How to take machine learning from exploration to implementation
Recognizing the interest in ML, the Strata Data Conference program is designed to help companies adopt ML across large sections of their existing operations.
 Data science (source: Pixabay)
Data science (source: Pixabay)
Interest in machine learning (ML) has been growing steadily, and many companies and organizations are aware of the potential impact these tools and technologies can have on their underlying operations and processes. The reality is that we are still in the early phases of adoption, and a majority of companies have yet to deploy ML across their operations. The results of a recent survey we conducted (with 11,000+ respondents, a full report is forthcoming) bears this out—only about 15% of respondents worked for companies that have extensive experience using ML in production:
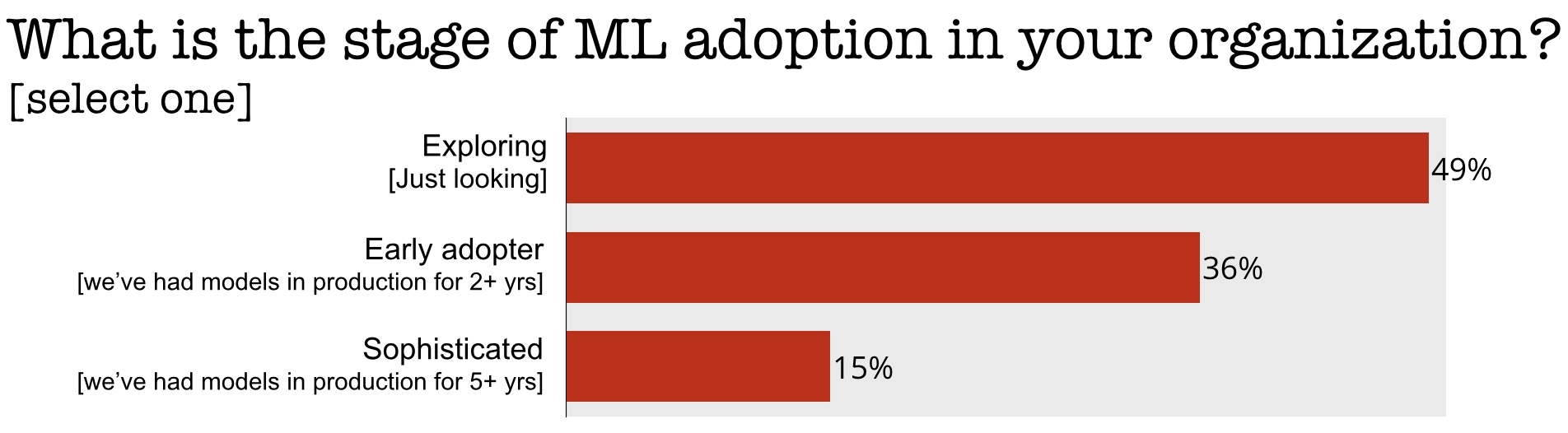
In this post, I’ll describe how one can go from “exploration and evaluation” to actual “implementation” of ML technologies. Along the way, I’ll highlight key sections of the upcoming Strata Data conference in New York this September. Recognizing the interest in ML, we assembled a program to help companies adopt ML across large sections of their existing operations.

Learn faster. Dig deeper. See farther.
Understanding key technologies and methods
Machine learning has enormous potential, but in order to unleash its promise, one needs to identify appropriate problems and use cases. The key to using any new set of tools and technologies is to understand what they can and cannot do. How do you put your organization in a position to take advantage of ML technologies? Because ML has the potential to affect every aspect of an organization, we are highlighting several companies that have invested resources in training and organizing their workforce on these new technologies.
- “Machine Learning in the enterprise”
- Managing data science in the enterprise
- Executive Briefing: from Business to AI—missing pieces in becoming “AI ready“
- Executive Briefing: Agile for Data Science teams
- Executive Briefing: Profit from AI and Machine Learning—The best practices for people & process
Data preparation, governance, and privacy
Much of ML in use within companies falls under supervised learning, which means proper training data (or labeled examples) are essential. The rise of deep learning has made this even more pronounced, as many modern neural network architectures rely on very large amounts of training data. Issues pertaining to data security, privacy, and governance persist and are not necessarily unique to ML applications. But the hunger for large amounts of training data, the advent of new regulations like GDPR, and the importance of managing risk means a stronger emphasis on reproducibility and data lineage are very much needed.
