
 Virtual reality (source: Pixabay)
Virtual reality (source: Pixabay) In this post I share slides and notes from a keynote I gave at the Strata Data Conference in London at the end of May. My goal was to remind the data community about the many interesting opportunities and challenges in data itself. Much of the focus of recent press coverage has been on algorithms and models, specifically the expanding utility of deep learning. Because large deep learning architectures are quite data hungry, the importance of data has grown even more. In this short talk, I describe some interesting trends in how data is valued, collected, and shared.
Economic value of data
It’s no secret that companies place a lot of value on data and the data pipelines that produce key features. In the early phases of adopting machine learning (ML), companies focus on making sure they have sufficient amount of labeled (training) data for the applications they want to tackle. They then investigate additional data sources that they can use to augment their existing data. In fact, among many practitioners, data remains more valuable than models (many talk openly about what models they use, but are reticent to discuss the features they feed into those models).
But if data is precious, how do we go about estimating its value? For those among us who build machine learning models, we can estimate the value of data by examining the cost of acquiring training data:

- Many of us at some point in our data science work have augmented our existing data sets with external data sources that we paid for. Data providers like Bloomberg, Nielsen, Dun & Bradstreet, and more recent entrants like Planet Labs offer subscription services for a variety of data sets.
- We also know exactly how much it costs to build training data sets from scratch. With the rise of data-hungry methods like deep learning, there is growing demand for services like Figure Eight and Mighty AI that help companies label images, video, and other data sources.
- For specific data types (like images), there are new companies like Neuromation, DataGen, and AI.Reverie, that can help lower the cost of training data through tools for generating synthetic data.
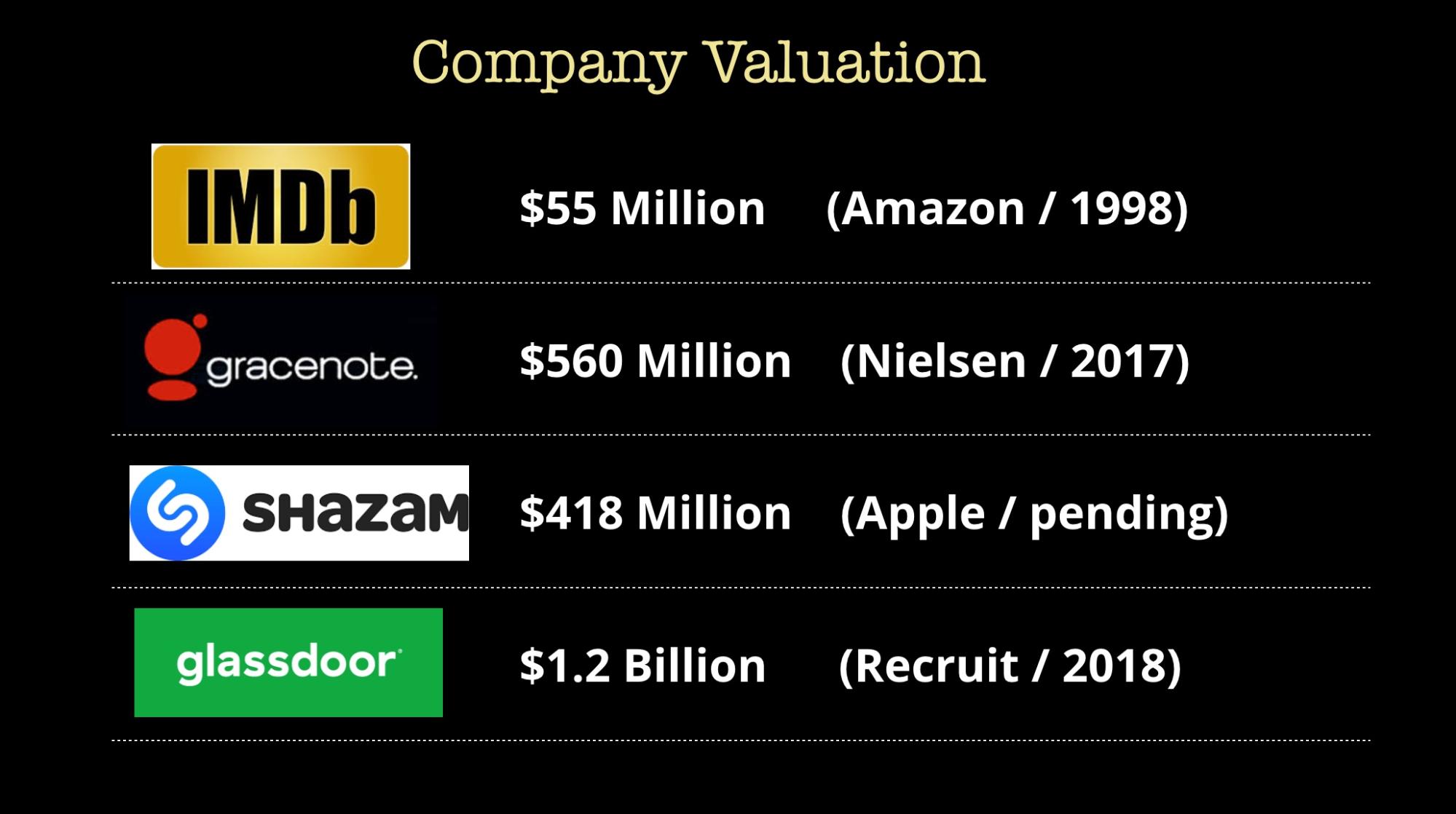
Another way we can glean the value of data is to look at the valuation of startups that are known mainly for their data sets. I list a few examples from the media industry, but there are are numerous new startups that collect aerial imagery, weather data, in-game sports data, and logistics data, among other things. If you are an aspiring entrepreneur, note that you can build interesting and highly valued companies by focusing on data.
