Quality of Service for Hadoop: It’s about time!
How QoS enables business-critical and low-priority applications to coexist in a single cluster.
 Yin Yang carved in stone. (source: Wingsancora93 on Wikimedia Commons)
Yin Yang carved in stone. (source: Wingsancora93 on Wikimedia Commons)
If you are responsible for running a multitenant Hadoop cluster, there are a number of obstacles you must overcome before the complex machinery of your big data platform can operate efficiently, predictably, and without outages. This article describes the challenge of enforcing Quality of Service (QoS) for Hadoop applications, which is a prerequisite to providing Service Level Agreements (SLA) to users running jobs on your cluster. This article is the second in a series that describes problems related to performance in a multitenant Hadoop environment and solutions you must consider to bring peaceable coexistence to the multiple workloads competing for resources on your cluster and maximize your ROI. The first article and corresponding webcast discussed multitenancy on Hadoop and real-time cluster monitoring.
QoS defined
The term Quality of Service has roots in the telecommunications and networking world, defined by the overall performance of the network as seen by its users. The quantitative measure for QoS in the networking world is based on the available bandwidth for a data flow. In its Hadoop incarnation, QoS refers to access to cluster hardware resources—CPU, disk, or network—for applications based on priority. For instance, without QoS you can imagine a scenario where a low-priority extract, transform, load (ETL) job is writing data into HDFS and keeping a business-critical streaming job from writing to HDFS. In the worst case, this scenario could cause irrecoverable loss of data. How can you ensure that the high-priority application gets access to the resource it needs, when it needs it, so the job can complete on time?

Learn faster. Dig deeper. See farther.
The role of YARN in QoS
YARN provides the ability to preempt certain applications in order to make room for other, perhaps more time-sensitive or higher priority, applications that are queued up to be scheduled. Both capacity scheduler and fair scheduler in YARN can be statically configured to kill applications that are taking up cluster resources needed to schedule higher priority applications. Unfortunately, YARN does not resolve the real-time contention problems that can occur when both tasks are already scheduled. YARN does not monitor actual utilization—for example, HDFS usage—of tasks when they are running, so if a low-priority application has possession of a hardware resource, higher priority applications have to wait. This leads to longer-than-desired application completion times.
The problem of real-time contention of resources
In the first article in this series, we presented options to extract unused capacity from applications that are currently running on the cluster. This extraction enables cluster operators to delay or even avoid the need for pre-emption of running applications. Aside from underutilization, the other big performance issue when running multiple jobs on a single cluster results from the delays caused by real-time contention of hardware resources in the cluster. Let’s explore this problem by considering a simple three-node cluster, as illustrated in Figure 1. In this example, there are two jobs in the queue ready to be scheduled by the YARN Resource Manager (RM). RM has determined that both the business-critical HBase streaming job and the low-priority ETL job can run simultaneously on the cluster, and schedules them for execution:

Figure 2 (below) illustrates a runtime situation on this cluster without QoS, where YARN has previously determined that the cluster has sufficient resources to run a low-priority job and a business-critical job simultaneously. In most situations, there is an expectation that the business-critical job will complete in a certain period of time as defined by an SLA. The low-priority job, on the other hand, has no such expectation and can be delayed in favor of the higher priority job.
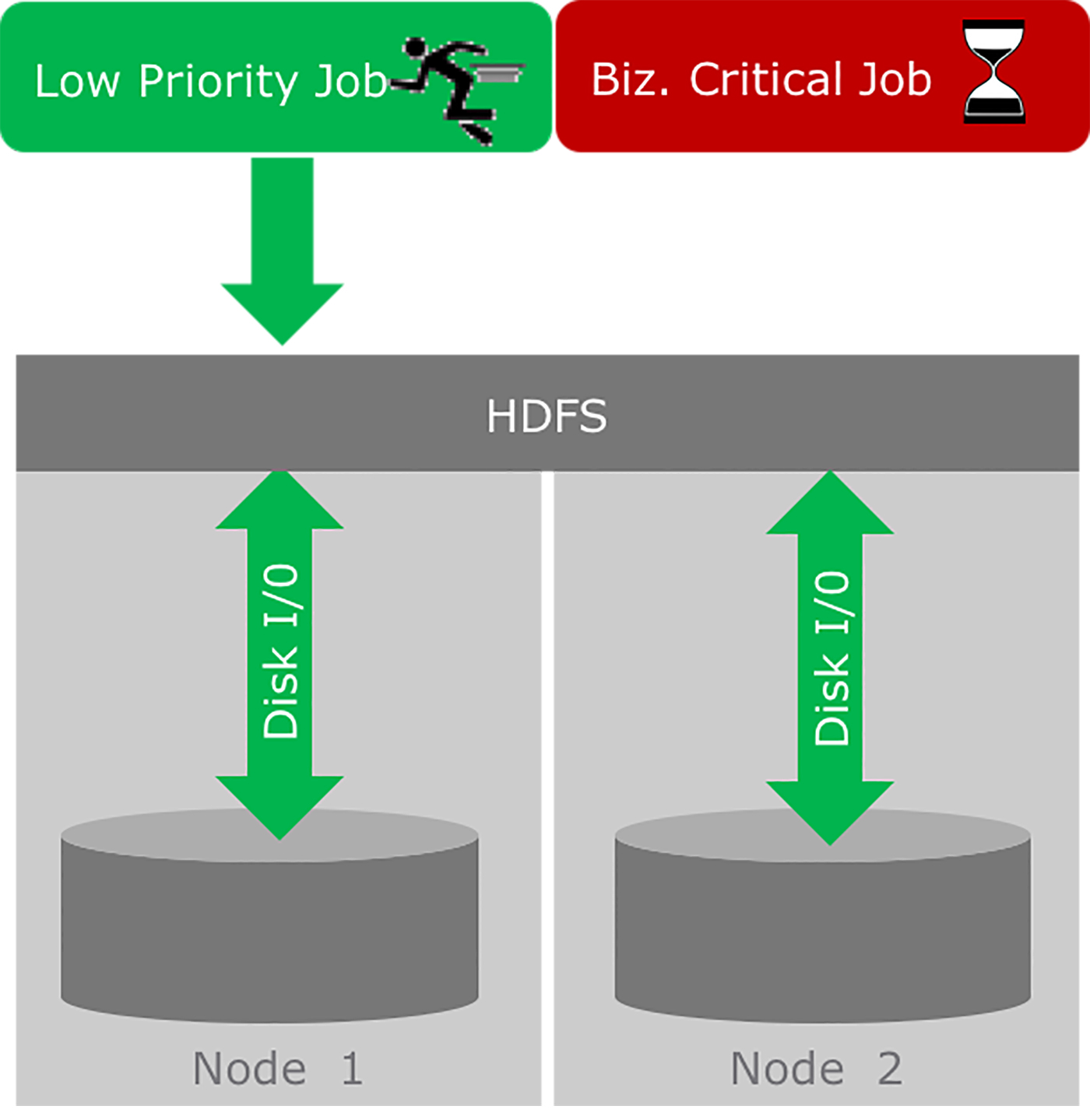
In this scenario, the low-priority job starts accessing HDFS and, soon after, the business-critical job needs access to the same data location in HDFS. The read and write requests from the two jobs are interleaved so that the business-critical job has to wait while the low-priority job has control of the disk I/O. The wait time is insignificant and will very likely not result in a delay to the SLA guarantee of the business-critical job in this example. However, in a multi-cluster Hadoop deployment, many low-priority workloads can “gang up” against the business-critical job while competing for hardware access. This often results in unacceptable delays in execution time.
When best practices for guaranteeing QoS fall short
One solution to this problem is to have separate clusters for business-critical applications and low-priority applications. This is a typical recommended best practice and is a perfectly acceptable solution to the problem of guaranteeing QoS. The downside of this solution, however, is wasted capacity and additional overhead of maintaining multiple clusters. Another way to guarantee QoS is to keep a single cluster, but manually restrict low-priority jobs to certain time periods during which the cluster operator does not schedule business-critical high priority jobs.
A more targeted solution to this problem, and where there is an opportunity for the next generation of tools, is to monitor the hardware resources of each node in the cluster in real time in order to understand how QoS is being impacted by cluster resources. In the instance described above, real-time monitoring would enable understanding of which job has control over disk I/O. Knowledge of this access, in tandem with a global view of network availability and resource utilization, can then be used to force the low-priority jobs to relinquish control over hardware resources that are needed by high-priority jobs. This action ensures that all jobs get access to cluster hardware resources in an equitable manner, and business-critical jobs can finish on time.
Upsight: A use case for QoS in Hadoop
Let’s look at a real-life use case from one of Pepperdata’s clients. Upsight uses Hadoop to process more than 500 billion data points every month in order to provide marketing analytics to mobile and web developers. Upsight has a single multitenant cluster running streaming applications that write data to HBase, as well as various ETL jobs that are run at different times of the day as needed. Figure 3 illustrates the real-time contention experienced by the mission-critical HBase workload in Upsight’s Hadoop cluster during writes into HDFS. The HBase workload is depicted by the purple shaded area, and lower priority jobs that also run on the cluster are depicted by the green and red shaded areas. For the time period between 6 p.m. on May 29 and 4 a.m. on May 30, the HBase workload is fighting for access to HDFS, and frequently losing the battle to the lower priority jobs.