As companies gain more experience, they start augmenting existing data sets with data that holds the potential to improve their existing ML models. There is growing interest in exploring alternative data sets and types. How exactly can companies augment their existing data sets with external data sources? Can decentralization technologies (like blockchains) pave the way for new forms of data exchanges?
- “Data preparation, governance and privacy”
- “Blockchain and decentralization”
- Scalable Machine Learning for Data Cleaning
- Tracking Data Lineage at Stitch Fix
Data integration and data platforms
Data used for ML models tends to come from a variety of sources. Because ML relies on large amounts of (labeled) data, learning how to design, build, and maintain robust data pipelines is important for productionizing machine learning. Depending on the application, companies typically have to grapple with variety (disparate data sources), volume (particularly for deep learning systems that are data hungry), and velocity (ingesting data from sensors and edge devices).
Over the last few years, many companies have begun rolling out data platforms for business intelligence and business analytics. More recently, companies have started to expand toward platforms that can support growing teams of data scientists. Common features of modern data science platforms include: support for notebooks and open source machine learning libraries, project management (collaboration and reproducibility), feature stores (for storing and sharing useful variables), and model visualization.
Model building: Some standard use cases
Machine learning has become commonly used for recommendation and personalization applications. The rise of new algorithms always tends to bring renewed interest. Deep learning has caused many companies to evaluate their existing recommenders, and many have begun to use neural networks to either supplement or replace their existing models. Deep learning has also reinvigorated interest in applications involving two data types found within many companies: text (natural language processing and understanding) and temporal data (correlations, anomalies, forecasting).
- “Recommendation Systems”
- “Text and Language processing and analysis”
- “Temporal data and time-series analytics”
- Machine Learning with PyTorch
- “Deep Learning”
Model lifecycle management
Companies are realizing that machine learning model development is not quite the same as software development. Completion of the ML model building process doesn’t automatically translate to a working system. The data community is still in the process of building tools to help manage the entire lifecycle, which also includes model deployment, monitoring, and operations. While tools and best practices are just beginning to emerge and be shared, model lifecycle management is one of the most active areas in the data space.
- “Model lifecycle management”
- Model serving and management at scale using open-source tools
- From Training to Serving: Deploying Tensorflow Models with Kubernetes
- Deploying ML Models in the Enterprise
- Infrastructure for deploying machine learning to production: lessons and best practices in large financial institutions
Ethics and privacy
Newly introduced regulations in Europe (GDPR) and California (Consumer Privacy Act) have placed concepts like “user control” and “privacy-by-design” at the forefront for companies wanting to deploy ML. The good news is that there are new privacy-preserving tools and techniques—including differential privacy—that are becoming available for both business intelligence and ML applications.
Ethics and compliance are areas of interest to many in the data community. Beyond privacy, data professionals are much more engaged in topics such as fairness, transparency, and explainability in machine learning. Are data sets that are being used for model training representative of the broader population? For certain application domains and settings, transparency and interpretability are essential and regulators may require more transparent models, even at the expense of power and accuracy. More generally, how do companies mitigate risk when using ML?
- “Ethics and Privacy”
- How to be fair: a tutorial for beginners
- Practical Techniques for Interpreting Machine Learning Models
- Beyond Explainability: Regulating Machine Learning In Practice
- Rationalizing Risk in AI/ML
Case studies
Putting all these topics together into working ML products—data movement and storage, model building, ML lifecycle management, ethics and privacy—requires experience. One of the best ways to learn is to hear presentations from peers who have successfully (and repeatedly) used machine learning to reinvigorate key facets of their operations. We showcase many case studies at the upcoming Strata Data conference in NYC; here are a selection of talks from a few application domains: