
 Soundwave. (source: Pixabay)
Soundwave. (source: Pixabay) The dream of speech recognition is a system that truly understands humans speaking—in different environments, with a variety of accents and languages. For decades, people tackled this problem with no success. Pinpointing effective strategies for creating such a system seemed impossible.
In the past years, however, breakthroughs in AI and deep learning have changed everything in the quest for speech recognition. Applying deep learning techniques enabled remarkable results. Today, we see the leap forward in development manifesting in a wide range of products, such as Amazon Echo, Apple Siri, and many more. In this post, I’ll review recent advances in speech recognition, examine the elements that have contributed to the rapid progress, and discuss the futureand how far we may be from solving the problem completely.
A little background
For years, one of the most important tasks of AI has been to understand humans. People want machines to understand not only what they say but also what they mean, and to take particular actions based on that information. This goal is the essence of conversational AI.
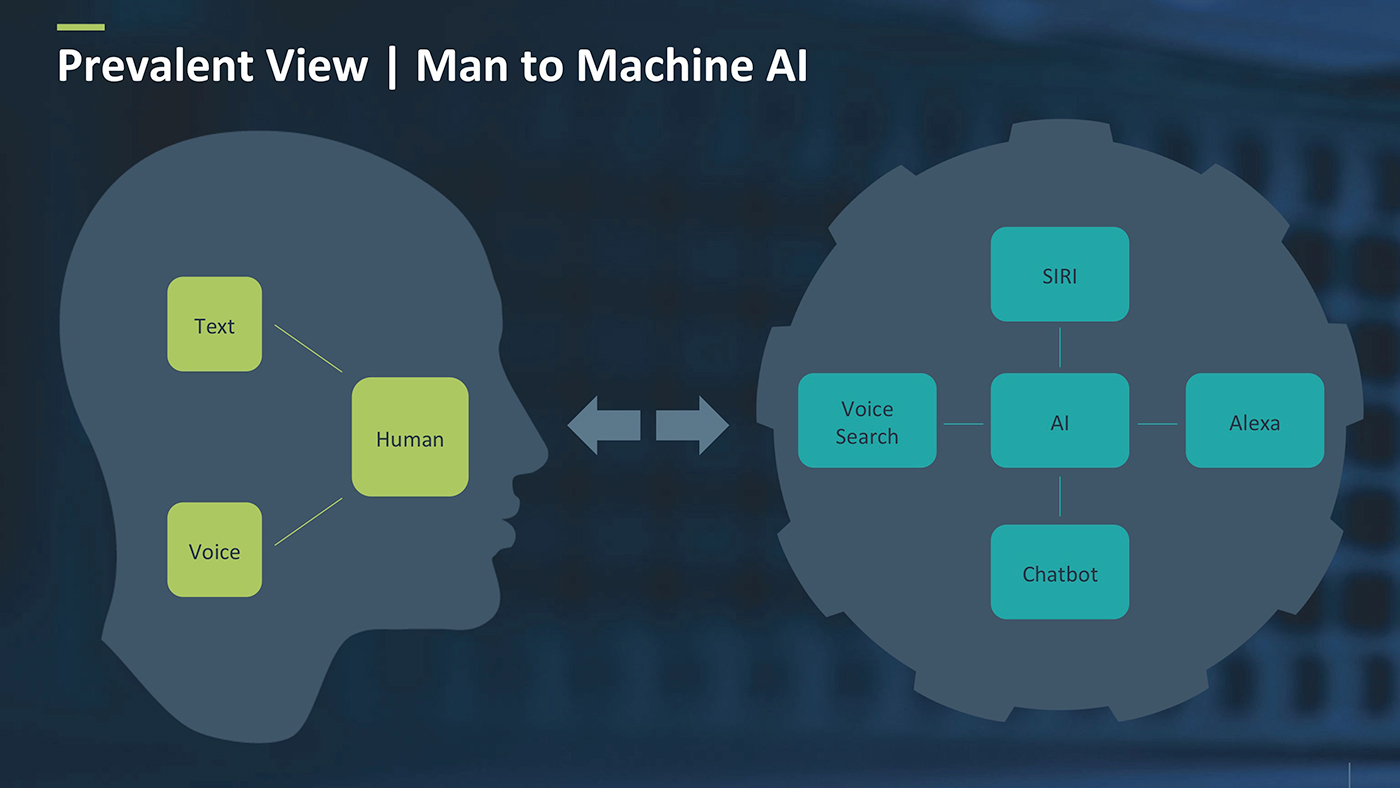
Conversational AI encompasses two main categories: man-machine interface, and human-to-human interface. In a man-machine interface, a human interacts with a machine through voice or text, and the machine understands the human (even if in a limited manner), and takes some kind of action. Figure 1 demonstrates that the machine can be either a personal assistant (SIRI, Alexa, or similar) or some kind of chatbot.
