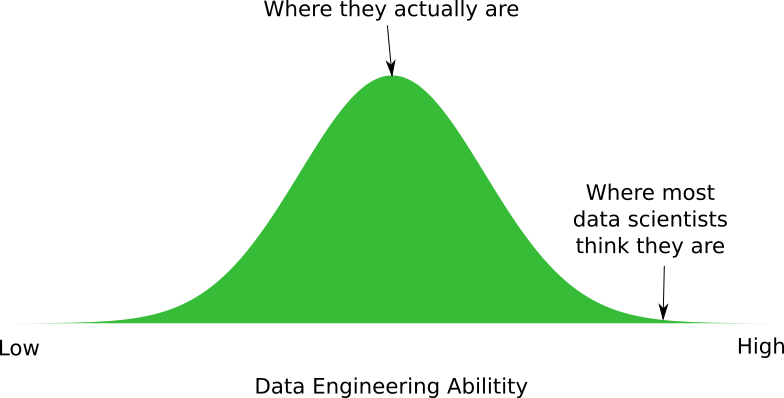
In talking to data scientists about their data engineering skills, I’ve found their self-assessments to vary wildly. It’s an interesting social experiment in biases. Most data scientists over assessed their own data engineering abilities. Some gave an accurate assessment, but none of them gave a lower assessment than their actual ability.
There are two things missing from this diagram:
- What is the skill level of data engineers?
- What is the skill level needed for a moderately complicated data pipeline?
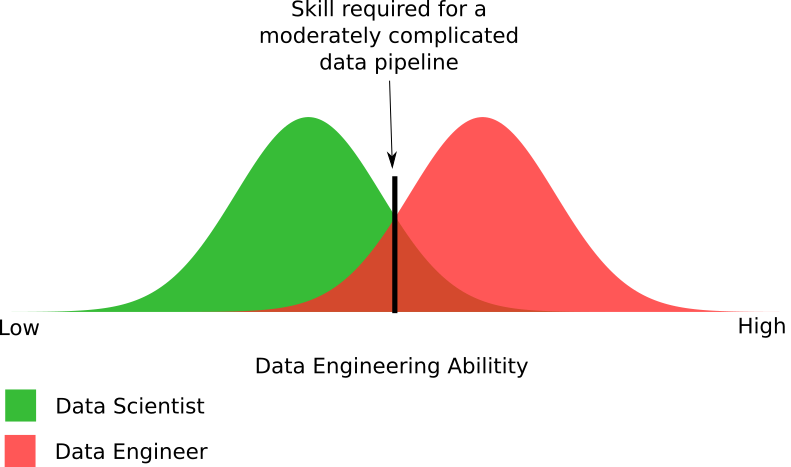
From this figure, you can start to see the differences in the required data engineering abilities. In fact, I’m being more generous with the number of data scientists able to create a moderately complicated data pipeline. The reality may be that data scientists should be half of what the diagram shows.
Overall, it shows the approximate portions of the two groups who can and cannot create data pipelines. Yes, some data engineers can’t create a moderately complicated data pipeline. Conversely, most data scientists can’t, either. This comes back to the business issue at hand: organizations are giving their big data projects to individuals who lack the ability to succeed with the project.
You might think, “Good, so 20% of my data scientists can actually do this. I don’t need a data engineer after all.” First, remember this chart is being charitable in showing data scientists’ abilities. Remember that moderately complicated is still a pretty low bar. I need to create another diagram to show how few data scientists can handle the next step up in complexity. This is where the percentage drops to 1% or less of data scientists.
Why aren’t data scientists data engineers?
Sometimes I prefer to see the reflected manifestations of problems. These are a few examples of the manisted problems that make data scientists lack the data engineering skill set.
University and other courses
Data science is the hot new course out there for universities and online courses. There are all sorts of offerings out there, but virtually all of them have the same problem: they either completely lack or have one data engineering class.
When I see a new university’s data science curriculum announced, I take a look at it. Sometimes, I’ll be asked for comments on a university’s proposed data science curriculum. I give them same feedback: “Are you expecting expert programmers? Because there isn’t any coverage of the programming or systems required to even consume a data pipeline that’s been created.”
The course outlines generally focus on the statistics and math required. This reflects what companies and academics think data science should look like. The real world looks rather different. The poor students are left to fend for themselves for the rest of these non-trivial learnings.
We can take a step back and look at this academically by looking at course requirements for a master’s degree in distributed systems. Obviously, a data scientist doesn’t need this level of depth, but it helps show what’s missing and the big holes in a data scientist’s skill set. There are some major deficiencies.
