
 Ninety odd years of banking (source: Internet Archive Book Images)
Ninety odd years of banking (source: Internet Archive Book Images) In a talk at CoinJar last fall, well-known bitcoin expert Andreas Antonopoulos made the following comment:
“I have no worries that bitcoin can scale, and the simple reason for that is that I know that IPv4 can’t, and yet I use it every day.”
The issue of bitcoin scalability and the phrase “blockchain scalability” are often seen in technical discussions of the bitcoin protocol. Will the requirements of recording every bitcoin transaction in the blockchain compromise its security (because fewer users will keep a copy of the whole blockchain) or its ability to handle a great number of transactions (because new blocks on which transactions can be recorded are only produced at limited intervals)? In this article, we’ll explore several meanings of “blockchain scalability” and some high-level technical solutions to the issue.
The three main stumbling blocks to blockchain scalability are:
- The tendency toward centralization with a growing blockchain: the larger the blockchain grows, the larger the requirements become for storage, bandwidth, and computational power that must be spent by “full nodes” in the network, leading to a risk of much higher centralization if the blockchain becomes large enough that only a few nodes are able to process a block.
- The bitcoin-specific issue that the blockchain has a built-in hard limit of 1 megabyte per block (about 10 minutes), and removing this limit requires a “hard fork” (ie. backward-incompatible change) to the bitcoin protocol.
- The high processing fees currently paid for bitcoin transactions, and the potential for those fees to increase as the network grows. We won’t discuss this too much, but see here for more detail.
We’ll consider these first two issues in detail.
The role of mining: Determining consensus and incentivizing participation
Bitcoin (or, more generally, cryptocurrency) mining serves several functions. Mining allows the peer-to-peer network that bitcoin is composed of to agree on a canonical order of transactions, thus solving the double spend problem. The double spend problem isn’t obvious in a traditional (i.e. centralized) context. Imagine a central arbiter or clearinghouse receiving transaction requests from clients to transfer money between parties. If the clearinghouse received two conflicting transactions (i.e. checks with the same number made out to different parties, or two checks that obviously emptied an account), then the clearinghouse could easily reject one or both of the transactions. The key property that the clearinghouse has is omniscience – it has total knowledge of all account balances and pending transfers.
Bitcoin partially does away with omniscience. In a peer-to-peer system, one does not generally have the expectation of knowledge of all messages. However, bitcoin transactions are intended to be broadcast one-to-all by peer forwarding. Thus, in principle, every network participant should have total knowledge of account states and pending transfers. A problem arises when a malicious actor propagates two conflicting transactions to the network. The peer-to-peer network must decide which transaction came first and must invalidate the second.
In broad terms, every transaction is confirmed by inclusion in a published block. A block is simply a set of transactions plus some data, including a timestamp and the hash of the previous block. The inclusion of the previous block hash cryptographically ties the current block to the previous block, as subsequent blocks will require the current block’s hash. If anything in a block is later modified, one could compute its hash and will find a different value as the stated one (with overwhelming probability), as such, one will not accept that block. Thus, including the previous block’s hash in the current block incorporates the entire system history into the current block.
Let’s return to the double spend problem. Bitcoin solves the double spend problem by imposing that honest miners accept the first transaction that they see. That transaction is still unconfirmed until it is published in a block. Blocks are found by mining, which is the process of expending computing power to solve cryptographic puzzles. Given a puzzle solution, a miner earns the right to publish a block and gain a reward for his service. Interestingly, as Satoshi argued in the original whitepaper, this imbues bitcoin with subjective value.
Other miners won’t accept a miner’s block if it contains two conflicting transactions, so the miner must choose between the two in order to get the reward. On receipt of a block, a miner may choose to accept it or not. If the block is valid (i.e. contains no conflicting or mal-formed transactions), miners are expected to accept it by default. A miner signals acceptance of a block by searching for subsequent blocks and including the hash of the received block into those blocks.
Trends toward centralization
Many bitcoin thinkers have argued that the returns to bitcoin mining with a large group of processors will cause a tendency toward a small number of miners or mining pools winning the majority of the blocks (and, by consequence, having the most influence over the network). We can already observe empirically that more than 50% of the hashpower securing the network right now is owned by just five entities – see figure 1. This is a real security threat. Five is a small enough number that state-level actors could directly coerce all five entities without too much trouble. Five is also small enough that active collusion would be fairly easy to coordinate.
