Apache Kafka and the four challenges of production machine learning systems
Untangling data pipelines with a streaming platform.
 Hopscotch (source: Pixabay)
Hopscotch (source: Pixabay)
Machine learning has become mainstream, and suddenly businesses everywhere are looking to build systems that use it to optimize aspects of their product, processes or customer experience. The cartoon version of machine learning sounds quite easy: you feed in training data made up of examples of good and bad outcomes, and the computer automatically learns from these and spits out a model that can make similar predictions on new data not seen before. What could be easier, right?
Those with real experience building and deploying production systems built around machine learning know that, in fact, these systems are shockingly hard to build. This difficulty is not, for the most part, the algorithmic or mathematical complexities of machine learning algorithms. Creating such algorithms is difficult, to be sure, but the algorithm creation process is mostly done by academic researchers. Teams that use the algorithms in production systems almost always use off-the-shelf libraries of pre-built algorithms. Nor is the difficulty primarily in using the algorithms to generate a model, though learning to debug and improve machine learning models is a skill in its own right. Rather, the core difficulty is that building and deploying systems that use machine learning is very different from traditional software engineering, and as a result, it requires practices and architectures different from what teams with a traditional software engineering background are familiar with.

Learn faster. Dig deeper. See farther.
Most software engineers have a clear understanding of how to build production-ready software using traditional tools and practices. In essence, traditional software engineering is the practice of turning business logic explicitly specified by engineers or product managers into production software systems. We have developed many practices in how to test and validate this type of system. We know the portfolio of skills a team needs to design, implement, and operate them, as well as the methodologies that can work to evolve them over time. Building traditional software isn’t easy, but it is well understood.
Machine learning systems have some of the same requirements as traditional software systems. We want fast, reliable systems we can evolve over time. But a lot about the architecture, skills, and practices of building them is quite different.
My own experience with this came earlier in my career. I’d studied machine learning in school and done work on applying support vector machines, graphical models, and Bayesian statistical methods on geographical data sets. This was a good background in the theory of machine learning and statistics, but was surprisingly unhelpful about how one would build this kind of system in practice (probably because, at the time, very few people were). One set of experiences that drove this came from my time at LinkedIn, beginning in 2007. I had joined LinkedIn for the data: the opportunity to apply cutting-edge algorithms to social network data. I managed the team that, among other things, ran People You May Know and Similar Profiles products, both of which we wanted to move from ad hoc heuristics to machine learning models. Over time, LinkedIn built many such systems for problems as diverse as newsfeed relevance, advertising, standardizing profile data, and fighting fraud and abuse.
In doing this, we learned a lot about what was required to successfully build production machine learning systems, which I’ll describe in this post. But first, it’s worth getting specific about what makes it hard. Here are four particularly difficult challenges.
Challenge one: Machine learning systems use advanced analytical techniques in production software
The nature of machine learning and its core difference from traditional analytics is that it allows the automation of decision-making. Traditional reporting and analytics is generally an input for a human who would ultimately make and carry out the resulting decision manually. Machine learning is aimed at automatically producing an optimal decision.
The good news is that by taking the human out of the loop, many more decisions can be made: instead of making one global decision (that is often all humans have time for), automated decision-making allows making decisions continuously and dynamically in a personalized way as part of every customer experience on things that are far too messy for traditional, manually specified business rules.
The challenge this presents, though, is that it generally demands directly integrating sophisticated prediction algorithms into production software systems. Human-driven analytics has plenty of failures, but the impact is more limited as there is a human in the loop to sanity-check the result (or at least take the blame if there is a problem!). Machine learning systems that go bad, however, often have the possibility of serious negative impact to the business before the problem is discovered and remediated.
Challenge two: Integrating model builders and system builders
How do you build a system that requires a mixture of advanced analytics as well as traditional software engineering? This is one of the biggest organizational challenges in building teams to create this type of system. It is quite hard to find engineers who have expertise in both traditional production software engineering and also machine learning or statistics. Yet, not only are both of these skills needed, they need to be integrated very closely in a production-quality software system.