The reason data scientists and data engineers want more data is so they can measure its impact on their data products. This leads to another way one can estimate the value of data: by observing the incremental impact of new data sources on existing data products.
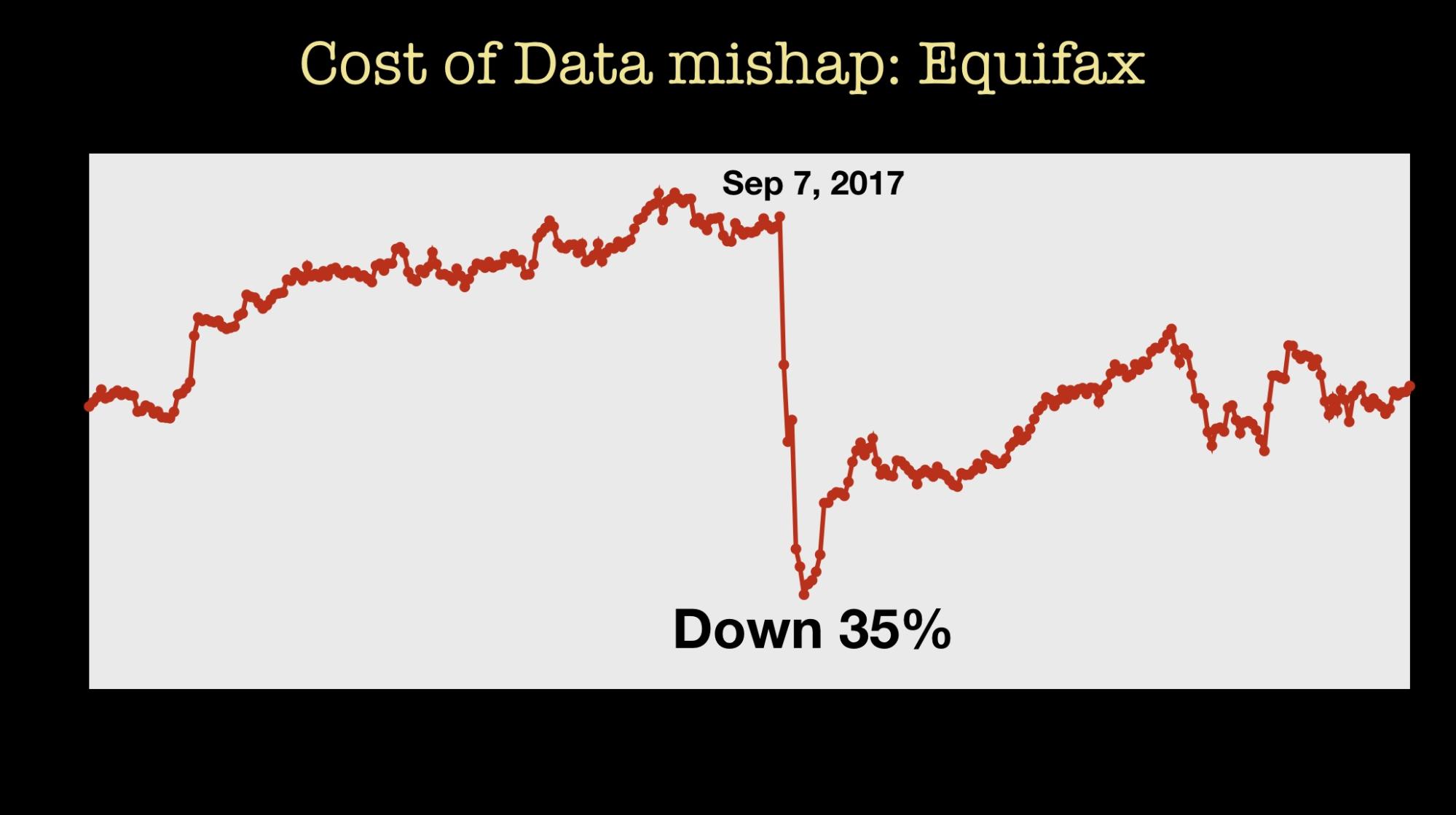
Relying on external data is not without risks. A security breach and other technical reasons might lead to your supply of data being cut off. A more likely reason is that because concerns about data collection and data privacy have gotten stronger, sharing and selling data has come under more scrutiny. Loss of access can also indirectly demonstrate how valuable data is:
- the impact of a data mishap on a company’s market cap is observable
- the impact of “loss of access” to a data source on your ML models is something you can measure
The state of data privacy: Views of key stakeholders
In recent months, we have had a change in expectations and attitudes around data privacy and data collection. Let’s examine the current situation from the perspective of some key stakeholders: users, regulators, companies, and data professionals.
User expectations for what happens to data they generate has changed. In light of recent headlines (Facebook and Cambridge Analytica), the general public is much more aware of data collection, storage, and sharing. Concerns about data privacy cut across countries, and contrary to popular perception, data privacy is a growing concern among Chinese users. The conversation has gone beyond data privacy; users are calling for:
- better transparency–they want to know what data is being collected and with whom data is being shared
- control over how their data is shared and used
- limits on the nature and duration of data sharing
Regulators across many countries and localities are moving forward with landmark legislation: Europe (GDPR) and California (Consumer Privacy Act) have placed concepts like “user control” and “privacy-by-design” at the forefront for companies wanting to deploy analytic products. Australia recently added data breach notification to its existing data privacy rules.
Stance on data privacy and data monetization is becoming a competitive angle for some small and large firms. Apple in particular is raising the bar on data privacy and collection, but other companies are following suit (companies in China are also beginning to send similar signals to users). Moving forward, companies are going to have to adjust their services–not only in light of regulations, but also the changing expectations of users.
Data professionals are also taking data privacy very seriously. Many have implemented training programs within their companies, and some are already exploring new privacy-preserving tools and methods for building analytic products. Going beyond privacy, the next-generation data scientists and data engineers are undergoing training and engaging in discussions pertaining to ethics. Many Universities are offering courses, some like UC Berkeley have multiple courses.

Data liquidity in an age of privacy: New data exchanges
We are now operating during a period of heightened awareness about data privacy and user control. How do we continue to provide liquidity in an age when machine learning models require so much data?
Many organizations maintain data silos: separate systems that limit access between internal teams, and systems that store data they aren’t willing to share with external users. At the same time, companies usually have data they would be willing to share with others. The problem is that there aren’t convenient mechanisms or common formats for making sharing easy. Imagine if there are tools and mechanisms to make these data sets sharable (through a data commons). This would mean that individual data silos can now sit on a strong foundation of external data which all participating organizations can use to augment their ML models.

In a 2017 post, Roger Chen described the three major approaches companies have taken when building data exchanges (or “data networks”):
- Open data: lack of market incentives make the open data model hard to scale, and they can be particularly prone to challenges with data heterogeneity.
- Data cooperative: requires the most amount of trust and suffers from cold start challenges. With that said, there has been great progress building tools for data commons in the biomedical arena, and lessons learned in that domain should translate to other fields.
- Data brokerage: participants gain financial reward for aggregating and selling data, which potentially leads to more scale and liquidity.
