Implementing a reactive microservices system
An architectural overview of an image processing example.
 Colors (source: Pexels via Pixabay)
Colors (source: Pexels via Pixabay)
A monolith is difficult to change, because any change is always a big deal; however, the change is atomic in the sense that it affects only one system. A distributed monolith is extremely difficult to change, because any change affects multiple components at the same time. And since the components are distributed in different processes, it is difficult to exactly predict the effects of any change. A distributed monolith freezes the pace of change—it brings the complexity of microservices without any of the benefits. Let’s take a look at implementing a reactive microservices-based system and highlight the architectural and technical choices made.
Building an example microservice-based system
An image processing system is a system that ingests images from IoT and mobile devices, and performs image recognition tasks; it then delivers the results of the processing to client backend systems. Example applications include security monitoring, access control, and biometric processing. Under the hood, the system is a collection of loosely-coupled services tied together with a message broker. It uses event sourcing and command query responsibility separation to prevent message or state loss in failures. To achieve reliable operation, this system uses backpressure to manage its processing capacity. Its services are built with potential failures in mind, allowing them to degrade gracefully if needed.

Learn faster. Dig deeper. See farther.
Once an image is accepted, it produces structured messages that describe the content of the image. As soon as the image is ingested, the system uses several independent reactive microservices, each performing a specific computer vision task and producing a response specific to its purpose. The messages are then delivered to the clients of the system. The microservices are containerized using Docker, implemented using the Scala programming language, and any computer vision microservices are implemented in C++ and CUDA.
Architectural analysis
The brief overview of this system sounds like a great match for microservices: there will be an ingestion service, multiple computer vision microservices, aggregation services, and the output microservices. Each service solves multiple problems: the ingestion service needs to accept and validate a very large number of incoming image requests; the vision services perform compute-heavy vision tasks; the aggregation service needs to maintain state and implement the necessary grouping logic, but it no longer has to deal with ingesting images, nor does it have to perform complex computation; and the output services’ main task are to deliver the output to the clients as reliably as possible, but to avoid overloading the clients’ endpoints.
If we get the architecture and implementation right for this system, we will make the most of the promises found with microservices. A proper implementation includes selecting the most appropriate languages and frameworks depending on the workload each service performs, scaling the individual services, evolving the individual services, and then assembling the services into a cohesive reactive system. But to be able to assemble services into a cohesive reactive system, we must be explicit about the service’s dependencies (on other services), APIs, and think about the impact of the inevitable failures—think in terms of graceful degradation instead of outright failure.
We must make the services as loosely-coupled as possible and to allow each microservice to completely own the state it is responsible for managing, while keeping this area of responsibility sharply defined. Don’t attempt to define a common message structure or have generic key-value-like messages; the incoming and outgoing messages should not share any common hierarchy, though it is possible for the outgoing messages to carry forward the incoming information.
In the image processing system we steer away from request-required response—specifically request-required complete response—messaging patterns. There is no time or cardinality coupling of the incoming and outgoing messages—as a result of receiving a message, a service may produce zero or more output messages at some time in the future. This lets us have services whose computation takes too long to fit into the request-response paradigm and services that emit partial outcomes as a result of processing the incoming message. For authorization and authentication, we use a token-based approach, where the token is all that any service needs for authorization: there is no need to make a (synchronous request-required complete response) call to the authorisation service. This leads us to the following high-level architecture.
