
 Symmetry (source: Pixabay)
Symmetry (source: Pixabay) New tools and practices in the DevOps area have automated a huge amount of the deployment issues that used to be done manually—but they have not automated many things developers need to do beyond coding and testing to get their programs running. In fact, the DevOps revolution has piled new burdens on developers who are not trained to handle them. Can the operations side of the organization automate the things that developers are currently struggling with on that side?
The new requirements placed on developers fall into three main areas:
Resource allocation
Programmers are used to defining variables (and allocating memory, if they use a variant of the C language) while leaving it up to the operating system to determine the RAM and disk space the program needs, and the processing time used throughout a run. With modern virtualization, containers, and technologies such as Hadoop, the developer is expected to predefine the resources that the program needs during its run.
Location and networking
Operations staff used to just hand the developers a system name and let them run the programs there (or schedule it on their behalf). Now developers have to survey the range of available machines (usually virtual machines, which means they come and go). They may also have to explain how new machines should be assigned as the load on the program increases, so that automatic or manual scaling can occur.
Security
Architectures in the pre-cloud era were static. The operations staff set up security through the actual wiring of networks, as well as through virtual networks and firewalls. An infosec team consulted with the developer to choose the right environment for the program. But in the cloud era, the developer is essentially responsible for re-creating a custom secure architecture through Software Defined Networking (SDN) and the use of security protocols, each time a program runs. The consequence is that security suffers.
Developers who had enough on their hands with design, development, integration, and testing now have to add all these tasks to their skill set. DevOps, a combination of what was formerly two jobs, can potentially double what a programmer needs to know. Although teams can offer more training in the new areas to their programmers, it’s time to consider an automated infrastructure that takes the burden off of programmers and allows them to concentrate on the service they are tasked to develop.
The goal should be to allow a developer to express resource, container, and security requirements on a level of business needs that the developer can easily understand—what Cisco CTO Ken Owens calls the operational intent of the program. An operations infrastructure would then allocate everything in the run-time infrastructure that is needed to carry out this intent.
For instance, suppose the program has to ensure that a response to a query is sent out in half a second. The developer can request this from the operations infrastructure. The operations team, in current environments, would already know that a program handling a query of a certain size over a network connection of a certain speed needs a 2-Gigahertz CPU and 4 MB of memory. This knowledge would be encoded in the operations infrastructure so it can allocate the resources in response to the developer’s request. Even better, the infrastructure could watch the program’s response time and automatically increase or decrease resources, the way modern operating systems manage memory and CPU time.
At a higher stage of sophistication, a developer could just say “I need the best response time possible” or “this application is latency-sensitive” and get the resources that come closest to meeting that need, within limits specified by operations staff. Business groups could set priorities, so that the most critical jobs could take resources away from background tasks. If a programmer requests high security, the job might run on dedicated systems protected by firewalls and encryption.
Operations teams could provide each business group with maximums for various resources, as well as minimums (for security, for instance). The infrastructure would also take costs into account, and balance costs against performance to find a point where the infrastructure can deliver the maximum combined benefit.
Cisco has been working on such an operations infrastructure for its customers called Application Intent with their open source effort Mantl. It uses a different classification of needs from other policy models in the field (TOSCA, Openstack Congress, Group Based Policy, etc.). The Mantl policy system introduces the idea of sensitivity, the parameters in the application’s performance and response time that influence the end user’s perception of performance. The policy system can adjust each sensitivity along a scale, ranging from no sensitivity to high sensitivity, as it measures perceptions of the performance by the system and end users.
Application intent sensitivities are:
- Compute
- CPU Sensitivity
- Memory Sensitivity
- Storage
- Latency Sensitivity
- Volume Sensitivity
- I/O
- Latency Sensitivity
- Throughput Sensitivity
- Thresholds (an optional numerical value – e.g., 80 connections/second)
- Fault/performance
- Recovery Sensitivity
- Availability Sensitivity
- Scale Sensitivity
- Accounting
- Cost Sensitivity
Given these sensitivities, the resulting policy system can create a service-level agreement (SLA) for business objectives. In addition to these sensitivities, the policy system tracks two sets of properties of the overall system. The first properties deal with dependencies:
- Services
- Service Affinity
- Service Anti-Affinity
- Security Policies (Data Classification)
- Placement Policies
- Host Affinity
- Host Anti-Affinity
- Availability Zones
- Regions
- Geo
- Constraints – non-coexistence
The second properties deal with limits and constraints on the policy:
- Metering Limits
- I/O
- CPU
- Memory
- Connections/second
- Security Governance
- Organizational Constraints (IE, HR, Legal, Engineering)
- Data Type Constraints (Public, Sensitive, Confidential, Top Secret)
- Operational Constraints
- Encryption
- Auditing
- Log Retention
Figure 1 shows how these properties are shown to the programmers or ops person during a program run.
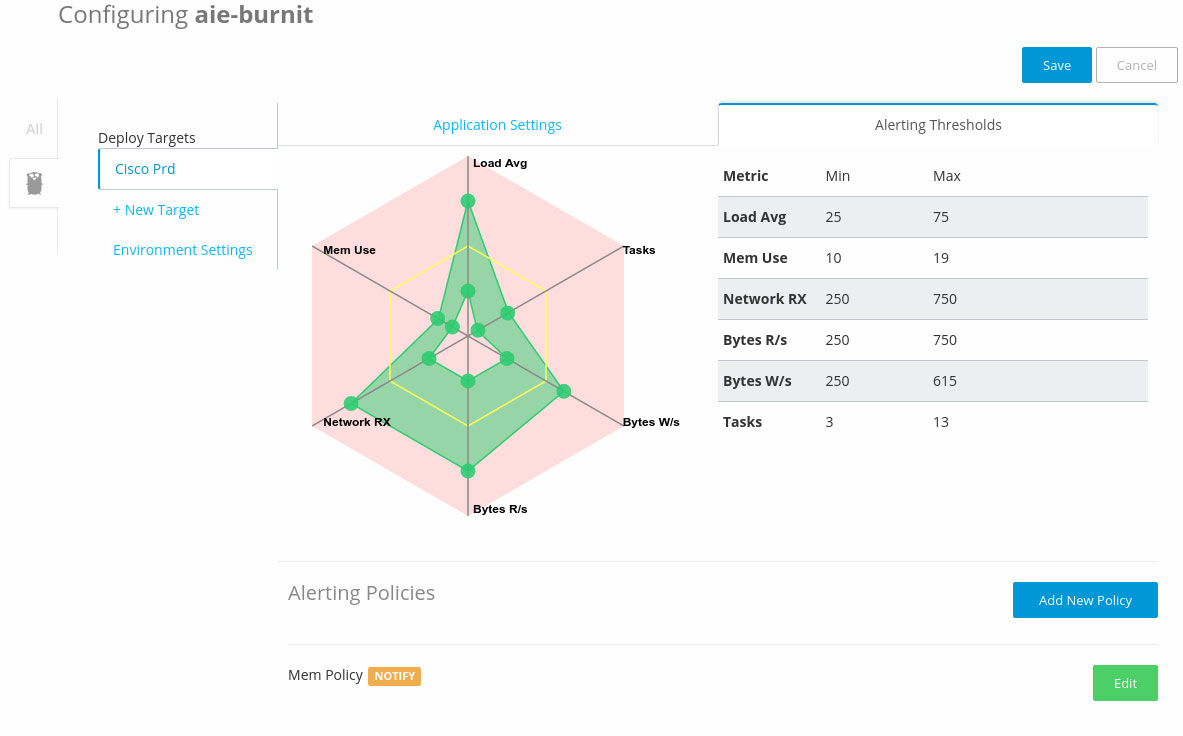
The DevOps movement came into being to facilitate and speed up program deployment, not to throw barriers in the programmer’s path. A sophisticated understanding of resource usage, combined with some automation, can bring us toward this goal.
This post is part of a collaboration between O’Reilly and Cisco. See our statement of editorial independence.