Integrating continuous testing for improved open source security
Testing to prevent vulnerable open source libraries.
 Keyboard (source: geralt)
Keyboard (source: geralt)
Integrating Testing to Prevent Vulnerable Libraries
Once you’ve found and fixed (or at least acknowledged) the security flaws in the libraries you use, it’s time to look into tackling this problem continuously.
There are two ways for additional vulnerabilities to show up in your dependencies:

Learn faster. Dig deeper. See farther.
-
Code changes added a vulnerable library to the app
-
A new vulnerability in a dependency the app is already using was disclosed
To protect yourself, you need mechanisms to prevent vulnerable packages from being added, and to ensure you get alerted and can quickly respond to new vulnerability disclosures. This chapter will focus on the first concern, discussing how you can integrate SCA vulnerability testing into your process, and prevent the addition of new vulnerable libraries to your code. The next chapter will deal with responding to new issues.
Preventing new security flaws is conceptually simple, and very aligned with your (hopefully) existing quality control. Because vulnerabilities are just security bugs, a good way to prevent them is to test for them as part of your automated test suite.
The key to successful prevention is inserting the vulnerability test into the right steps in the process, and deciding how strict to make it. Being overly restrictive early on may hinder productivity and create antagonism among your developers. On the flip side, testing too late can make fixing issues more costly, and being too lenient can eventually let vulnerabilities make it to production. It’s all about finding the right balance for your team and process.
Here are a few considerations on how to strike the right balance.
When to Run the Test?
Before diving into the details of the test itself, let’s review the most common spots in your workflow to integrate such a test (most of these should look familiar, as they are the same integration opportunities for other quality tests):
- CI/build
-
The most intuitive integration is to “break the build” if a code change introduced a new vulnerability. Because builds are triggered in various scenarios, you can choose to only run the test in a particular build context (e.g., before merging to the master branch).
- CD/release
-
A similar gate in which you can block deployment of a new vulnerable package is an automated release or deployment process. This is a common filter for non-negotiable quality criteria, and can serve as a security gateway too.
- Pull request tests
-
Testing as part of a
git pullorgit mergerequest is similar to CI testing, but is a bit more visible, and can test only the current code changes (as opposed to the entire resulting application). More on that delta later on. - IDE integration
-
Probably the earliest time to test is to do so as you’re writing the code. While it risks being annoying, testing as you type surfaces the problem extremely early, when it’s easiest for the developer to take a more secure path.
- Platform-specific hooks
-
Lastly, some platforms offer specific deployment hooks. You can run a test before a
git push, inside a Heroku or Cloud Foundry buildpack, or as a plug-in to the Serverless framework. Many platforms offer test hooks, which may work well for such a vulnerability test.
This is not a comprehensive list, as in practice you can run tests for vulnerable packages at any point you run an automated test. In addition, not all SCA tools support all of these integration points. Of these, CI and pull-request integrations are the ones most commonly used.
Blocking Versus Informative Testing
Assume you’ve run a test and found some vulnerable libraries. What should you do now? Should you inform the developer the best way you can, and let the process continue, or do you block the sequence altogether? This is a decision you have to make every time you integrate a vulnerability test.
For the most part, early tests are better off being informative as opposed to blocking. Testing in the IDE offers a great opportunity to highlight a problem to the user as they type, but would not be well received if it doesn’t allow the app to build. Similarly, pull request tests are often non-blocking, surfacing a flaw to the user but letting them push through if they think that’s best.
On the flip side, later tests should default to breaking the automated flow. Such gates get closer to (or potentially are the last step before) deploying the vulnerability and exposing it to attackers, which is what we’re trying to prevent. If you do make them informative, note that developers rarely look at the build or deployment output unless they failed to complete. This means you’ll have to make sure they are informed about found issues in a specific way, typically via the capabilities the testing tool offers or a specific customization.
You can further refine this decision through policies. For instance, it’s common to break the build on high-severity issues, but keep low-severity issues as informative only. Alternatively, you may choose to be very strict on your most sensitive production systems, while keeping such tests as a “best effort” for internal utilities that don’t touch customer data.
Failing on Newly Added Versus Newly Disclosed Issues
When building CI tests, it’s important to keep them consistent from build to build. Having a build that fails intermittently is extremely frustrating to developers, and can waste countless hours. The best practice is typically to ensure that a build that succeeded once will, if rerun without changes, succeed again.
Vulnerability testing, however, is different. As I mentioned, vulnerabilities are disclosed in existing components, that previously succeeded when being tested for known security flaws. SCA tests typically use the latest vulnerability DB whenever they change, which means the same test that previously succeeded may now fail, as new vulnerability information came to light.
This can present a problem both in early and late testing. Earlier on, a developer may commit code changes that have nothing to do with any dependency, only to have the build fail because of a newly disclosed vulnerability in a package the app has been using long before. To get the build to complete, the dev would need to upgrade or modify the use of this dependency, a time-consuming task they may not even be able or allowed to do. Later in the pipeline, breaking the build due to new information can prevent re-deployments, which may include such a test, hindering the agility and responsiveness of the organization.
An alternative path is to change the test to examine if a vulnerability was added, as opposed to whether a vulnerability exists. Unfortunately, CI systems (and other gates) tend to test the build as a standalone state, and it’s hard—if not impossible—to find out what changes triggered the process. Practically speaking, CI/CD tests flag all vulnerabilities found, regardless if triggered by code changes or new disclosures.
Pull request (PR) testing, however, is designed precisely for such a scenario. When testing as part of a PR, it’s easier to test both the current branch and the branch you’re about to merge to, and only fail the test if you’re about to introduce a new problem. PR tests also happen at a good time for a security check—just before a single developer’s changes are merged into the team’s stream. Some SCA tools offer PR testing as part of the product, and you can create your own PR tests to invoke some of the others. Figure 1-1 shows an example of failing a test on pull request because it contained code changes that introduced a new security risk.
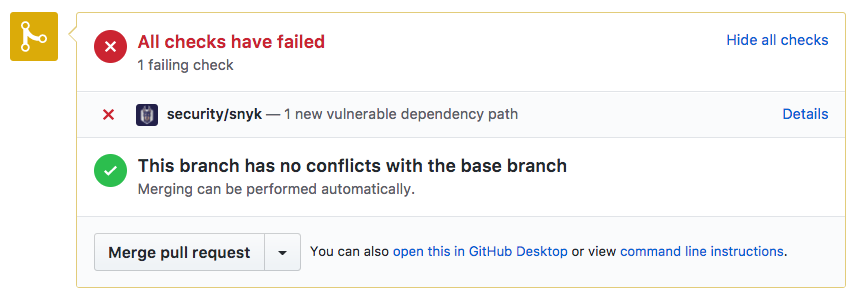
To get the best of both worlds and the risk/disruption balance that’s right for you, consider alternating between changeset testing and complete testing at different gates. For instance, you can introduce informative-only PR tests early in the process, alerting developers to the problem, which would (hopefully) get many of them to fix it early and cheaply. In addition, you can add a strict security gate as part of your deployment process that tests the entire application and disallows vulnerable libraries regardless of where they came from (unless they were explicitly acknowledged, as described in “Ignoring Issues”).
Platform-Wide Versus App-Specific Integration
When integrating SCA testing, you can also choose between a “top down” approach, where you integrate the test into a continuous or runtime platform and run it on all applications, and a “bottom up” approach, where a single app (and later more of them) adds this test to their code.
App-specific integrations are more aligned with other quality tests you perform. For the most part, functional tests are created and run for each application, possibly leveraging some testing infrastructure you set in place. This means you can run the test at the right time for each specific application, handle its results as befits this app’s nature, and empower developers to own this responsibility.
Platform-wide testing is a better way to ensure the testing is done, and enforce compliance on all applications. You can ensure vulnerable libraries are addressed throughout, and set the policies of which risks are acceptable and which ones are not. When testing centrally, you should decide the level of control each application can get. For instance, can an app opt out of this testing? Can a developer ignore an issue? Even platform-wide testing would likely require some form of app-specific controls.
A good rollout approach is to start with app-specific testing and, once you’re ready, expand to protecting your applications platform wide. Doing so does have some technical tool requirements, though. For app-specific integrations, check if your SCA tool can be invoked as a CLI tool, or can integrate with a platform but only be “turned on” for specific applications. For platform-wide integration, confirm the solution can then expand to integrate with all applications, and apply central policies as well. Choosing a tool that fits the evolution you envision can save you significant pain down the road.
Integrating Testing Before Fixing
If you weren’t testing for vulnerable libraries until now, odds are your initial tests would find many flawed dependencies. Fixing those libraries, even if you make it as easy as you can, can take a considerable amount of time. In the meantime, your developers will continue to add new libraries to your application, and new vulnerabilities will be found in the dependencies you already use.
As is the case with many quality concerns, a useful first step when tackling this problem is to try and set a baseline, and introduce integrated testing to make sure you don’t slip past it. Doing so will help ensure you’re not getting worse, while buying you time to eat away at the problems that exist in the system today.
There are two ways to baseline vulnerable library use. The first is to ignore all current issues, and just start testing from now on. This approach is effective in keeping the tools from alerting on old issues, but is clearly poor from a security perspective, as it hides real and immediate security risks you’ve not addressed. Still, it’s a possible way to go, and you can separately run other tests that don’t ignore the issues, and trigger steps to fix the found issues through that path.
The second way is to integrate tests so that they only break on issues introduced by code changes, but disregard past issues. As described before, this approach is most natural in the context of pull request tests, but may be doable in other testing contexts, or supported in the SCA tool you use.
Integrating testing before taking on the broader fix is a powerful way to roll out an SCA tool. It lets you get started right away, will prevent real and immediate problems, and will raise awareness to this risk among your developers. Over time, this approach will also gradually trigger upgrades and fixes to your dependencies, eating away at your security technical debt.
In addition, gradual rollout will set you up to track your dependencies across the board, which in turn will help you respond better to newly disclosed vulnerabilities via notifications, as we’ll see in the next chapter.
Summary
Preventing the addition of new vulnerable libraries is a key part in making such protection continuous. When doing so, the key tradeoff is between blocking a build or deployment and informing developers. Once that’s decided, proceed to choosing where in the workflow and toolchain to place such gates or information.
My recommendation is to start by integrating informative testing of change-sets, for instance in the pull requests, which keeps you from slipping while raising awareness to this concern among your team. In fact, I can’t think of any reason not to flag new vulnerable libraries during the development process.