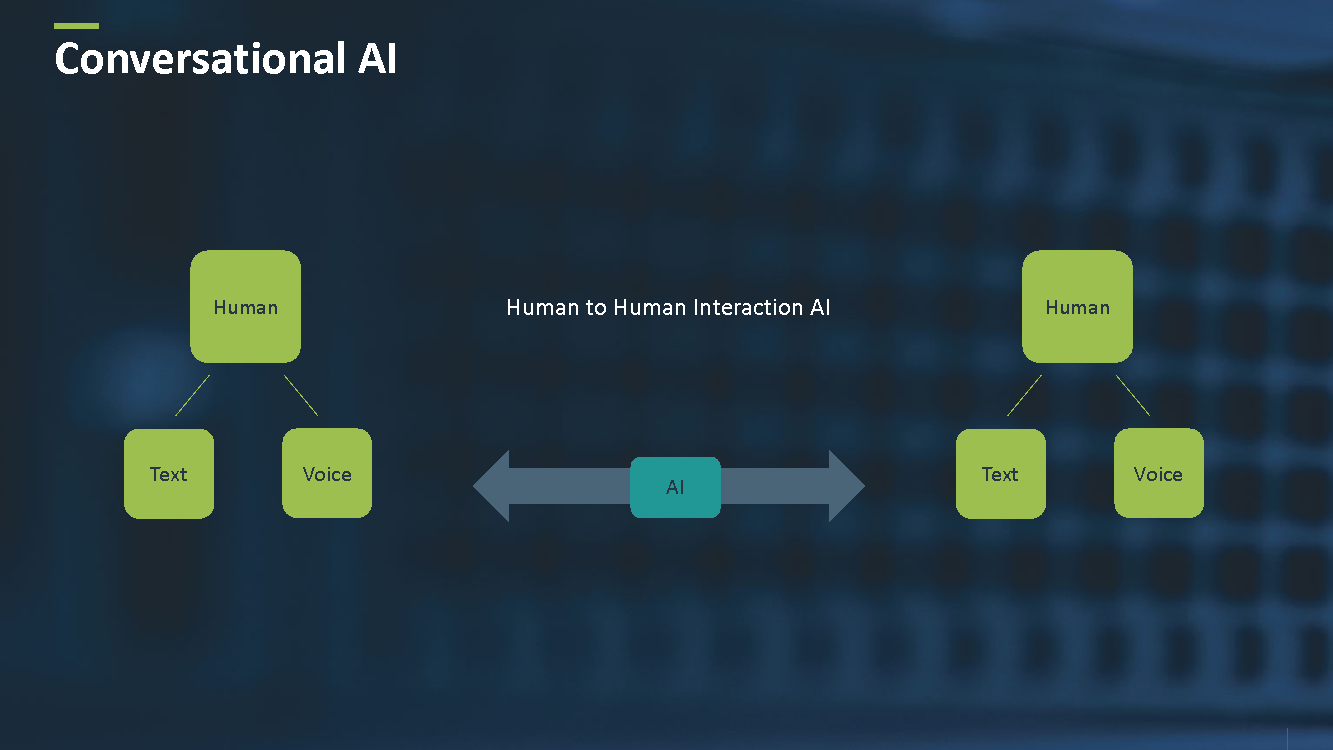
In a human-to-human interaction, the AI forms a bridge between two or more humans having conversations, interacting, or creating insights (see Figure 2). An example might be an AI that listens to conference calls, then creates a summary of the call, following up with the relevant people.
Machine perception and cognition
In order to understand the challenges and the technologies behind conversational AI, we must examine the basic concepts in AI: machine perception and machine cognition.
Machine perception is the ability of a machine to analyze data in a manner similar to the way humans use their senses to relate to the world around them; in other words, essentially giving a machine human senses. A lot of the recent AI algorithms that employ computer cameras, such as object detection and recognition, fall into the category of machine perception—they concern the sense of vision. Speech recognition and profiling are machine perception technologies that use the sense of hearing.
Machine cognition is the reasoning on top of the metadata generated from the machine perception. Machine cognition includes decision-making, expert systems, action taking, user intent, and more. Generally, without machine cognition, there isn’t any impact from the outcome of the AI’s perception; machine perception delivers the proper metadata information for a decision and action.
In conversational AI, machine perception includes all speech analysis technologies, such as recognition and profiling, and machine cognition includes all the language understanding-related technologies, which are part of Natural Language Processing (NLP).
The evolution of speech recognition
The research and development of speech recognition occurred over three major time periods:
Before 2011
Active research on speech recognition has been taking place for decades; in fact, even in the 1950s and 1960s, there were attempts to build speech recognition systems. However, before 2011 and the advent of deep learning, big data, and cloud computing, these solutions were far from sufficient for mass adoptions and commercial use. Essentially, the algorithms were not good enough, there was not enough data on which to train the algorithms, and the lack of available high-performance computing prevented researchers from running more complicated experiments.
2011 – 2014
The first major effect of deep learning occurred in 2011, when a group of researchers from Microsoft, Li Deng, Dong Yu, and Alex Acero, together with Geoffrey Hinton and his student George Dahl, created the first speech recognition system that is based on deep learning. The impact was immediate: more than 25% relative reduction in the error rate. This system was the starting point for massive developments and improvements in the fields. Together with more data, available cloud computing, and adoption from big companies like Apple (SIRI), Amazon (Alexa), and Google, there were significant improvements in the performance and the products released to the market.
2015 – Today
At the end of 2014, recurrent neural networks gained much more emphasis. Together with attention models, memory networks, and other techniques, this era comprised the third wave of progress. Today, almost every type of algorithm or solution uses some type of neural model, and, in fact, almost all of research in speech has shifted toward deep learning.
Recent advances of neural models in speech
The past six years of speech recognition has created more breakthroughs then the previous 40+ years. This extraordinary recent advancement is due to neural networks. In order to understand the impact of deep learning and the part it plays, we need to understand first how speech recognition works.
Although speech recognition has been in active research for almost 50 years, building machines that understand human speech is one of the most challenging problems in AI. It’s much harder then it may appear. Speech recognition consists of well-defined tasks: given some kind human speech, try to convert the speech into words. However, the speech can be part of a noisy signal, requiring the work of extracting the speech from the noise and converting the relevant parts into meaningful words.
The basic building blocks of a speech recognition system
Speech recognition is basically divided into three main sections:
The signal level: The aim of the signal level is to extract speech from the signal, enhance it (if needed), do proper pre-processing and cleaning, and feature extraction. This level is very similar to every machine learning task; in other words, given some data, we need to do proper data pre-processing and feature extraction.
The acoustic level: The aim of the acoustic level is to classify the features into different sounds. Put another way, sounds themselves do not provide a precise enough criteria, but rather sub-sounds that are sometimes called acoustic states.
The language level: Since we assume the sounds are produced by a human and have meaning, we take the sounds, combine them into words, and then take the words and combine them into sentences. These techniques in the language levels are usually different types of NLP techniques.
Improvements from deep learning
Deep learning made a significant impact on the field of speech recognition. The impact is so far-reaching that even today, almost every solution in the field of speech recognition probably has one or more neural-based algorithms embedded within it.
Usually the evaluation of speech recognition systems is based on an industry standard called Switchboard (SWBD). SWBD is a corpus of speech assembled from conversations improvised over the phone. SWBD includes audio and human-level transcriptions.
The evaluation of a speech recognition system is based on a metric called word error rate (WER). WER refers to how many words are misrecognized by the speech recognition system. Figure 3 shows the improvement in WER from 2008 – 2017.
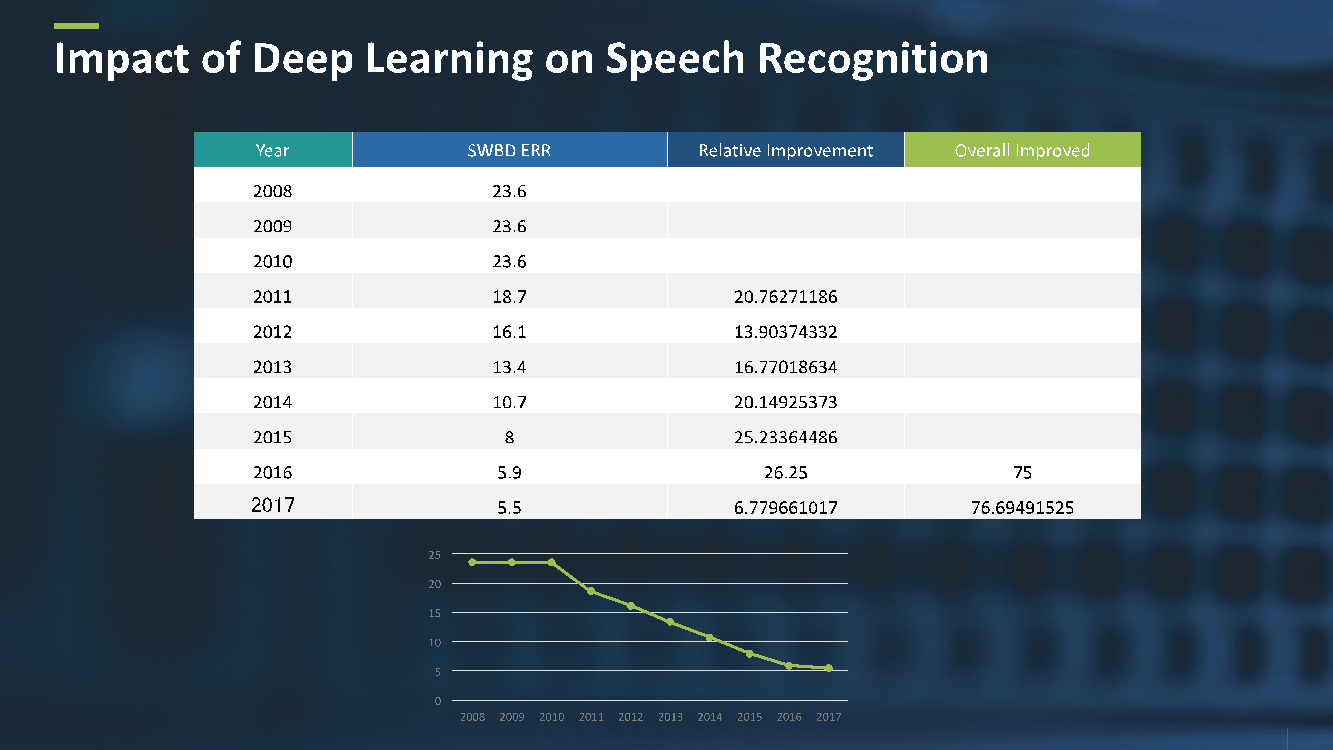
From 2008 to 2011, the WER was in a steady state, around 23 to 24%; deep learning started to appear in 2011; and as a result, reduced the WER from 23.6% to 5.5%. This development was a game changer for speech recognition, an almost 77% relative improvement. Now there are a wide range of applications, such as Apple SIRI, Amazon Alexa, Microsoft Cortana, and Google Now. We also see a variety of appliances activated by speech recognition, such as Amazon Echo and Google Home.
The secret sauce
So, what improved the system so drastically? Is there a technique that reduced the WER from 23.6% to 5.5%? Unfortunately, there isn’t a single method. Deep learning and speech recognition are so entangled that creating a state-of-the-art system involves a variety of different techniques and methods.