Data engineering != Spark
A common misconception from data scientists—and management—is that data engineering is just writing some Spark code to process a file. Spark is a good solution for batch compute, but it isn’t the only technology you’ll need. A big data solution will require 10-30 different technologies all working together.
This sort of thinking lies at the heart of big data failures. Management thinks they have a new silver bullet to kill all of their big data problems. The reality is far more complicated than that.
When I mentor an organization on big data, I check for this misconception at all layers of the organization. If it does exist, I make sure I talk about all of the technologies they’ll need. This removes the misconception that there’s an easy button in big data and there’s a single technology to solve all of it.
Where is the code from?
Sometimes data scientists will tell me how easy data engineering is. I’ll get them to tell me how and why they think that. “I can get all the code I need from StackOverflow or Reddit. If I need to create something from scratch, I can copy someone’s design in a conference talk or a whitepaper.
To the non-engineer, this might seem OK. To the engineer, this starts major alarm bells. The legal issues aside, this isn’t engineering. There are very few cookie-cutter problems in big data. Everything after “hello world” has more complexity that needs a data engineer because there isn’t a cookie-cutter approach to dealing with it. Getting your design copied from a white paper could lead to a poor performing design or worse.
I’ve dealt with a few data science teams who’ve tried this monkey-see-monkey-do approach. It doesn’t work well. This is due to big data’s spike in complexity and the extreme focus on use cases. The data science team will often drop the project as it exceeds their data engineering abilities.
Put simply, there’s a big difference between “I can copy code from stackoverflow” or “I can modify something that’s already been written” and “I can create this system from scratch.”
Personally, I’m worried that data science teams are going to be these sources of massive technical debt that squelches big data productivity in organizations. By the time it’s found out, the technical debt will be so high it might be infeasible to correct it.
What’s the longest their code has been in production?
A core difference for data scientists is their depth. This depth is shown in two ways. What’s the longest time their code been in production—or has it ever been in production? What is the longest, largest, or most complicated program they have ever written?
This isn’t about gamesmanship or who’s better; it’s showing if they know what happens when you put something in production and how to maintain code. Writing a 20-line program is comparatively easy. Writing 1,000 lines of code that’s maintainable and coherent is another situation all together. People who’ve never written more than 20 lines don’t understand the miles of difference in maintainability. All of their complaints about Java verbosity or why programming best practices need to be used come into focus with large software projects.
Moving fast and breaking things works well when evaluating and discovering data. It requires a different and more intense level when working with code that goes into production. It’s for reasons like these that most data scientist’s code gets rewritten before it goes into production.
When they design a distributed system
One way to know the difference between data scientists and data engineers is to see what happens when they write their own distributed systems. A data scientist will write one that is very math focused but performs terribly. A software engineer with a specialization in writing distributed systems will create one that performs well and is distributed (but seriously don’t write your own). I’ll share a few stories of my interactions with organizations where data scientists created a distributed system.
A business unit that was made up of data scientists at my customer’s company created a distributed system. I was sent in to talk to them and get an understanding of why they created their own system and what it could do. They were doing (distributed) image processing.
I started out by asking them why they created their own distributed system. They responded that it wasn’t possible to distribute the algorithm. To validate their findings, they contracted another data scientist with a specialty in image processing. The data scientist contractor confirmed that it wasn’t possible to distribute the algorithm.
In the two hours I spent with the team, it was clear that the algorithm could be distributed on a general-purpose compute engine, like Spark. It was also clear that the distributed system they wrote wouldn’t scale and had serious design flaws. By having another data scientist validate their findings instead of a qualified data engineer, they had another novice programmer validate their novice findings.
At another company run by mathematicians, they told me about the distributed system they wrote. It was written so that math problems could be run on other computers. A few things were clear after talking to them. They could have used a general-purpose compute engine and been better off. The way they were distributing and running jobs was inefficient. It was taking longer to do the RPC network traffic than it was to perform the calculation.
There are commonalities to all of these stories and others I didn’t tell:
- Data scientists focus on the math instead of the system. The system is there to run math instead of running math efficiently.
- Data engineers know the tricks that aren’t math. We’re not trying to cancel out infinities.
- A data scientist asks, “how can I get a computer to do my math problems?” A data engineer asks, “how can I get a computer to do my math problems as fast and efficiently as possible?”
- The organizations could have saved themselves time, money, and heartache by using a general-purpose engine instead of writing their own.
What’s the difference?
You’ve made it this far and I hope I’ve convinced you: data scientists are not data engineers. But really, what difference does all of this make?