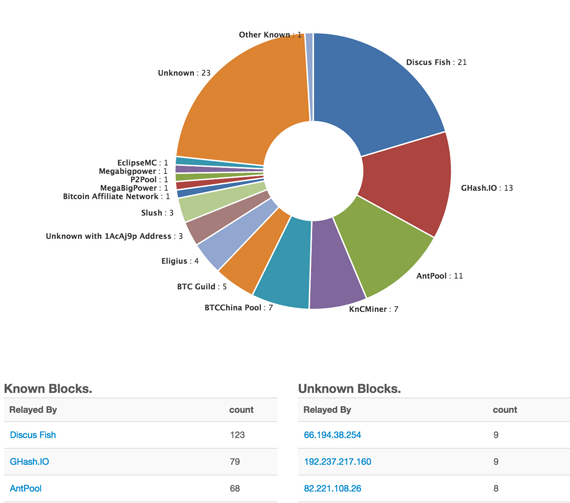
{kind=link}
Whether this distribution of mining power will be typical in the long run remains to be seen. Satoshi’s gentleman’s agreement to delay the mining arms race is clearly over. The hope that the average hobbyist could fire up the client, donate a few clock-cycles and be welcomed into the bitcoin ecosystem with a block reward is now certainly dead.
Growth Trend
The bitcoin blockchain is a massively replicated, append-only ledger. Its entries are transactions of various types, including transfers from one pseudonymous public key to another, coinbase transactions (which mint new bitcoins), and transactions that encode and store some sort of metadata on the blockchain. Full nodes must store the entire blockchain for the following reasons (and more):
- Bitcoin balances are defined by the blockchain, specifically by the extant set of Unspent Transaction Outputs (UTXOs)
- Bitcoin’s transaction validation / verification algorithm requires knowledge of the entire history of the protocol
- Mining bitcoins requires full knowledge of the blockchain (more precisely, mining requires knowledge of the hash of the previous block, which is proof, in a loose cryptographic sense, of complete knowledge of the blockchain).
The bitcoin blockchain is presently about 25 GB in size. Downloading the blockchain peer-to-peer takes about 48 hours, and of course 25 GB of disk space. This is a serious user experience flaw; though, we’ve heard that improvements are in the works.
A log plot of the size of the blockchain over the last two years reveals an approximately linear trend:
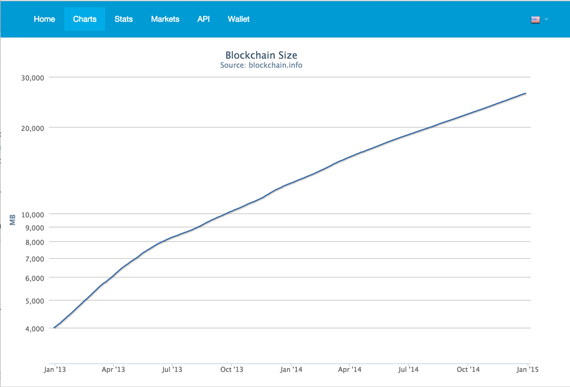
{kind=link}
Computing a best fit line to the logarithmic data reveals an approximate factor of 1.8 increase in the size of the blockchain per year. It’s too early to assess the robustness of this trend, but as with many technology growth curves, we should see an exponential pattern for some time.
To assess the extent to which disk space is a problem, we need to compare to projections for disk space. Hard disk capacities per dollar have been flat for a few years, breaking a mostly exponential trend. Whether this is due to the October 2011 floods in Taiwan or some intrinsic technological barrier remains to be seen, but it’s a good reminder of both the merits and difficulties of decentralization.
The UTXO set and prunability
As mentioned before, bitcoin balances are equivalent to the set of unspent transaction outputs on the blockchain. Each transaction creates one or more new unspent transaction outputs. To verify a new transfer from public key A to public key B, the bitcoin client does (or did) a search across the whole blockchain for transactions involving transaction outputs involving public key A, to verify that the unspent transaction output referenced in the transfer is truly unspent.
A possible optimization to this protocol is simply to store the set of (currently) unspent transaction outputs, rather than the whole blockchain history. The UTXO set is about 500 Mb in size (The chainstate/* directory on my machine is about 550M, but that includes metadata.), and therefore fits in memory. Its growth probably tracks the size of the entire blockchain. One can use advanced data structures similar to Patricia trees to ensure that data encoding is efficient and that lookups are very fast. “Prunability” refers to the property of transactions that aren’t spendable — perhaps they encode metadata or contain bitcoins that were intentionally “burnt” — to be removed from the UTXO set. The OP_RETURN operator is intended to allow the storage of a small amount of metadata (40 bytes) in a transaction. A script consisting only of an OP_RETURN is obviously a data storage operation that can be provably pruned from the UTXO set.
