

In this episode of the Data Show, I spoke with Aurélien Géron, a serial entrepreneur, data scientist, and author of a popular, new book entitled Hands-on Machine Learning with Scikit-Learn and TensorFlow. Géron’s book is aimed at software engineers who want to learn machine learning and start deploying machine learning models in real-world products.
As more companies adopt big data and data science technologies, there is an emerging cohort of individuals who have strong software engineering skills and are experienced using machine learning and statistical techniques. The need to build data products has given rise to what many are calling “machine learning engineers”: individuals who can work on both data science prototypes and production systems.
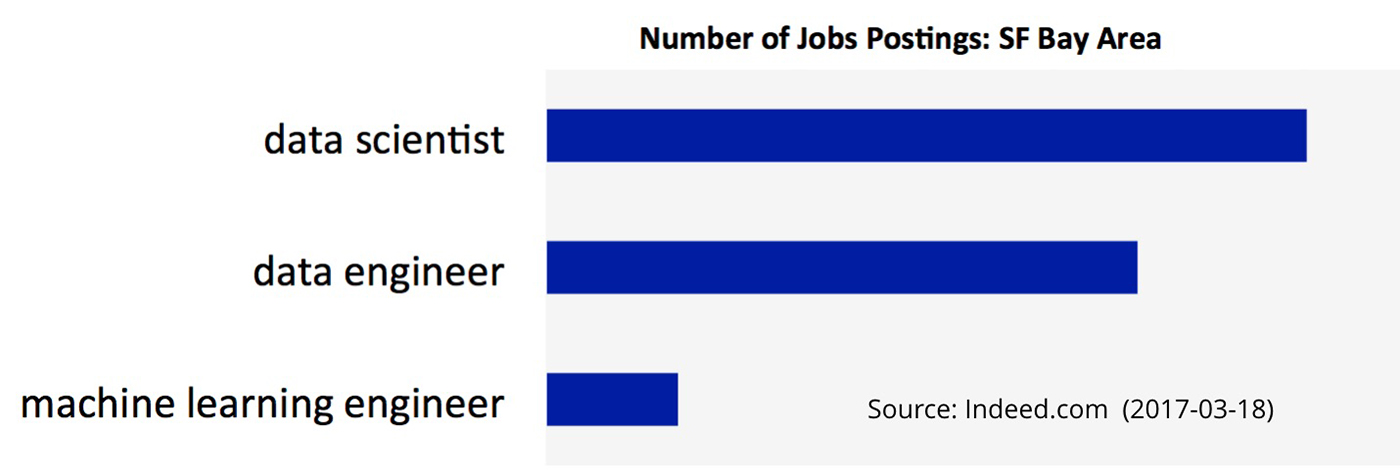
Géron is finding strong demand for his services as a consulting machine learning engineer, and he hopes his new book will be an important resource for those who want to enter the field.
Here are some highlights from our conversation:
From product manager to machine learning engineer
I decided to join Google. They offered me a job as the lead product manager of YouTube’s video classification team. The goal is to create a system that can automatically find out what each video is about. Google has a huge knowledge graph for hundreds of millions of topics in it, and the goal is to actually connect each video with all the topics in the knowledge graph covered in the video.
… I was a product manager, and I had always been a software engineer. I felt a little bit far from the technical aspects; I wanted to code again. That was the first thing. The second thing is, TensorFlow came out and there was a lot of communication internally at Google. I began using TensorFlow, and loved it. I knew TensorFlow would become popular, and I felt it would make for a good book.
Writing a machine learning book for engineers
I had gone through all the classes I could; there are internal classes at Google for learning machine learning, and they had great teachers there. I also learned as much as I could from books, from Andrew Ng’s Coursera class, and everything you can think of to learn machine learning. I was a bit frustrated by the books. The books are really good, but a lot of them are from researchers and they don’t feel hands-on. I’m a software engineer; I wanted to code. That’s when I decided that I wanted to write a book about TensorFlow that was really hands-on, with examples of code and things that engineers would pick up and start using right away. The other thing is that while there were a few books targeted at engineers, they really stayed as far away from the underlying math as possible. In addition, many of the existing books relied on toy functions, toy examples of code, and that was also a bit frustrating because I wanted to have production-ready code. That’s how the idea grew: write a book about TensorFlow for engineers, with production-ready examples.
Business metrics are distinct from machine learning metrics
You can spend months tuning a great classifier that will detect with 98% precision a particular set of topics, but then you launch it and it really doesn’t affect your business metrics whatsoever.
The first step is to really understand what the business metrics, or objectives, are. How are you going to measure them? Then, go and see if you have a chance at improving things. An interesting technique is to try to manually achieve the task. Have a human try to achieve the task and see if that has an impact. It’s not always possible, but if you can do that, it might be worth spending months building an architecture to do it automatically. If a human cannot improve things, it might be challenging for a machine to do better. It might still be possible, but it might be tougher.
Make sure you know what the business objective is and never to lose track of it. I’ve seen people start improving models, but they don’t really have metrics to see whether or not things have improved. It sounds stupid but one of the very first things you need to do is to make sure you have clear metrics that everybody agrees on. It’s very tempting to say, ‘I feel this architecture is going to work better’ and try to then work on it, but it hasn’t improved anything because you’re working without metrics.
Related resources:
- Hands-on Machine Learning with Scikit-Learn and TensorFlow (Aurélien Géron’s new book)
- What is Hardcore Data Science – in practice? (Mikio Braun on how to bring data science into production)
- The Deep Learning video collection (Strata Data 2016)
- Fundamentals of Deep Learning
- Advanced Analytics with Spark