A framework for performance
Performance Engineering throughout the lifecycle.
 Jet engine (source: LittleVisuals via Pixabay)
Jet engine (source: LittleVisuals via Pixabay)
As you start to incorporate Performance Engineering capabilities into your lifecycle, it is important to understand what some of these areas are, and put these into context with some typical flow nomenclature. In the following sections we define each of these key elements with specifics—what, why, and how—so you have a more complete understanding of how to add Performance Engineering throughout the lifecycle.
One of the challenges in building Effective Performance Engineering or a performance-first culture is defining who does what, when, and how. This kind of organizational alignment and agreement is as important as the daily scrum meeting of an Agile team. If everyone agrees that performance is important, but not on how to address it, then nothing is done about it.

Learn faster. Dig deeper. See farther.
First, we need to agree that while everyone is responsible for the performance of our business applications, someone needs to be accountable. One person, or team in a larger organization, needs to make sure everyone is playing along in order to meet our objectives. It could be the Scrum Master, Engineering Team Lead, QA Lead, or a separate role dedicated to performance.
Some organizations have even created a “Chief Performance Officer” role to bring visibility and accountability to the position, along with information radiators to show performance results as visual and accountable feedback throughout the process. Once that person or group is identified, it is important to include them in any standup meetings or architectural discussions, in order to raise any red flags early in design and avoid costly rework at later stages.
Culture needs to be built into an organization by design. There are several solid, cross-industry examples included in a Staples Tech Article; we’ll examine these more closely and investigate how their culture is focused on Performance Engineering, and how they have built in these capabilities. The following sections cover the what, why, and how of Effective Performance Engineering capabilities, so that as you look at this culture and the role(s) of adoption, you can start to understand more specifically how it might apply within your own organization.
Requirements
Features and functions, along with capabilities both for new applications and maintaining legacy, all fall into this section, where we will highlight some specific elements for consideration as you are adopting Effective Performance Engineering practices. Take a look at these items and understand the what, why, and how of each, so as you begin to transform, you can ensure consideration for each specific element is being considered and adopted.
Complete stories
In defining the changes we are going to implement, complete and understood requirements or stories are a solid starting point. Mike Cohn, founder of Mountain Goat Software, and founding member of the Scrum Alliance and Agile Alliance, has created a user story template, shown in Figure 1.
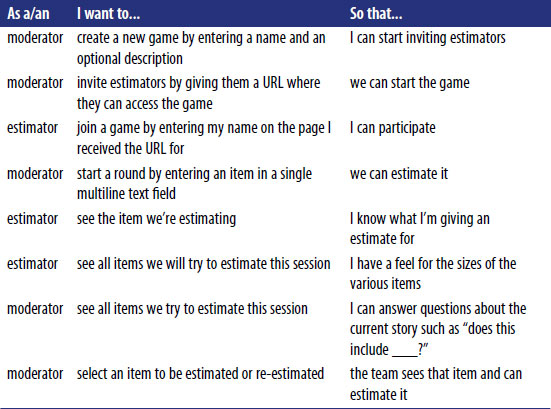
Using a thoughtful approach to stories has many benefits. With an incomplete definition of requirements and features, an individual or team is left to define what they believe the end user wants and needs. If Performance Engineering is not considered as part of a complete story, a technical component or architecture could vary considerably, resulting in underperforming or unutilized capabilities.
Organizations continue to evolve the way they create complete stories using models like Mike Cohn’s user story template, and also by adopting prototyping or wireframe capabilities to accelerate the delivery of high-quality results to the end users.
Breakdown of epic to tasks with acceptance criteria
It’s important to plan for the size, relationship, and priority of requirements and features, along with building in performance that shows the relationship to epic to task, in order to enable teams to collaborate and consider Performance Engineering needs and capabilities from the start.
Figure 2 shows the relationship and breakdown from epic to tasks, along with a story card with Story on front and Acceptance Test Criteria on the back.

In many cases, we observe a trend of more myopic or task-level views into stories. This practice limits the view and consideration across tasks, and limits the ability to build higher performing platforms, especially in the much-distributed and shared complex applications and systems we operate within today.
In Figure 2, you can see how the story is on the front of the card (typically only used portion) and on the back are the acceptance criteria, which is where you include Performance Engineering considerations. An example from a recent story about a login page is, “Perform with 180,000 people logging in per hour with 50% on varying mobile network conditions from 5 major US and 2 major International locations with the remaining from good WiFi and LAN connections with a maximum transaction response time of <5 seconds.”
Doneness criteria
A proven practice among organizations is defining a shared understanding and standard for what “done” means. Creating a “Feature Doneness” definition for all teams is critical, and Performance Engineering considerations need to be built in. The standard for speed and quality must be a known and shared value across individuals, teams, business units, and organizations. Perhaps there are only 5–10 core criteria defined and agreed upon at a complete organization level, but this is the delivered standard.
This will enable a level of doneness in order to meet shared expectations and deliver within the agreed-upon time and quality.
A recent example of how a Dev/Test organization put together their doneness criteria is outlined below. Here, the organization had only eight criteria, of which the italicized one builds performance into their process:
- The code is included in the proper branch in the source code control system.
- The code compiles from a clean checkout without errors using production branch [proposed: and is part of the AHP Build Life which is finally tested in QA].
- The code is appropriately covered with unit tests and all tests are passing using the production branch.
- The code has been peer reviewed by another developer.
- Database changes have been reviewed and approved by a DBA.
- The code has passed integration, regression, stress, and load testing.
- Application Support is aware of the backlog item and the system impacts.
- Deployment and rollback instructions are defined, tested, and documented.
Until these are all true, the feature is simply unfinished inventory.
Functional
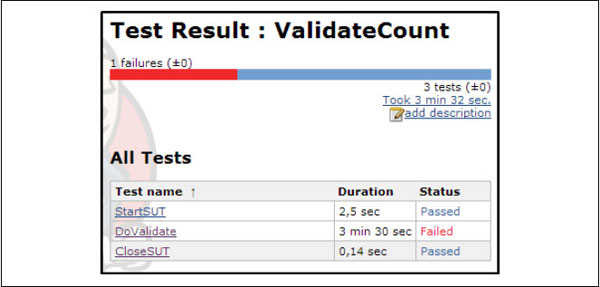
Within the functional tests you run today, think about how to leverage these (typically single-user) tests to get performance results and share them with all stakeholders. This can take place at any stage throughout your lifecycle from unit to production, and the value of these results benefits the team throughout the lifecycle. A specific example could be the way performance is built in to your automated functional unit tests, as demonstrated in Figure 3, which illustrates how long a specific set of automated functional unit tests took to run and set a pass/fail threshold within Jenkins.
The reasons why this is important are numerous. One of the common areas we focus on is speed with quality. As you are increasing the number of builds per hour/day/week/month, these Performance Engineering practices enable early and frequent feedback on quality. The incremental value delivered with every build enables quick feedback loops and opportunities for DevTest teams to deliver higher quality faster by building in performance within their automated functional tests.