A data platform for data scientists, DevOps, and developers
A new platform founded by Intel combines open source components to make data analytics and data applications easier to manage.
 Looking up at the Sky Reflector-Net in the center of the Fulton Building in New York City. (source: Wikimedia Commons)
Looking up at the Sky Reflector-Net in the center of the Fulton Building in New York City. (source: Wikimedia Commons)
Giant masses of data don’t mean much unless they can be analyzed, processed, and presented to the people who can put that data to work. Toward that end, Intel is leading contributions to a new open source project, the Trusted Analytics Platform (TAP), that combines existing components optimized to speed up the process of ingesting and analyzing data from multiple sources and formats. TAP offers data scientists, DevOps professionals, and app developers a browser-based interface for applying big data in a variety of fields. In addition, TAP’s marketplace gives users access to an extensible set of tools and services.
In advance of OSCON (May 16-19, in Austin, Texas), OSCON chair and O’Reilly strategic content director Rachel Roumeliotis and Chuck Freedman, Chief Developer Advocate, in the Big Data Solutions group at Intel, talked about TAP and how it can help organizations. They discussed TAP’s functionality, its architecture, and how early adopters are putting it to use.

Learn faster. Dig deeper. See farther.
Freedman also offered details on Intel’s contest for new TAP solutions—more on that at the end of this article.
Their full conversation is available in the embed below. Highlights from their discussion follow.
Note: This interview was edited and condensed for clarity.
What is TAP?
TAP is an open source project in the analytics space. It’s a fusion of the best open source components available for data management and analytics, with the best open source components that are available for app and service management in the cloud. In a nutshell, we’re fusing elements of Hadoop and Spark with elements of Cloud Foundry and many popular data store technologies and tools, like MongoDB, Cassandra, PostgreSQL, Redis, and more.
We’re creating an environment for an operator within an organization to easily deploy this kind of platform for their team, organization, or enterprise to leverage. Then, data scientists can go in there, with the tools they’re already familiar with, or they can discover some new accelerated tools to work with ingesting and processing data. They can then make that data available to solutions developers. An app developer can go into that same cloud environment and build a solution against that data.
By “solution,” we mean an application, a visualization, automation, or some kind of notification app, depending on the kind of data that they can make available to their organization or to their customers. It’s a really big effort that we’ve undertaken.
What’s the layout of TAP’s architecture?
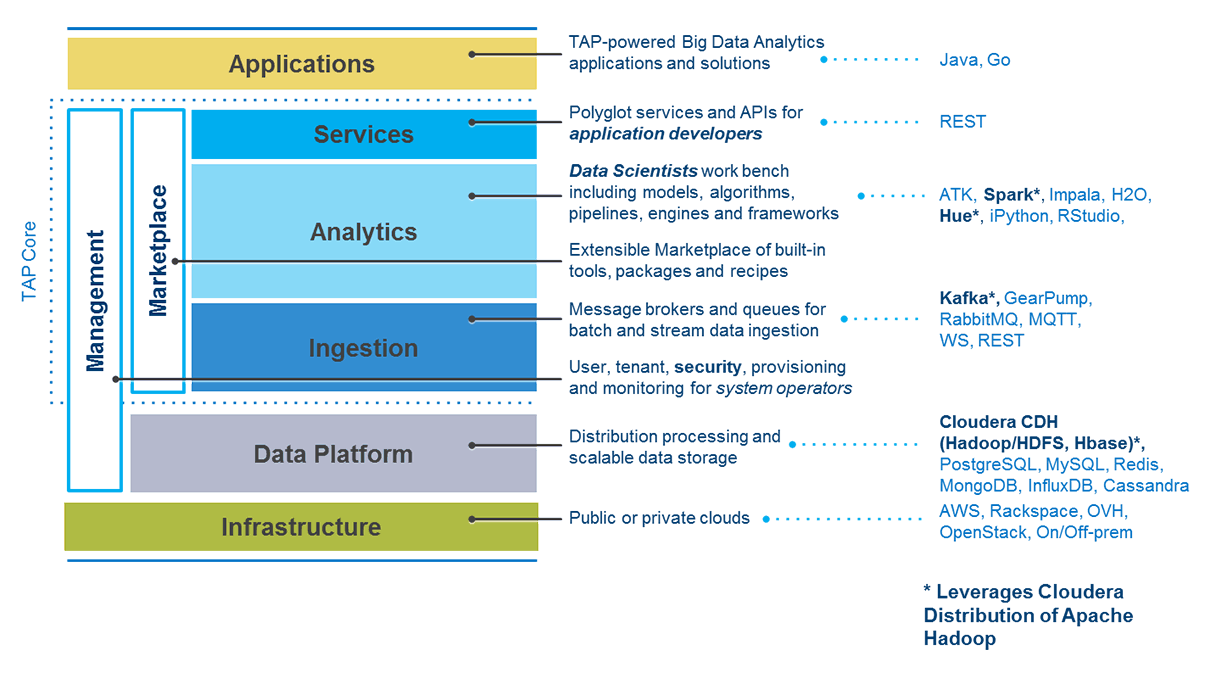
