
 Time (source: Pixabay)
Time (source: Pixabay) “Hot data” is the most recent snapshot of the real world. It’s the real-time data continuously streaming in from IoT device sensors, user clickstreams, and mobile game-play activity. Hot data becomes big data when it comes to rest in a data warehouse, and that data warehouse is traditionally where data science happens.
Machine learning models are typically trained on batches of big data at rest, but many operational use cases require hot data. If you are serving video ads to mobile gamers, supporting sales people walking into a meeting, or operating an oil drill, using the latest data is crucial for success. Machine learning models must be combined with real-time data to make many real-world decisions, and real-time data needs a real-time data infrastructure.
The mobile gaming advertising company Tapjoy has had to confront the challenges of using hot data (full disclosure: Tapjoy is a customer of MemSQL). While users interact with mobile apps or play games, Tapjoy identifies which users are most likely to install a particular app and serves up a video ad for that app.
Robin Li, the director of data engineering, explains: “Due to the nature of our business, it’s absolutely essential that we service all the decisions in real time as requests come in. Our predictions are not just a bunch of numbers sitting on some sales pitch stack.”
Advertisers pay per video view, so Tapjoy finds the users who are the best match for a target app, based on their interests and activity, and serves them a video ad. One percent or less of users, on average, go straight from video to install. However, ideally advertisers want to target users who will not just install the app, but also take actions, such as registering or making an in-app purchase. The task of Tapjoy’s data science team is to identify those users and serve them the right video ad in real time.
“To be able to handle this challenging problem in an efficient manner, we are innovating how we are operating the data science team to go from a more offline research team to a data science service architecture,” says Yohan Chin, VP of data science at Tapjoy.
Every day, 20 terabytes of compressed data is added to the company’s data store. Tapjoy builds a predictive model of each user’s interests, which they refer to as persona predictions or user DNA, based on persona, demographic, and income data. Persona prediction models are trained offline but are served online in real time.
However, for many other features such as user activity or financial data on Tapjoy’s ad spend, the company requires the most up-to-date data. “Checking the real-time signal from our system is very important for making a decision on the combination of pricing and pacing and user interest,” says Li.
Tapjoy’s real-time decision service, which combines persona predictions with real-time data, processes 300,000 requests per minute and the average response time is less than 10 milliseconds. To achieve those numbers, Tapjoy needed a real-time data store that could handle high throughput, calculate real-time analytics on the incoming data (for example spending history), and serve that data fast. The company uses MemSQL for this purpose.
There are many other use cases that require real-time data infrastructure. Dell EMC, for example, sells support and maintenance subscriptions for hundreds of different products (full disclosure: Dell EMC is a customer of MemSQL). The company already used machine learning models to predict events (such as when a particular drive model would fail), but to determine which customers are most likely to renew—for example, customers with a recent service ticket—salespeople also need real-time data.
“It’s one thing to take various logs and do a bunch of modelling on the logs and figure out some predictive analytics that you can run once in awhile,“ says Darryl Smith, chief data platform architect at Dell EMC.“It’s another thing to take real-time data and do actionable intelligence on it. The data was hours, days, months old, so sales people’s ability to get those renewals was greatly hampered.”
Dell built a 360-degree customer dashboard for sales staff that gives each customer a real-time score showing how likely they are to want to renew for a particular product. “What’s the customer I am most likely to win with today?” says Smith. “It gives the salesperson up-to-the-second information as they are walking into the customer site.”
Industrial IoT is another sector where real-time data is already crucial. Oil drilling operations, for example, constantly make real-time decisions on how to best utilize drills in order to minimize the time taken to drill a horizontal well. Each drill bit costs around $1 million and a drill costs up to $3 million per day to operate. A delicate balance must be maintained between maximizing the usage of the drill in order to get the full value from it and not pushing so hard that a drill bit breaks early.
Drill sensors generate half a million data points per second. To efficiently manage the drilling operation, multiple data types and third-party data sources, including geospatial and weather data, must be combined with sensor data.
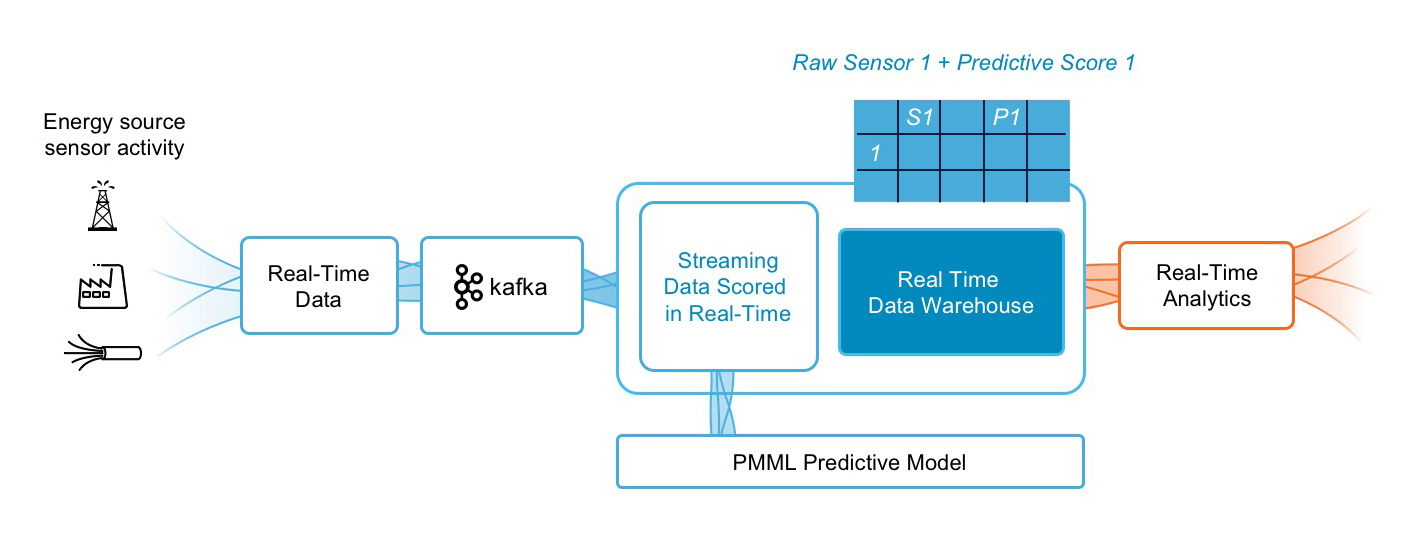
For all the above use cases, you need a real-time data infrastructure that can provide persistence for both real-time and historical data, as well as the ability to query streaming data (Figure 1). This infrastructure can be used to power real-time dashboards, predictive analytics and machine learning applications.
To learn how to build a real-time data warehouse for the age of AI, download the free report, “Data Warehousing in the Age of Artificial Intelligence.”