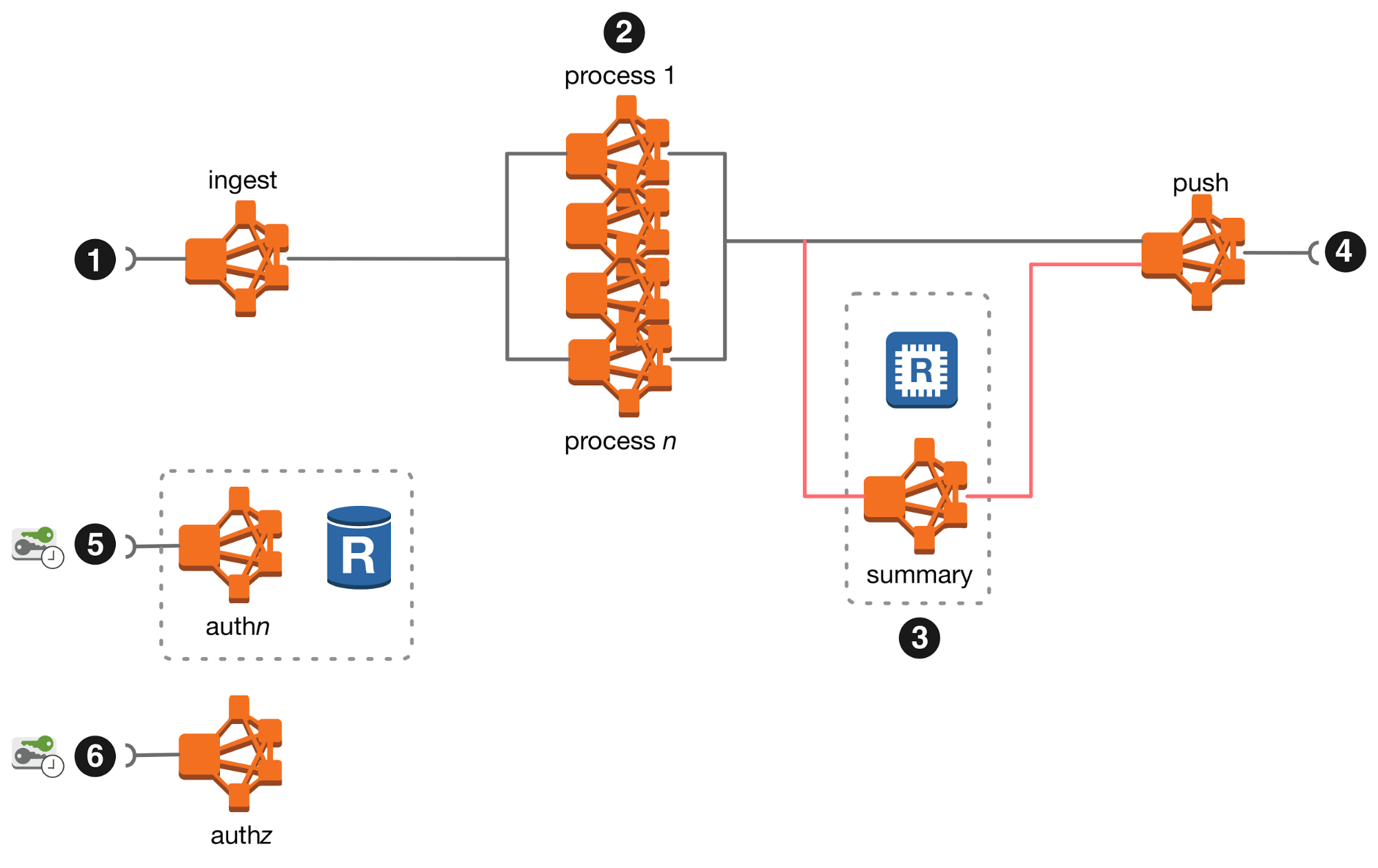
Now that we have a world where services communicate with each other using asynchronous messaging (a service may consume or produce messages at any time), we have to carefully consider how we’re going to route the messages in our system. We want a message delivery mechanism that allows us to publish a message (to a known location), and to subscribe to receive messages from other known locations.
Even though this decoupling in time can be achieved using REST or SSE, this system uses a message broker to provide asynchronous message delivery. The broker we use adds reliability through journalling. This give us at-least-once delivery semantics and allows us to treat the broker as the event story for the microservices, letting us implement event-sourced microservices with very little overhead.
The clearly defined service contexts, clear APIs, loose coupling, backpressure detection, together with the flexibility to select the most appropriate stack for each service allows us to deliver a system that is reliable, but also easy to support and change.
Conclusion
In my forthcoming O’Reilly book, Reactive Systems Architecture, you’ll learn more about the importance of very loose coupling between isolated services, with strict protocols that such decoupling and isolation require. Systems that implement reactive microservices are ready for failures, not simply by being able to retry the failing operations, but also by implementing graceful service degradation. These technical choices give businesses the opportunity to be creative in deciding what constitutes a degraded service. It’s an absolute requirement for the services to be responsive, even if the response is rejection; backpressure is the key indicator that instructs the system as a whole to take on only as much work as its slowest services can process.
This post is part of a collaboration between O’Reilly and Cake Solutions. See our statement of editorial independence.