

In this episode of the Data Show, I spoke with Lukas Biewald, co-founder and chief data scientist at CrowdFlower. In a previous episode we covered how the rise of deep learning is fueling the need for large labeled data sets and high-performance computing systems. CrowdFlower has a service that many leading companies have come to rely on to provide them with labeled data sets to train machine learning models. As deep learning models get larger and more complex, they require training data sets that are bigger than those required by other machine learning techniques.
The CrowdFlower platform combines the contributions of human workers and algorithms. Through a process called active learning, they send difficult tasks or edge cases to humans, and they let the algorithms handle the more routine examples. But, how do you decide when to use human workers? In a simple example involving building an automatic classifier, you will probably want to send human workers cases when your machine learning algorithms signal uncertainty (probability scores are on the low side) or when your ensemble of machine learning algorithms signals disagreement. As Biewald describes in our conversation, active learning is much more subtle, and the CrowdFlower platform, in particular, is able to combine humans and algorithms to handle more sophisticated tasks.
Here are some highlights from our conversation:
The growing importance of labeled data sets
For CrowdFlower, deep learning has been fantastic because it usually means companies need even more training data. We’re really in the business of getting people training data. So, I guess I view deep learning not as this revolutionary change, but as an extension of machine learning: where all the things that were good about machine learning become even better, and all the things that were hard are even harder. As an example, it’s even harder to figure out what the models are doing. To make it work, you typically need even more training data. In the past, our customers would typically ask for hundreds of thousands, or millions, of records in their training data sets. We began noticing deep learning when we started having customers who would ask for tens of millions of data rows right off the bat. We started asking, “Why do these people want so much label data?” I think we started to notice this two or three years ago.
… I would say all the big companies are spending millions of dollars on collecting training data. When companies are spending millions or more dollars on training data, it’s absolutely essential that they do it in a smart way. Active learning is the best thing to do.
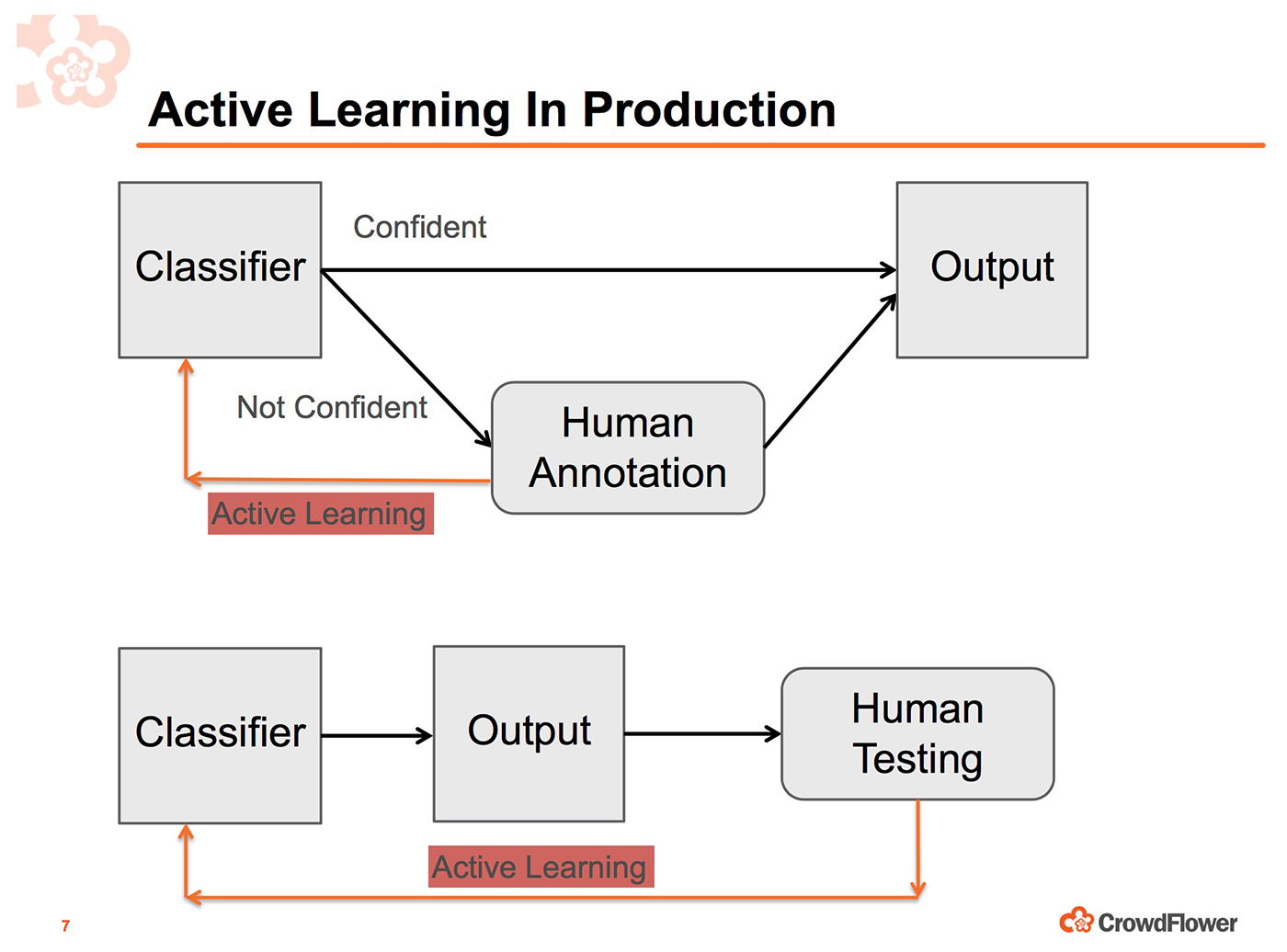
Active learning and object detection
There’s a real role the algorithms can play in terms of helping the humans be more efficient. The best example is a lot of companies these days need to do image segmentation: this is where you want to literally label every single pixel in an image. A common use case, for example, is to label every pedestrian. So, you look at a photo, probably from a self-driving car of what it’s seeing in its dashboard camera. You want to pick out which pixels correspond to pedestrians, which pixels correspond to roads, which pixels correspond to sidewalk, and so on.
If you just have someone open up Photoshop and try to do that, you can image that labeling process could take more than an hour. That really is the state of the art. We find customers that literally are doing that. They buy a bunch of Photoshop licenses, and they have an army of interns just opening up the photos in Photoshop and putting masks on them to get the label data. You can imagine the cost of that quickly adds up.
The first thing you can do, which I think everyone should do, is you can try to group the pixels into chunks. Photoshop has a magic wand tool for editing, where it tries to figure out what are continuous blocks of pixels. But you can actually pre-segment those blocks into chunks. That makes people a lot more efficient. That means that if your algorithm is reasonably good, it will do a lot of the labeling for the person. It can really cut down the labeling time from more than an hour to a couple minutes. That’s a huge deal.
Related:
- Lukas Biewald is giving a keynote and talk on “Active Learning in the Real-world” at Strata Data Beijing, July 12-15, 2017.
- Biewald also has written a series of posts on applications of deep learning, including “How to build a robot that “sees” with $100 and TensorFlow” and “Build a talking, face-recognizing doorbell for about $100”
- Active Learning: best practices for creating labeled data sets (a 2014 webcast featuring Biewald)
- “Building human-assisted AI applications,” by Adam Marcus