 Sisyphus (source: Beth Scupham on Flickr)
Sisyphus (source: Beth Scupham on Flickr) SRE best practices at Google advocate for building alerts based upon meaningful service-level objectives (SLOs) and service-level indicators (SLIs). In addition to an SRE book chapter, other site reliability engineers at Google have written on the topic of alerting philosophy. However, the nuances of how to structure well-reasoned alerting are varied and contentious. For example, traditional “wisdom” argues that cause-based alerts are bad, while symptom-based or SLO-based alerts are good.
Navigating the dichotomy of symptom-based and cause-based alerting adds undue toil to the process of writing alerts: rather than focusing on writing a meaningful alert that addresses a need for running the system, the dichotomy brings anxiety around deciding whether an alert condition falls on the “correct” side of this dichotomy.
Instead, consider approaching alerting as a hierarchy of the alerts available to you: reactive, symptom-based alerts—typically based on your SLOs—form the foundation of this hierarchy. As systems mature and achieve higher availability targets, other types of alerts can add to your system’s overall reliability without adding excessive toil. Using this approach, you can identify value in different types of alerts, while aiming for a comprehensive alerting setup.
As detailed below, by analyzing their existing alerts and organizing them according to a hierarchy, then iterating as appropriate, service owners can improve the reliability of their systems and reduce the toil and overhead associated with traditional cause-based and investigative alerts.
Basic alerting concepts
This proposed alerting maturity hierarchy builds upon a few basic definitions of and assumptions about alerting.
What is an alert?
For the purposes of this discussion, we consider an alert to be a page, ticket, Slack notification, or automated email that’s generated from the system. For example, a user escalation would not be considered an alert.
Why do we alert?
An alert calls for human action. The system can no longer handle a situation on its own, and requires the creative mind of a human. This criteria also covers situations in which the system could handle the situation on its own, but still needs to involve a human—for example, because unsupervised automatic resolution is too dangerous.
This also means that an alert might be benign. The system alerted a human because the system couldn’t determine what to do next. But a human might determine that everything is in order and no action should be taken. If we could automatically make that determination, we wouldn’t need the alert.
What is a good alert?
The valuation of whether or not an alert is “good” is inherently subjective—an alert is good if the human recipient finds it good, and every other evaluation criterion is a proxy. That being said, there are some fairly common proxies:
- Timeliness: Did the alert arrive on time, rather than too long after the event to be useful?
- Correct delivery: Was the alert sent to the correct human, or was it delivered to an adjacent, but incorrect team?
- Documentation: Was the alert content relevant to the issue a human needs to evaluate, or did it contain a generic and unhelpful description?
- Actionability: Did the alert prompt any action (other than simply acknowledging the alert)?
Proposed hierarchy
Now that we know why we alert and have a working definition of a good alert, we propose a pyramid-shaped hierarchy of alerting maturity. This pyramid is evocative of Maslow’s hierarchy of needs and the service reliability hierarchy posed in the SRE book. In the proposed hierarchy shown in Figure 1, we reason about alerts in three categories: reactive alerts, proactive alerts, and investigative alerts. You should only implement proactive alerts once you have a solid foundation of reactive alerts, and you can’t think about investigative alerts until both your reactive and proactive alerts are in a good state.
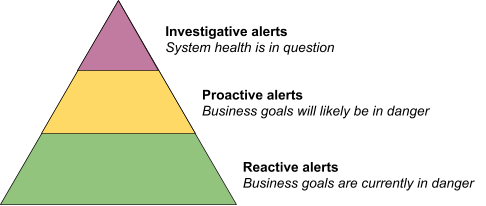
While thinking about alerts in terms of cause-based versus symptom-based is somewhat orthogonal to this hierarchy, it may be useful to think of symptom-based alerts as falling under the reactive alerts category and cause-based alerts as falling under the proactive and investigative alerts categories.
Types of alerts
You can use the descriptions of alert types and example scenarios below to reason about corresponding sets of alerts for your service.
Reactive alerts
Your business goals are currently in immediate danger. SLO-based alerting is a great example of reactive alerting.
Example scenario: Alert when you’re in danger of breaching an SLO. A good reactive alert fires when (to the best of our knowledge) there is an imminent danger of an SLO breach. This allows the human recipient to react to the danger before all is lost.
If you haven’t set up reactive alerts for your service, it’s likely that most of your uptime-affecting incidents result from issues not captured in SLO alerts. After establishing a baseline of reactive alerts, your service should alert a human before the service exceeds its error budget. If an alert only fires when you have already violated your SLO, it’s too late to take action.
Note that “to be in danger of” does not mean the anticipated event will definitely happen. For example, the SLO burndown can recover on its own. It only means that with information available at the point of the alert, there’s a reasonable expectation the SLO will be violated if nobody takes action.
