Learning Apache Mesos
Resources for getting started with Apache Mesos.
In the summer of 2012, Accel Partners hosted an invitation-only Big Data conference at Stanford. Ping Li stood near the exit with a checkbook, ready to invest $1MM in pitches for real-time analytics on clusters. However, real-time means many different things. For MetaScale working on the Sears turnaround, real-time means shrinking a 6 hour window on a mainframe to 6 minutes on Hadoop. For a hedge fund, real-time means compiling Python to run on GPUs where milliseconds matter, or running on FPGA hardware for microsecond response.
With much emphasis on Hadoop circa 2012, one might think that no other clusters existed. Nothing could be further from the truth: Memcached, Ruby on Rails, Cassandra, Anaconda, Redis, Node.js, etc. – all in large-scale production use for mission critical apps, much closer to revenue than the batch jobs. Google emphasizes a related point in their Omega paper: scheduling batch jobs is not difficult, while scheduling services on a cluster is a hard problem, and that translates to lots of money.

Learn faster. Dig deeper. See farther.
Grad students at UC Berkeley EECS had been grappling with this problem long before Ping Li took the stage at Stanford. Ben Hindman, Andy Konwinski, Matei Zaharia, Ali Ghodsi, et al., authored the early Mesos paper, emphasizing mixed workloads and reduced latency. As the project expanded into commercial use cases at Twitter, HA services and low-latency apps became priorities.
However, to correct a misunderstanding… more recent research coming out of Berkeley, e.g., Sparrow: Distributed, Low Latency Scheduling, repeatedly examined Mesos in the context of Hadoop vs. Spark comparisons. They emphasize batch jobs and place Mesos in the category of resource manager. Perhaps that has more to do with “publish or perish” priorities, less to do with production use cases in industry. It’s not where the money is focused.
Even so, a thought exercise deconstructing Hadoop is useful for learning Mesos. Apache Hadoop is a kind of distributed framework. An app written as a graph of MapReduce jobs is, well, an app. Hadoop’s job tracker represents both a scheduler and a long-running process. Hadoop task trackers are executors, consuming scheduled resources to perform units of work. Now there’s more to Hadoop – use of a barrier pattern for synchronization, generally some use of semigroups and monoids within the apps, etc. The point is that over 1 million lines of source code have been contributed to Apache Hadoop since 2006. Meanwhile, a similar class of fault-tolerant frameworks can be built with Mesos in a few hundred lines of Python, a similar amount of Go, or less than 100 lines of Scala – with much more flexibility than Hadoop, and much lower latency.
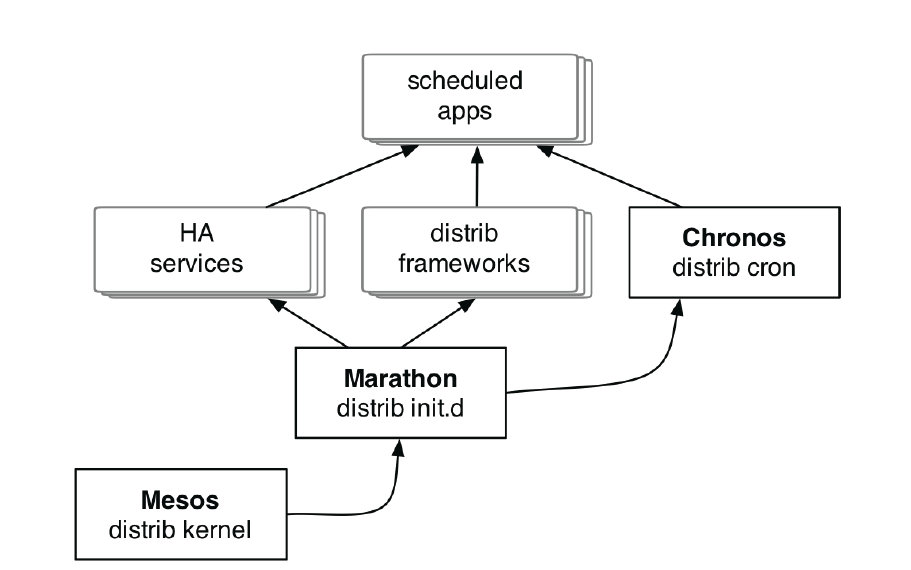
Or, reformulate your workflows into sets of HA services and dependency graphs of tasks, then leverage Mesos building blocks, e.g., Marathon and Chronos.
Where does one go to learn more about building frameworks, apps, services, etc., with Mesos? The first step is to check the Apache Mesos project site, which has docs, downloads, issue tracking, etc. The #mesos IRC channel and the user email list are particularly good places to start. Developers are involved from a number of companies with production deployments: Twitter, Airbnb, HubSpot, MediaCrossing, Sharethrough, Ooyala, Devicescape, iQiyi, OpenTable, CloudPhysics, Xogito, Vimeo, etc. Twitter OSS and in particular the new Twitter University also provide lots of support and resources (no pun intended) for the Mesos community.
At Strata SC coming up, there will be multiple Mesos events: Feb 11 tutorial, Big Data Workflows on Mesos Clusters; Feb 13 session, Apache Mesos as an SDK for Building Distributed Frameworks; as well as office hours and a Mesos BOF. Also keep watch for the AMPCamp workshops led by Andy Konwinski, one of the principal Mesos authors.
Part of the Mesos tutorial at Strata SC will cover 13 steps to build an example framework in Python. The result is a Python distributed framework called Exelixi, used for Genetic Programming at scale.
For excellent online resources, check the Elastic Mesos free-tier service which launches Mesos clusters on Amazon AWS in three steps. Mesosphere also publishes several interactive Mesos tutorials about Spark, Hadoop, Storm, Marathon, Chronos, etc. Join us for an O’Reilly webcast on Jan 24, to explore Spark on Mesos on AWS.
For a deep-dive into systems, there’s a good tutorial about using Linux cgroups from a command line. Playa-Mesos provides a simple way to build Mesos environments, based on Vagrant, VirtualBox, and Ansible. Or build clusters directly with pre-built Mesos packages from Mesosphere. A couple other Mesos integrations have gathered much interest: Docker containers and Play Framework web apps.
Looking ahead, an initial Mesos conference is planned for Spring 2014. Meanwhile, see you at Strata, Velocity, and OSCON!