Complicating this, the model building toolset is rapidly evolving and will often change as the model itself evolves. Early quick and dirty work may be little more than a simple R or Python script. If scalability is a challenge, Spark or other big data tools may be used. As the modeling graduates from simple regression models to more advanced techniques, algorithm-specific frameworks like Keras or TensorFlow may be employed.
Even more than the difference in tools and skills, the methodology and values are often different between model builders and production software engineers. Production software engineers rigorously design and test systems that have well-defined behaviors in all cases. They tend to focus on performance, maintainability, and correctness. Model builders have a different definition of excellence. They tend to value enough software engineering to get their job done and no more. Their job is inherently more experimental: rather than specifying the right behavior and then implementing it, model builders need to experimentally gather possible inputs and test their impact on predictive accuracy. This group naturally learns to avoid a heavy up-front engineering process for these experiments, as most will fail and need to be removed.
The speed with which the model building team can generate hypotheses about new data or algorithmic tweaks that might produce improvements in predictive accuracy, and validate or invalidate these hypotheses, is what determines the progress of the team at driving predictive accuracy.
A fundamental issue in the architecture of a machine learning-powered application is how these two groups can interact productively: the model builders need to be able to iterate in an agile fashion on predictive modeling and the production software engineers need to integrate these model changes in a stable, scalable production system. How can the model builders be kept safe and agile when their very model is at the heart of a system that is an integral part of an always-on production software system?
Challenge three: The failure of QA and the importance of instrumentation
Normal software has a well-defined notion of correctness that is mostly independent of the data it will run on. This lets new code be written, tested, and shipped from a development to production environment with reasonable confidence that it will be correct.
Machine learning systems are simply not well validated by traditional QA practices. A machine learning model takes input values and generally produces a number as output. Whether the system is working well or poorly, the output will still be a number. Worse, it is mostly impossible to specify correctness for a single input and the corresponding output, the core practice in traditional QA. The very notion of correctness for machine learning is statistical and defined with respect not just to the code that runs it, but to the input data on which it is run. Unit and integration tests, the backbone of modern approaches to quality assurance in traditional software engineering, are often quite useless in this domain.
The result is that a team building a machine learning application must lean very heavily on instrumentation of the running system to understand the behavior of their application in production, and they must have access to real data to build and test against, prior to production deployment of any model changes. What inputs did the application have? What prediction did it make? What did the ground truth turn out to be? Recording these facts and analyzing them both retrospectively and in real-time against the running system is the key to detecting production issues quickly and limiting their impact.
In many ways, this is an extension of a trend in software engineering that has become quite pronounced over the last 10 years. When I started my career, software was heavily QA’d and then shipped to production with very little ability to follow its behavior there. Modern software engineering still values testing (though hopefully with a bit more automation), but it also uses logging and metrics much more heavily to track the performance of systems in real time.
This discipline of “observability” is even more important in machine learning systems. If modern systems are piloted by a combination of “looking at the instruments” and “looking out the window,” machine learning systems quickly must be flown almost entirely by the instruments. You cannot easily say if one bad result is an indication of something bad or just the expected failure rate of an inherently imperfect prediction algorithm.
The quality and detail of the instrumentation is particularly important because the output of the machine learning model often changes the behavior of the system being measured. A different model creates a different customer experience, and the only way to say if that is better or worse than it was before is to perform rigorous A/B tests that evaluate each change in the model and allow you to measure and analyze its performance across relevant segments.
Even this may not be enough. At LinkedIn, we measured improvements in performance only over a short time. One surprise we found was that there was a novelty effect: even adding random noise to the prediction could improve it in the short term because it produced novel results, but this would decay over time. This led to a series of improvements: tracking and using the novelty of the results that had been shown, feeding the prior exposures into the model, and changes in our procedures to run our experiments over a longer period of time.
Challenge four: Diverse data dependencies
Many of the fundamental difficulties in machine learning systems come from their hunger for data. Of course, all software is about data, but a traditional application needs only the data it uses to perform its business logic, or that which it intends to display on the screen. Machine learning models have a much more voracious hunger for data. The more data, the better! This can mean more examples to train your model with, but often even more useful is more features to include in the model. This necessitates a process of gathering diverse data sets from across the company (or even externally) to bring to bear all the features and examples that can help to improve predictions.