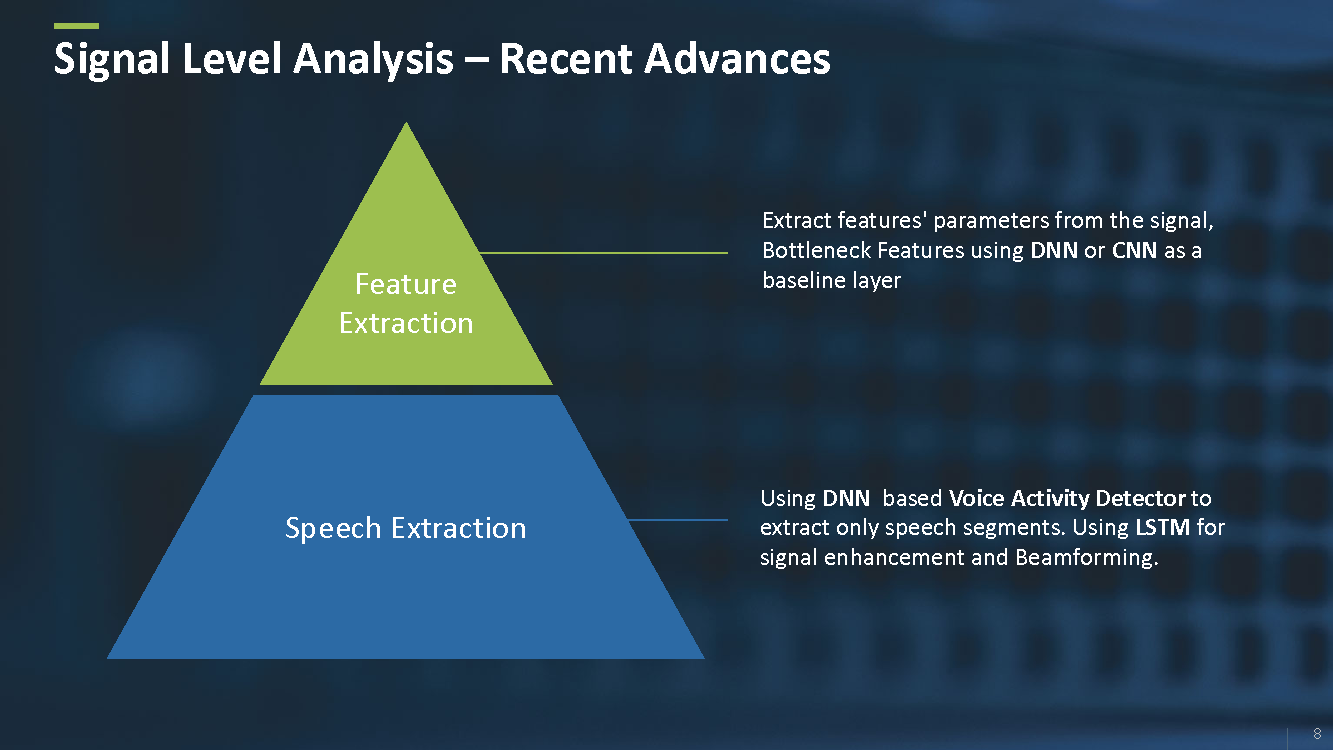
At the signal level, for instance, there are different neural-based techniques to extract and enhance the speech from the signal itself (Figure 4). Also, there are techniques that replace the classical feature extraction methods with more complex and efficient neural-based methods.
The acoustic and language levels also encapsulate a variety of different deep learning techniques, from acoustic state classification using different types of neural-based architectures to neural-based language models in the language level (see Figure 5).
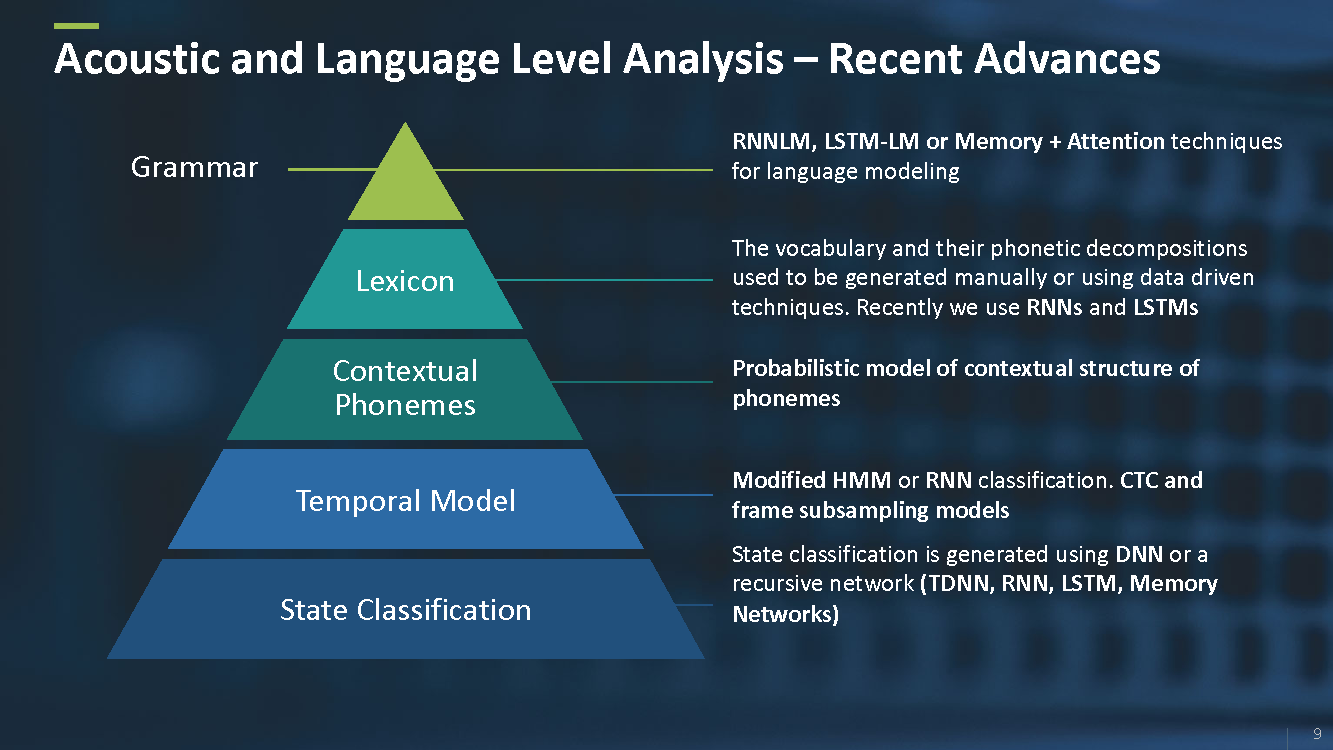
Creating a state-of-the-art system is not an easy task, and building it involves implementing and integrating all these different techniques into the system.
Cutting edge research
With so many recent breakthroughs in speech recognition, it’s natural to ask, what’s next? Three primary areas seem likely to be the main focus of research in the near future: algorithms, data, and scalability.
Algorithms
With the success of Amazon Echo and Google Home, many companies are releasing smart speakers and home devices that understand speech. These devices introduce a new problem, however: the user is often not talking closely into a microphone, as with a mobile phone, for instance. Dealing with distant speech is a challenging problem that is being actively researched by a lot of groups. Today, innovative deep learning and signal processing techniques can improve the quality of recognition.
One of the most interesting topics of research today is finding new and exotic topologies of neural networks. We see some promising results both in language models and acoustic models that are being applied. Two examples are Grid-LSTM in acoustic models and attention-based memory networks for language models.
Data
One of the key issues in a speech recognition system is the lack of real-life data. For example, it is hard to get high-quality data of distance speech. However, there is a lot of available data from other sources. One question is: can we create proper synthesizers to generate data for training? Generating synthesized data and training systems based on that is getting good attention today.
In order to train a speech recognition system, we need data sets that have both audio and transcriptions. Manual transcription is tedious work and sometimes can cause problems on large amounts of audio. As a result, there is active research on semi-supervised training and building proper confidence measure for the recognizers.