Light clients
Light clients allow the end user to interact with the bitcoin blockchain and to make and confirm transactions without committing the disk space and without the user experience overhead headache. Light clients do not store the whole bitcoin blockchain, nor even the UTXO set. Rather, light clients allow users to receive lightweight proofs of the existence of certain UTXOs from miners, thus allowing the users to verify their balances. Light clients assume a certain amount of trust in miners to significantly reduce resource overhead.
Multiple chains, sharding and merge mining
Suppose that a killer app emerges that massively increases the bitcoin transaction volume, far beyond the exponent predicted above. What could we do then, to allow the average user to still run the full verification algorithm and be assured of his bitcoin holdings? One approach is a partial-sharding of the blockchain. Before we start rolling out the distributed hash tables, we assert that content-addressable solutions to blockchain storage are not immediately applicable. The reason is that distributed responsibility schemes are not sybil proof – such schemes allow actors to be the judge in their own case(s), so to speak, by pretending to be many distinct identities.
We could potentially shard the blockchain by replacing it with many independent blockchains, interoperating in a semi-trusted manner via cross-chain miners. Cross-chain miners would facilitate transfers across different chains and respond to requests for lightweight proofs of the existence of transactions on distant chains. The end user could run a full mining and validating client on his main chain (perhaps coded geographically or otherwise) and could run light clients on other chains of interest.
Assuming that all these chains are mined, this brings up the immediate problem of security. The argument goes as follows — suppose there is a fixed universe of computational power to secure all the chains, and consider two scenarios:
- There exists one bloated blockchain with 100% of the computational power in the universe.
- There exist 100 lightweight blockchains each with 1% of the computational power in the universe.
In the second scenario, it would only take 1% of the computational power in the universe to 51% attack a given chain — to computationally “overpower” one of the honest 99.
A possible solution to this problem is merge-mining. Merge-mining refers to the possibility of mining blocks simultaneously across different chains. Namecoin, a sort of blockchain-based DNS protocol, is merge-mined. One approach that has been suggested for scalability is for there to exist 100 lightweight blockchains that are separate, but merge-mined with each other for security. However, the problem is that in this setup, all miners would need to keep track of all 100 blockchains (or at least a majority of them) for the merge-mining to be secure, and at this point there once again arises the need for a class of nodes to exist that process nearly every transaction, so we are right back at square one. Thus, merge-mining doesn’t actually allow us to shard the blockchain; the tradeoff above appears intrinsic.
Advanced sharding
More advanced forms of sharding that attempt to ensure that every individual “shard” of the blockchain is implicitly protected by a large part of the strength of the entire system do exist, but with only a very small portion of the network explicitly watching each shard by default. Such schemes might involve some combination of multiple strategies. One approach is challenge-response protocols, where if a particular transaction is invalid, some node can “call attention” to the invalidity and either provide an efficiently verifiable proof that a transaction is invalid, or produce a “challenge” that must be met by a “response” in the form of some kind of efficiently verifiable proof of validity.
Another approach, applicable only to proof-of-stake algorithms, is the idea of randomly selecting, and often reshuffling, the set of miners (in proof of stake, typically called “voters” or “validators”) for a shard from a very large set taken from the entire blockchain. This means that an attacker would need to take over a substantial percentage of the entire blockchain in order to successfully corrupt even one shard, but at the same time only a very small number of validators need to actually process every transaction.
A third category of approaches involves techniques from advanced cryptography, involving a category of technology called “zero-knowledge proofs.” A few approaches exist that have been very recently developed to allow you to create cryptographic proofs that a particular computation has a particular output, and these proofs can be verified very quickly without running the actual computation. This technique can potentially be used for proving block validity, though it is important to note that even with such schemes “data availability” problems might still remain in place; attackers trying to harm the network could produce blocks that are valid, and provably so, but deliberately not publish some of the information in the blocks in an attempt to throw off others. Solutions to this problem will differ depending on the specific approach.
Bandwidth
An average bitcoin transaction is about 250 bytes. A cable modem, running optimally at 10 megabits per second can therefore facilitate 5,000 bitcoin transactions per second. Bitcoin is nowhere near this bandwidth cap.
Bitcoin blocks are hard-capped at 1 MB in size. Considering the amount of data that each transaction creates and the fact that the mining algorithm is set up to allow a new block every 10 minutes (on average), this implies a theoretical limit of about seven transactions per second. When bitcoin transaction volume starts to push that limit, we might see fees go up or possibly changes to the bitcoin core. This would require a hard fork, which is generally considered undesirable.
Conclusion
Blockchain scalability is an essential set of issues that must be tackled as blockchain technologies become more popular. It’s particularly difficult to build for scalability and to maintain backward compatibility. Solutions are being proposed, in academic papers and whitepapers, but we’ll have to wait and see what really works.