This leads to a software system built on top of data pulled from every corner of the business. Worse, it is rarely the case that the raw data is the signal that works best to model. Most often, significant cleanup and processing is required to get the data into a form that is most effective as input for the model.
The result is a tangle of data pipelines, spanning the company, often with very non-trivial processing logic, and a model that depends (in sensitive and non-obvious ways) on all these data feeds. This can be incredibly difficult to maintain with production SLAs. A group at Google has written a good summary of the issues with these data pipelines with the memorable title “Machine Learning: The High Interest Credit Card of Software Development.” The majority of their difficulties center around these pipelines and the implicit dependencies and feedback loops they create.
It is critical that the data set the model is built off of and the data set that the model is eventually applied to are as close as possible. Any attempt to build a model off of one data set, say pulled from a data warehouse, in a lab setting, and then apply that to a production setting where the underlying data may be subtly different is likely to run into intractable difficulties due to this difference.
Our experience with the People You May Know algorithm at LinkedIn highlights this. The single biggest cause in fragility in the system was the data pipelines that fed the algorithm. These pipelines aggregated data across dozens of application domains, and, hence, were subject to unexpected upstream changes whenever new application changes were made, often unannounced to us and in very different areas of the company. The complexity of the pipelines themselves were a liability. There was one year where the single biggest relevance improvement made all year was not an improvement in the machine learning algorithm used or a new feature added to the model, but rather fixing a bug in a particularly complex data pipeline that allowed the resulting feature to have much better coverage and be used in more predictions. It turned out this bug had been in place since the very first version of the system, subtly degrading predictive accuracy, unnoticed the entire time.
What is to be done?
Monica Rogati, one of LinkedIn’s first data scientists, does an excellent job of summarizing the difficulties of building machine learning and AI systems in her recent article “The AI Hierarchy of Needs.” Just like Maslow characterizes human needs in a layered pyramid going from the most basic (food, clothing, and shelter) to the highest level (self-actualization), Monica describes a similar hierarchy for AI and machine learning projects. Her hierarchy looks like this:
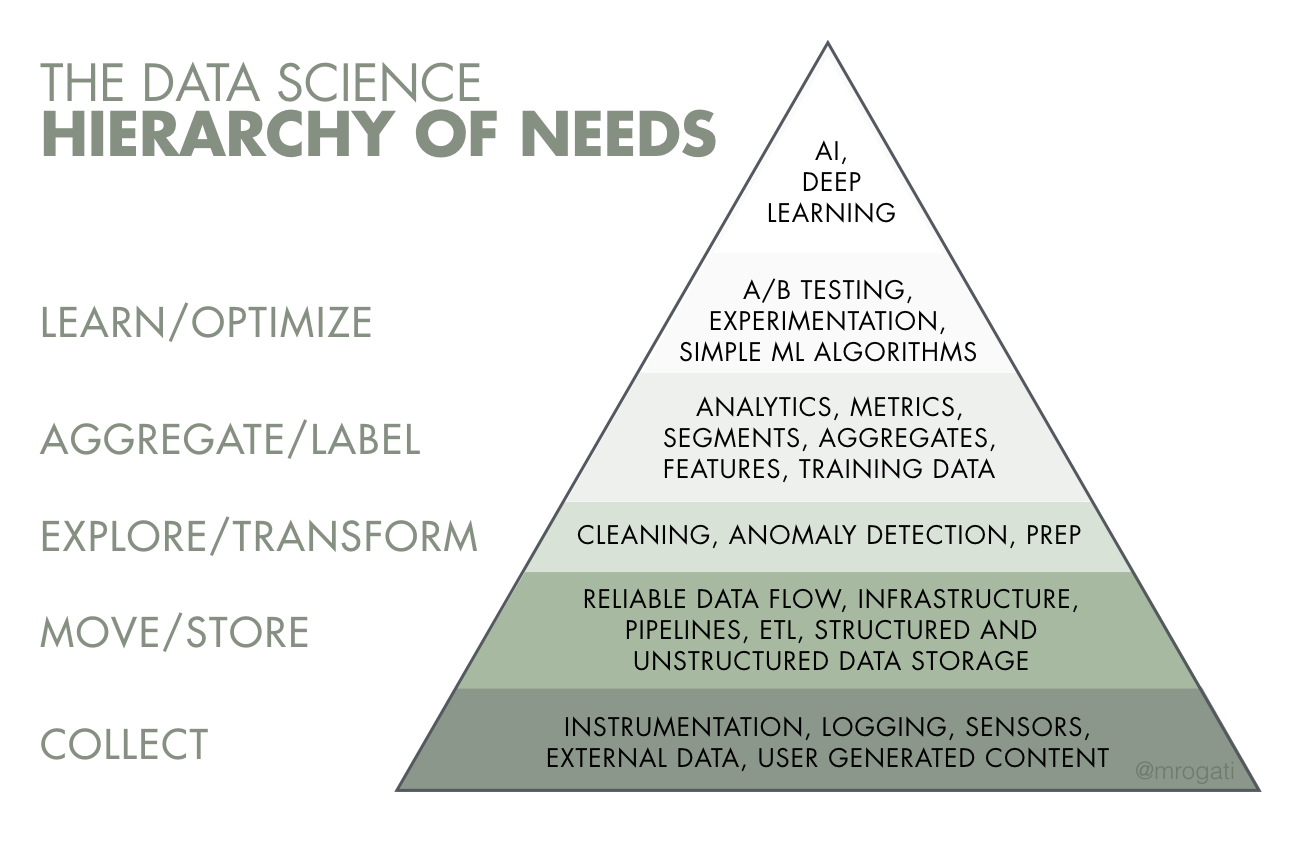
The first few layers are among the biggest sources of struggle for companies first attempting machine learning projects. They lack a structured, scalable, reliable way of doing data collection, and as a result, the data intended for modeling is often incomplete, wrong, out-of-date, not available, or sprinkled across a dozen different systems.
The good news is that while the problem of integrating machine learning into business problems is very particular to the problem you are trying to solve, the collection of data is much more similar across companies. By attacking this common problem, we can start to address some of these challenges.
Apache Kafka as a universal data pipeline
Apache Kafka is a technology that came out of LinkedIn around the same time that the work I described was being done on data products. It was inspired by a number of challenges in using the data LinkedIn had, but one big motivation was the difficulty in building data-driven, machine learning-powered products and the complexity of all the data pipelines required to feed them.
This went through many iterations, but we came to an architecture that looked like this:
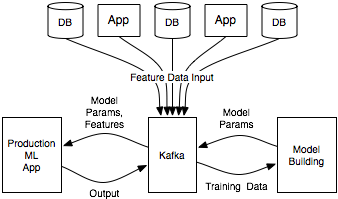
The essence of this architecture is that it uses Kafka as an intermediary between the various data sources from which feature data is collected, the model-building environment where the model is fit, and the production application that serves predictions.
Feature data is pulled into Kafka from the various apps and databases that host it. This data is used to build models. The environment for this will vary based on the skills and preferred toolset of the team. The model building could be a data warehouse, a big data environment like Spark or Hadoop, or a simple server running Python scripts. The model can be published where the production app that gets the same model parameters can apply it to incoming examples (perhaps using Kafka Streams, an integrated stream processing layer, to help index the feature data for easy usage on demand).
How does this architecture help to address the four challenges I described? Let’s go through each challenge in turn.
Kafka decouples model building and serving
The first challenge I described was the difficulty of building production-grade software that depends on complex analytics. The advantage of this architecture is that it helps to segregate the complex environment in which the model building takes place from the production application in which the model is applied.
Typically, the production application needs to be fairly hardened from day one, as it sits directly in the customer experience. However the model building is often done only periodically, say daily or weekly, and may even be only partially automated in initial versions. This architecture gives each of these areas a crisp contract to the other: they communicate through streams of data published to Kafka. This allows the model building to evolve through different toolsets, algorithms, etc., independent of the production application.