Scalability
Since deep learning is so entangled with speech recognition, it consumes a non-trivial amount of CPU and memory. With users’ massive adoption of speech recognition systems, building a cost-effective cloud solution is a challenging and important problem. There is ongoing research into how to reduce the computation cost and develop more efficient solutions. Today, most speech recognition systems are cloud-based, and have two specific issues that must be solved: latency and continuous connectivity. Latency is a key issue in devices that need an immediate response, such as robotics. And in a system that is listening all the time, continuous connectivity is a problem due to bandwidth cost. As a result, there is research toward edge speech recognition that preserves the quality of a cloud-based system.
Solving the problems of speech recognition
In the recent years, there has been a quantum leap in speech recognition performance and adoption. How far are we from solving it completely? Are we five years, or maybe 10 from declaring victory? The answer is, probably—but there are still challenging problems that will take some time to solve.
The first problem is the issue of sensitivity to noise. A speech recognition system works pretty well from a close microphone and non-noisy environment; however, distant speech and noisy data degrades the system rapidly. The second problem that must be addressed is language expansion: there are roughly 7,000 languages in the world, and most speech recognition systems support around 80. Scaling the systems poses a tremendous challenge. In addition, we lack data on many languages, and a speech recognition system is difficult to create with low data resources.
Conclusion
Deep learning has made its mark on speech recognition and conversational AI. Due to recent breakthroughs, we are truly on the edge of a revolution. The big question is, are we going to achieve a triumph, solve the challenges of speech recognition, and begin to use it like any other commoditized technology? Or is a new solution waiting to be discovered? After all, the recent advances in speech recognition are just one piece of the puzzle: language understanding itself is a complex mystery—maybe an even greater one.