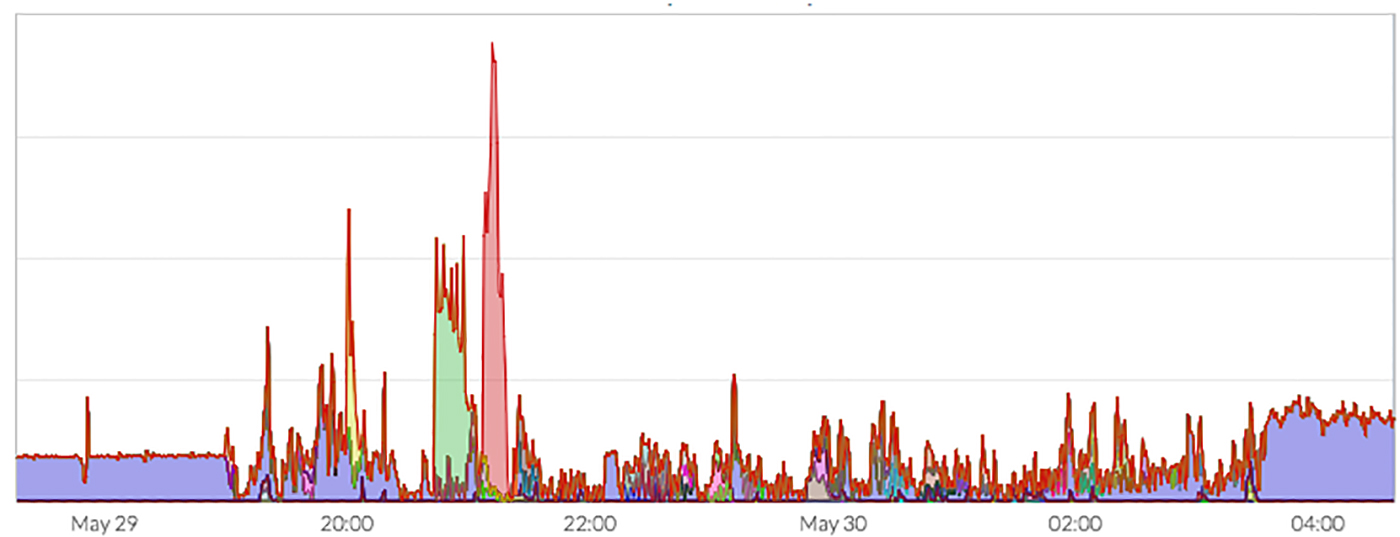
Upsight tried multiple solutions, including running HBase on a separate cluster, physically separating MapReduce and HBase workloads, and even running HBase on YARN. These solutions proved to be unworkable in some cases and too complex to manage for the rest. Eventually, they turned to Pepperdata for an automated real-time QoS solution that allowed the HBase workload to get priority access to HDFS.
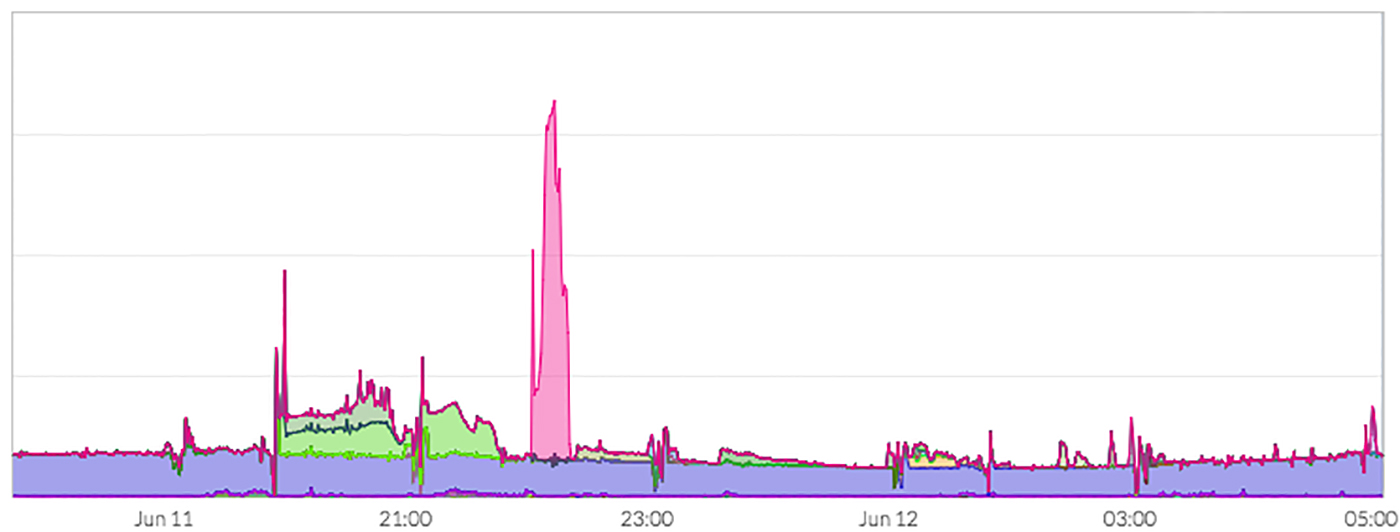
Figure 4 illustrates how QoS allows both low- and high-priority workloads to coexist in a single Hadoop cluster. In this case, the HBase workload is getting steady access to HDFS when needed, and the low-priority jobs are also getting access to hardware resources, albeit a bit delayed.
Conclusion
There are multiple ways of achieving SLA guarantees for business-critical workloads in a Hadoop cluster. Static approaches enable you to provide the QoS needed, but come with the penalties of cost and inefficiencies. In order to provide QoS in a multitenant Hadoop cluster that is running workloads of varying priority, you need a solution that automatically adapts to cluster conditions in real time.
This post is a collaboration between O’Reilly and Pepperdata. See our statement of editorial independence.