Importantly, Kafka’s pub/sub model allows forking the data stream so the data seen in the production application is exactly the same stream given to the model building environment.
A concrete example of this decoupling is the evolution that often happens in the freshness of the model. Often, early versions of the model are built in a semi-manual manner and refreshed monthly or weekly. However, training off up-to-date data is important for accuracy, so the retraining generally becomes more frequent as the application proves its worth. The end state for some of these models is a system that reacts and retrains itself with much lower latency: either periodically throughout the day or, in particularly dynamic problem domains, continuously. The advantage of this architecture is that the model building area can go through this evolution independently of the application that takes advantage of the model.
Kafka helps integrate model builders and system builders
Segregating the environment for model building from the production application and forking off the same feed of data to both allows the model builders freedom to embrace a toolset and process that wouldn’t be appropriate for production application development. The different groups can use the tools most appropriate for their domain and still integrate around shared data feeds that are identical in each environment.
Because of the segregation, the model builders can’t break the production application. The worst outcome they can produce is to allow the deployment of a more poorly performing model. Even this can be remediated by having automated A/B tests or bandit algorithms that control the rollout of new model changes so that a bad model can only impact a small portion of the user base.
Kafka acts as the pipeline for instrumentation
The next challenge was developing the level of instrumentation and measurement sufficient to judge the performance of the production application and being able to use that detailed feedback data in model building.
The same Kafka pipeline that delivers feature data and model updates can be used to capture the stream of events that records what happens when a model is applied. Kafka is scalable enough to handle even very large data streams. For example, many of the machine learning applications in LinkedIn would record not only every decision they made, but also contextual information about the feature data that lead to that decision and the alternative decisions that had lower scores. This vast firehose of data was captured and used for evaluating the performance, A/B testing new models, and gathering data to retrain.
The ability to handle both core feature data about the input to the algorithms as well as the event data recording what happened over the same pipeline significantly simplifies the integration problem of using all this data.
Kafka helps tame diverse data dependencies
The unification of input data with the instrumentation I just described is a special case of the general problem of depending on a diverse set of upstream data sources across the business. Machine learning models need a vast array of input data—data from sensors, customer attributes from databases, event data captured from the user experience, not to mention instrumentation recording the results of applying the algorithm. Each of these likely needs significant processing before it is usable for model building or prediction. Each of these data types is different, but building custom integration for each leads to a mess of pipelines and dependencies.
Typical approaches for capturing feature data take an ETL-like approach, where a central team tries to scrape data from each source system with relevant attributes, munge these into a usable form, and then build on top of it.
Centralizing all these data feeds on Kafka gives a uniform layer that abstracts away details of the source systems and ensures the same data feeds go to both the model building environment and the production environment. This also gives a clear contract to source systems: publish your data in a well-specified format so it can be consumed in these environments. Frameworks like Kafka Connect can help integrate with many databases and off-the-shelf systems to make this integration easy.
This also allows you to evolve the freshness of the feature data used by the algorithm. Early versions of a feature may be scripted together in a one-off batch fashion and published out to test the effectiveness. If the feature proves predictive, it can be implemented as a continuous stream-processing transformation that keeps the data the algorithm uses for prediction always in sync with source systems. This can all be done without reworking the application itself.
The machine learning app and the streaming platform
This architecture doesn’t solve all the problems in building machine learning applications—it still remains really hard. What it does do is help to provide a path to solidifying the bottom layer of the hierarchy of needs and solidifying your data pipelines, which, after all, are the “food/clothing/shelter” of the machine learning application. There are still many hard problems remaining in the layers above.
I’ve shown this architecture in the context of one application, and usually that is what you start with. Over time, though, this pattern can grow into a general purpose architecture that we call a streaming platform. Having a central platform prepopulated with streams of data obviously makes additional machine learning applications easier to build, but also enables asynchronous event-driven microservices and many other such use cases.
This is our driving vision behind Kafka: to make a central nervous system for data that allows intelligent applications to be easily integrated with normal event-driven microservices and other data pipelines.
If you want more concrete details on how to build machine learning systems using Kafka, an excellent blog series with real code examples is available here.