
 Enterprise (source: Joel Filipe on Unsplash)
Enterprise (source: Joel Filipe on Unsplash) At Strata 2017, I premiered a new diagram to help teams understand why teams fail and when:
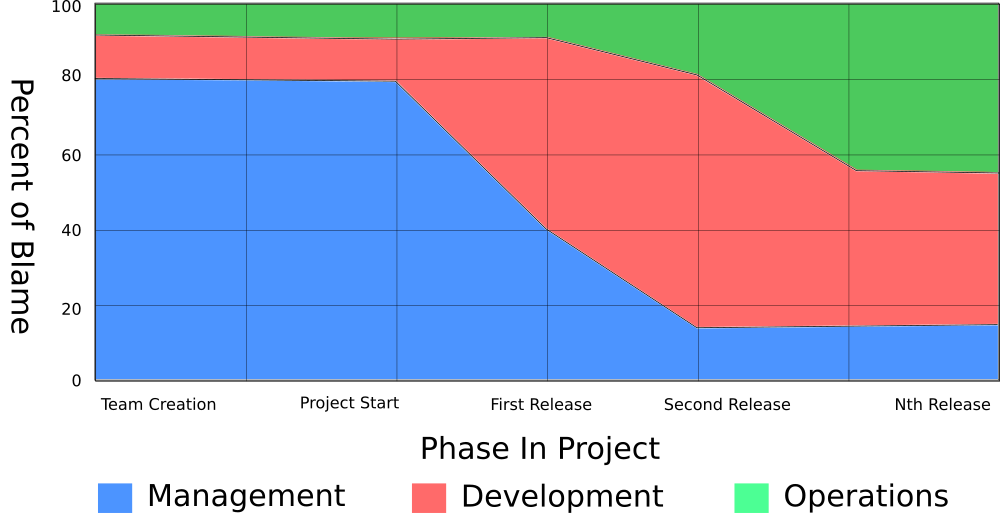
Early on in projects, management and developers are responsible for the success of a project. As the project matures, the operations team is jointly responsible for the success.
I’ve taught in situations where the operations team members complain that no one wants to do the operational side of things. They’re right. Data science is the sexy thing companies want. The data engineering and operations teams don’t get much love. The organizations don’t realize that data science stands on the shoulders of DataOps and data engineering giants.
What we need to do is give these roles a sexy title. Let’s call these operational teams that focus on big data: DataOps teams.
What does the Ops say?
Companies need to understand there is a different level of operational requirements when you’re exposing a data pipeline. A data pipeline needs love and attention. For big data, this isn’t just making sure cluster processes are running. A DataOps team needs to do that and keep an eye on the data.
With big data, we’re often dealing with unstructured data or data coming from unreliable sources. This means someone needs to be in charge of validating the data in some fashion. This is where organizations get into the garbage-in-garbage-out downward cycle that leads to failures. If this dirty data proliferates and propagates to other systems, we open Pandora’s box of unintended consequences. The DataOps team needs to watch out for data issues and fix them before they get copied around.
These data quality issues bring a new level of potential problems for real-time systems. Worst case, the data engineering team didn’t handle a particular issue correctly and you have a cascading failure on your hands. The DataOps team will be at the forefront of figuring out if a problem is data or code related.
Shouldn’t the data engineering team be responsible for this? Data engineers are software developers at heart. I’ve taught many and interacted with even more. I wouldn’t let 99% of data engineers I’ve met near a production system. There are several reasons why—such as a lack of operational knowledge, a lack of operational mindset, and being a bull in your production china shop. Sometimes, there are compliance issues where there has to be a separation of concerns between the development and production data. The data engineering team isn’t the right team to handle that.
That leaves us with the absolute need for a team that understands big data operations and data quality. They know how to operate the big data frameworks. They’re able to figure out the difference between a code issue and a data quality issue.
Real-time: The turbo button of big data
Now let’s press the turbo button and expand this to include batch and real-time systems.
Outages and data quality issues are painful for batch systems. With batch systems, you generally aren’t losing data. You’re falling behind in processing or acquiring data. You’ll eventually catch up and get back to your steady state of data coming in and being processed on time.
Then there’s real time. An outage for real-time systems brings a new level of pain. You’re dealing with the specter of permanently losing data. In fact, this pain during down time is how I figure out if a company really, really needs real-time systems. If I tell them they’ll need a whole new level of service level agreement (SLA) for real time and they disagree, that probably means they don’t need real time. Having operational downtime for your real-time cluster should be so absolutely painful that you will have done everything in your power to prevent an outage. An outage of your real-time systems for six hours should be a five-alarm fire.
All of this SLA onus falls squarely on the DataOps team. They won’t just be responsible for fixing things when they go wrong; they’ll be an active part of the design of the system. DataOps and data engineering will be choosing technologies that design with the expectation of failure. The DataOps team will be making sure that data moves, preferably automatically, to disaster recovery or active active clusters. This is how you avoid six-hour downtimes.
Busting out real-time technologies and SLA levels comes at the expense of conceptual and operational complexity. When I mentor a team on their real-time big data journey, I make sure management understands that the architects and developers aren’t the only ones who need new skills. The operations teams will need new skills and to learn the operations of new technologies.
There isn’t an “I” in DataOps, either
In my experience, the leap in complexity from small data to real-time big data is 15x. Once again, this underscores the need for DataOps. It will be difficult for a single person to keep up with all of the changes in both small data and big data technologies. The DataOps team will need to specialize in big data technologies and keep up with the latest issues associated with them.
As I mentored more teams on their transition to real-time systems, I saw common problems across organizations. It was because the transition to real-time data pipelines brought cross-functional changes.
With a REST API, for example, the operations team can keep their finger on the button. They have fine-grained control over who accesses the REST endpoint, how, and why. This becomes more difficult with a real-time data pipeline. The DataOps team will need to be monitoring the real-time data pipeline usage. First and foremost, they’ll need to make sure all data is encrypted and that access requires a login.
A final important facet of DataOps is dealing with data format changes. With real-time systems, there will be changes to the data format. This will be a time when the data engineering and DataOps teams need to work together. The data engineering team will deal with the development and schema sides of the problem. The DataOps team will need to deal with production issues arising from these changes and triage processing that fails due to a format change.
If you still aren’t convinced, let me give it one last shot
Getting DataOps right is crucial to your late-stage big data projects. This is the team that keeps your frameworks running and your data quality high. DataOps adds to the virtuous upward cycle of good data. As you begin a real-time or batch journey, make sure your operations team is ready for the challenges that lay ahead.
This post is part of a collaboration between O’Reilly and Mesosphere. See our statement of editorial independence.