There’s a good diagram that I use for reference for our architecture (see below). The infrastructure can be a public or a private cloud where TAP is ultimately deployed. On top of that, we use CDH, which is Cloudera’s distribution of Hadoop, to add a level of data management. We then build on that with an ingestion layer, which makes available several services, like Kafka, Gear Pump, RabbitMQ, depending on the data you’re ingesting or streaming into the platform.
Probably the most prominent element of TAP for the data scientist is the analytics tool set. Intel has been a long time leading contributor to Apache Spark. It’s also a leading contributor to Apache Hadoop, and many other tools and components found within TAP. Spark, in particular, is at the core of what we call the TAP analytics toolkit. There’s a services element, which is something that Cloud Foundry brings in mostly, although we’ve contributed a lot to this layer in making it more operable between the Hadoop elements, and what the application developer really wants to do in the cloud.
Then, finally, there’s the applications layer. Those apps live in the cloud, where they’re made available to, say, an administrator within an organization or to customers that have hired a developer in their respective team to build a solution on top of big data.
How is TAP helping people?
Some of the early adopters have been research institutes that are trying to break the way they currently manage and share data. We have adoptions among some cancer research institutes, we have adoptions among some leading hospital organizations. The goal is to accelerate research and machine learning for identifying and curing diseases. A hospital can use a TAP application to look at recurring symptoms patients have after procedures and catch things that keep repeating but are undetectable to the human eye. That information can be used to reduce the hospital’s readmission rate. Helping people, I think, has been probably the most prominent use case.
We also see it being used in industry, where a lot of sensor-driven data is making water management smarter, or oil pump management, or farming equipment, or energy efficiency. These are all things — very prominent use cases in big data — that we see come across significantly in the early uses of the Trusted Analytics Platform.
Who are TAP’s primary users?
We want to meet the needs of three distinct users within the TAP ecosystem. The operator (the DevOps role), the data scientist, and the developer. DevOps is the first line because TAP does need to be installed and maintained for the organization. Once it’s set up, its tools and services are available for respective data scientists and developers. DevOps still, in most cases, owns the environment and will be the group that makes that support decision.
And now for the contest…
The group behind TAP is looking for code commits in two categories:
- Most innovative usage of existing TAP services.
- Best extension or improvement of existing TAP utilities.
Entries will be accepted until April 29, 2016. Winners will be chosen before OSCON, with a chance to join Intel on stage at the event. For full details see Chuck Freedman’s blog post about the contest.
This post is part of a collaboration between O’Reilly and Intel. See our statement of editorial independence. Intel’s contest is in no way connected with O’Reilly Media, Inc.