The difference between a data scientist and a data engineer is the difference between an organization succeeding or failing in their big data project.
Data science from an engineering perspective
When I first started to work with data scientists, I was surprised at how little they begged, borrowed, and stole from the engineering side. On the engineering front, we have some well-established best practices that weren’t being used on the data science side. A few of these are:
- Source control
- Continuous integration
- Project management frameworks like Agile or Scrum
- IDEs
- Bug tracking
- Code reviews
- Commenting code
You saw me offhandedly mention the technical debt I’ve seen in data science teams. Let me elaborate on why I’m so worried about this. When I start pushing on a data science team to use best practices, I get two answers: “we know and we’re going to implement that later” or “we don’t need these heavyweight engineering practices. We’re agile and nimble. These models won’t go into production yet.” The best practices never get implemented and that model goes straight into production. Each one of these issues leads to a compounding of technical debt.
Code quality
Would you put your intern’s code into production? If you’re in management, go ask your VP of engineering if they’ll put a second-year computer science student’s code into production. You might get a vehement no. Or they might say after the code was reviewed by other members of the team.
Are you going to put your data scientist’s code into production? Part of the thrust of this article is that data scientists are often novices at programming—at best—and their code is going into production. Take a look back up at the best practices that data science teams aren’t doing. There are no checks and balances to keep amateur code from going into production.
Why did they get good?
I want to end this by addressing the people who are still thinking their data scientists are data engineers. Or those data scientists who are also qualified data engineers. I want to restate that you can see from the figure it is possible, just not probable.
If this is true, I’d like you to think about why this happened.
In my experience, this happens when the ratio of data scientists to data engineers is well out of alignment. This happens when the ratio is inverted and there are zero data engineers in the organization. There should be more like two to five data engineers per data scientist. This ratio is needed because more time goes into the data engineering side than the data science.
When teams lack the right ratio, they’re making poor use of their data scientists’ time. Data scientists tend to get stuck on the programming parts that data engineers are proficient in. I’ve seen too many data scientists spend days on something that would take a data engineer an hour. This incorrectly perceived and solved problem leads organizations to hire more data scientists instead of hiring the right people who make the process more efficient.
Other times, they’re misunderstanding what a data engineer is. Having unqualified or the wrong type of data engineer is just as bad. You need to make sure you’re getting qualified help. This leads to the fallacy that you don’t need a data engineer because the ones you’ve worked with aren’t competent.
I’m often asked by management how they should get their data scientists to be more technically proficient. I respond that this is more a question of should the data scientists become more technically proficient. This is important for several reasons:
- There’s a low point of diminishing returns for a data science team that isn’t very technical to begin with. They can study for months, but may never get much better.
- It assumes that a data scientist is a data engineer and that isn’t correct. It would be better to target the one or two individuals on the data science team with the innate abilities to get better.
- Is there an ROI to this improvement? If the data science team gets better, what could it do better or different?
- It assumes the highest value is to improve the data science team. The better investment may be in improving the data engineering team and facilitating better communication and relations between the data science and data engineering teams.
- It assumes that the data scientists actually want to improve technically. I’ve found that data scientists consider data engineering a means to an end. By doing the data engineering work, they get to do the fun data science stuff.
What should we do?
Given that a data scientist is not a data engineer, what should we do? First and foremost, we have to understand what data scientists and data engineers do. We have to realize this isn’t a focus on titles and limiting people based on that. This is about a fundamental difference in what each person is good at and their core strengths.
Having a data scientist do data engineering tasks is fraught with failure. Conversely, having a data engineer do data science is fraught with failure. If your organization is trying to do data science, you need both people. Each person fulfills a complementary and necessary role.
For larger organizations, you will start to see the need for people who split the difference between the data scientist and data engineer skill sets. I recommend the management team look at creating a machine learning engineer title and hiring for it.
Success with big data
As you’ve seen here, the path to success with big data isn’t just technical—there are critical management parts. Misunderstanding the nature of data scientists and data engineers is just one of those. If you’re having trouble with your big data projects, don’t just look for technical reasons. The underlying issue may be a management or team failure.
As you’re doing a root cause analysis of why a big data project stalled or failed, don’t just look at or blame the technology. Also, don’t just take the data science team’s explanation because they may not have enough experience to know or understand why it failed. Instead, you’ll need to go deeper—and often more painfully—to look at the management or team failings that led to a project failure.
Failures like these form a repeating and continuous pattern. You can move to the newest technology, but you’re just fixing the systemic issues. Only by fixing the root issue can you start to be successful.