
 10 iterations of applying DeepDream (source: MartinThoma on Wikimedia Commons)
10 iterations of applying DeepDream (source: MartinThoma on Wikimedia Commons) If you ask a child to draw a cat, you’ll learn more about the child than you will about cats. In the same way, asking neural networks to generate images helps us see how they reason about the information they’re given. It’s often difficult to interpret neural networks—that is, to relate their functioning to human intuition—and generative algorithms offer a way to make neural nets explain themselves.
Neural networks are most commonly implemented as classifiers—models that are able to distinguish, say, an image of a cat from an image of a dog, or a stop sign from a fire hydrant. But over the last three years, researchers have made astonishing progress in essentially reversing these networks. Through a handful of generative techniques, it’s possible to feed a lot of images into a neural network and then ask for a brand-new image that resembles the ones it’s been shown. Generative AI has turned out to be remarkably good at imitating human creativity at superficial levels.
The current wave of generative AI research builds on the generative adversarial network, or GAN, a neural network structure introduced by Ian Goodfellow and his collaborators in 2014. A flowering of inventive applications followed their paper. Researchers have generated images of everything from faces to bedrooms. Through a GAN-based technique called pix2pix, satellite images become maps, black-and-white photos become colorized, and simple sketches become realistic renderings. Enhancing blurry, low-resolution images—a much-mocked fantasy in police procedurals—has become a reality through GANs, which are able to make sophisticated assumptions about likely structure in photographs.

A generative adversarial network consists of two neural networks: a generator that learns to produce some kind of data (such as images) and a discriminator that learns to distinguish “fake” data created by the generator from “real” data samples (such as photos taken in the real world). The generator and the discriminator have opposing training objectives: the discriminator’s goal is to accurately classify real and fake data; the generator’s goal is to produce fake data the discriminator can’t distinguish from real data.
In our new Oriole interactive tutorial, Adit Deshpande and I use TensorFlow to demonstrate a very simple generative adversarial network that creates convincing images of what appear to be human handwriting. The animation below, made with images generated by our network, illustrates the GAN’s learning process. From random noise, a kind of primordial intelligence emerges: first the network generates the same generic pseudo-numeral repeatedly, then it grasps the variation among digits, and finally diverges into creating every digit in a full range of styles. In the breadth of its creativity, we can read the depth of its understanding.

Neural networks are good at making simple inferences on rich data; with multiple layers of neurons, they’re able to organize themselves to detect patterns at multiple levels, from fragments of texture down to fundamental structure, and they can catch patterns that a human might miss. This is both their strength and the source of some difficulty. Neural networks can notice patterns that humans can’t, but they can also develop poorly reasoned heuristics just like humans would if they have insufficiently sophisticated network structure or if they’re trained on data that’s not broad enough to represent real-world variation.
Simple statistical models like multivariate linear regressions are easy to interpret: they function directly enough that a human observer can grasp their reasoning at a glance. But neural networks with multiple layers aren’t so intuitive; they organize themselves freely to identify variations in the data they’re trained on, and the way layers feed into each other obfuscates their functioning.
Indeed, this resembles human reasoning. Look at a photo of a cat: could you explicitly identify every piece of evidence that you used to determine that you’re looking at a cat? Your conclusion comes from a variety of signals that you can evaluate quickly: the shape of the cat’s ears, its whiskers, certain patterns of fur. Collectively, those signals tell you that you’re looking at a cat.
Generative neural networks are convincing at reconstructing information thanks to their ability to understand information at multiple levels. It’s hard to overstate how remarkable these GAN-generated images of bedrooms are; not only do the sheets, carpets, and windows look convincing, but the high-level structures of the rooms are correct: the sheets are on the beds, the beds are on the floors, and the windows are on the walls.

If you’ve worked with image recognition, you’re probably familiar with convolutional neurons, which scan filters across images to detect patterns. Convolutional layers usually scale data down, but in the generator portion of this model we essentially reverse the usual convolution process in order to scale data up—going from a compact representation (z, a vector of 100 values between 0 and 1) to a less compact representation (a 28 pixel x 28 pixel image, or a total of 768 values between 0 and 1).
Instead of detecting patterns and matching them to features in an image, the generator uses transpose convolution to identify fundamental image building-blocks and learns to assemble and blend these building-blocks into convincing images. For instance, our GAN generated this remarkably convincing image of the numeral 9:
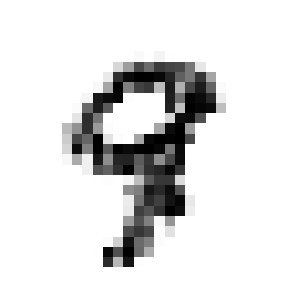
By looking at some of the transpose convolution filters and their corresponding outputs, we can identify a few of the building-blocks from which the final transpose convolution layer assembled the image above.

GANs are only three years old; it’s easy to imagine they might soon be used to generate a variety of content—perhaps even images or videos customized on-the-fly for each visitor to a web site. As GANs emerge as a creative force, watch for hints to the way they reason. And start building your own GANs.
This post is a collaboration between O’Reilly and TensorFlow. See our statement of editorial independence.