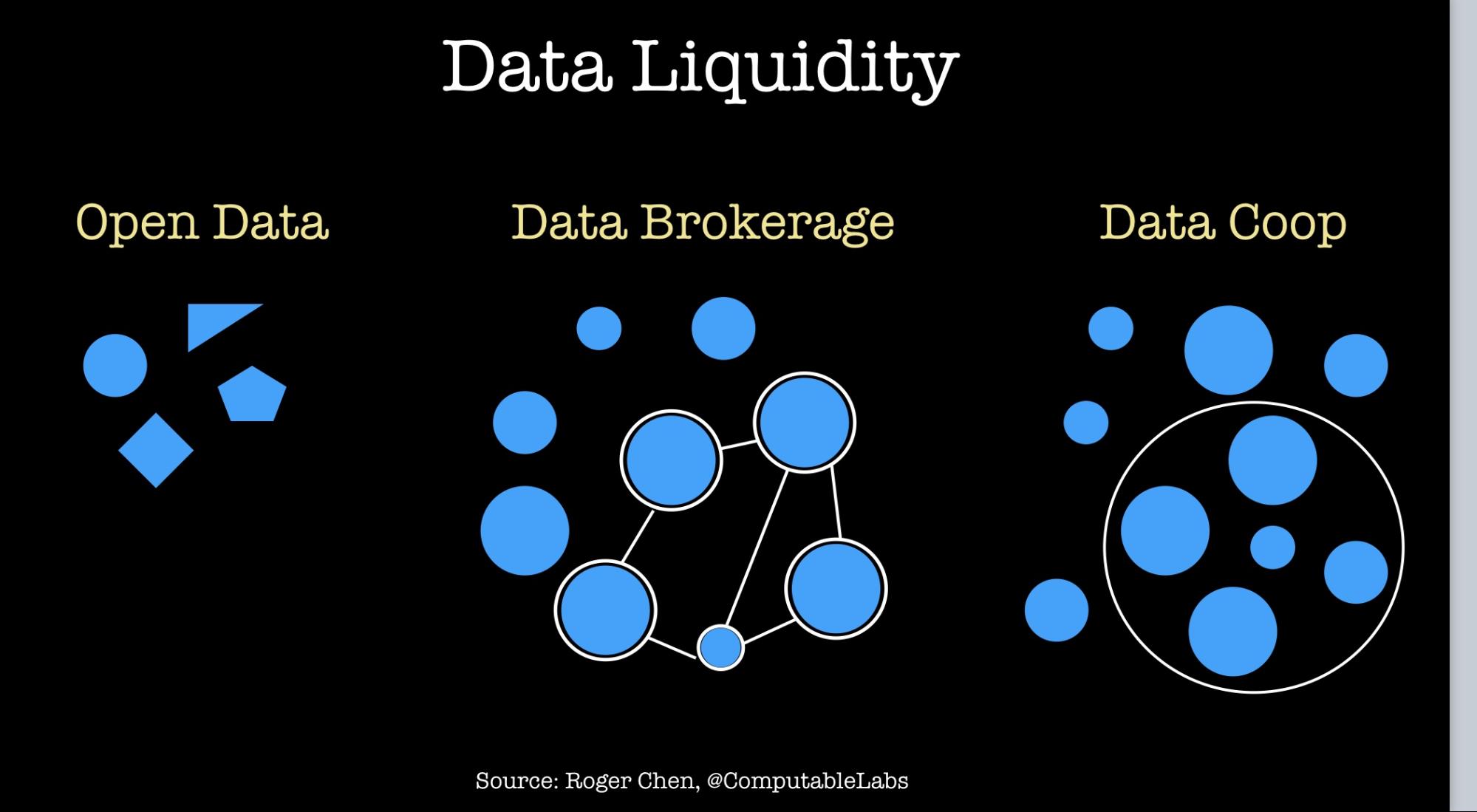
One trend that I’ve come across recently is decentralized data networks. The idea is to build data exchanges that are decentralized using technology based on blockchains and distributed ledgers, and an incentive structure that uses cryptocurrencies. Some startups in this space are specifically targeting machine learning–they aspire to enable data scientists to “train models without seeing the data.”
The most interesting initiative comes from a San Francisco startup called Computable Labs. They are building open source, decentralized infrastructure that will allow companies to securely share data and models. In the process, they want to “make blockchain networks compatible with machine learning computations.”
Closing thoughts

While models and algorithms garner most of the media coverage, this is a great time to be thinking about building tools in data. We are in an age when machine learning models demand huge amounts of data, and many companies have just begun deploying ML models. There are the core topics of security and privacy, but there are many other compelling and challenging problems and opportunities that touch on ethics, economic value, data liquidity, user control, and decentralization.
Related resources:
- “Building a stronger data ecosystem”
- Decentralized data markets for training AI models
- “Data liquidity in the age of inference”
- “How to build analytic products in an age when data privacy has become critical”
- ”Data regulations and privacy discussions are still in the early stages”: Aurélie Pols on GDPR, ethics, and ePrivacy.
- “Managing risk in machine learning models”: Andrew Burt and Steven Touw on how companies can manage models they cannot fully explain.