Of course, crafting a comprehensive set of reactive alerts is not straightforward. Not every situation that could endanger your SLO is worth alerting on.
Proactive alerts
Your business goals are probably going to be in danger soon but aren’t in immediate danger—you’re on trend to hit problems. You aren’t burning error budget in a way that strongly indicates you’re in danger of breaching your SLO. Quota alerts are a good example of proactive alerts.
Example scenario: If you use a storage system that rejects write requests when you hit 100%, configure your alerting to warn you a week before you hit 100%, at which point you should proactively respond to the situation. For example, you could set up a garbage collection job to clear out extra quota usage. That way, your storage system never fills up completely and starts rejecting writes.
In this scenario and similar ones, a reactive alert might complement your proactive alert. For example, if you’re in danger of hitting the 100% quota mark, the system would also trigger a reactive alert that your system is in danger of breaching its SLO.
Investigative alerts
Your system is in some sort of unusual state, which may contribute to a partial failure now and/or a threat to a business goal later. For example, a server binary is restarting occasionally without a known cause, but no traffic is being affected because of redundancy or retries. Investigative alerts are particularly useful when the problem could be a sudden shift in user behavior. More often, investigative alerts indicate a service failure that is out of scope for any SLOs.
Examples:
- Fluctuations in the number of users loading photos on a photo sharing app
- Sudden changes in usage patterns, such as a dramatic increase in 404 responses at the expense of all other response codes
Example scenario: Before developing investigative alerts, the system fails and sends an alert stating “the compute jobs are crash-looping.” After writing investigative alerts, the system more clearly states “the rate of 500 HTTP errors in the front end is growing dramatically and the jobs are crash-looping,” providing more footing to investigate the symptoms of the incident.
Recall that alerts necessarily involve human judgement and uncertainty. The alert fires because the system does not know what step to take next.
How reactive, proactive, and investigative alerts work together
Think of these three alert types as a hierarchy. You should only move to higher levels of the pyramid if the foundations below are solid and not causing undue toil.
These alerts don’t need to be received by the same group of people. For example, in SRE-managed products, due to the reactive nature of oncall, it’s clear that SREs should care about reactive alerts when they directly correspond to business needs. However, you might route proactive and investigative alerts across SRE and product development teams more liberally.
Not all alerts merit the same level of urgency or consistency. For example, to ensure a timely response, you may only want to fire investigative alerts during business hours.
Bad setups and their remedies
Each type of alert serves a purpose, but as with any powerful tool, there is a risk of misusing them. Below are some common anti-patterns and their remedies using a maturity hierarchy-based approach.
Only investigative alerts
In this scenario, investigative alerts account for most or all of the primary service alerting. This anti-pattern has led to much of the polarized language characterizing cause-based alerting as bad. As shown in Figure 2, these alerts aren’t supported by a foundation of reactive and proactive alerts.
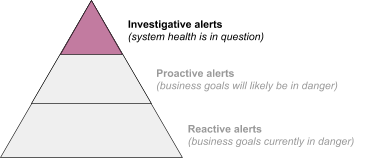
Symptoms:
- Your service does not have SLOs/SLIs, or you do not have alerting on SLOs/SLIs.
- Even if your service has SLOs/SLIs, the majority of incidents are discovered by alerts that are not SLO-based.
- The majority of the alerts considered “investigative” are given a paging priority, rather than a priority indicating the investigation can wait until the next business hour.
Remedy:
Establish SLOs and SLIs that reflect your business goals. Alert on these SLOs/SLIs. These reactive alerts will form the base of your pyramid.
Total set of alerts incurs too much toil
In this situation, there may be a reasonable mix of alerts, but their combined volume causes operators to regularly disregard or fail to prioritize them.
Symptoms:
- You receive too many paging alerts: your setup either has too many alerts, or a small pool of alerts that fire too often.
- You receive too many non-paging alerts (for example, tickets), and frequently disregard them, declare “ticket bankruptcy” (close out a large chunk of tickets in order to start over from a clean slate), or otherwise allow them to fall into disrepair.
Remedy:
As shown in Figure 3, climb down the pyramid of alerting maturity by disabling alerts at higher levels of the hierarchy. Move toward the base as far as necessary to reach a manageable state. By mapping your alerts to the hierarchy, you will implicitly drop the less important alerts first.
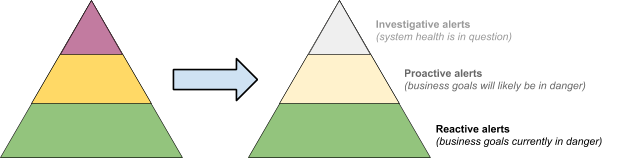
Figure 3: Climb down the pyramid of alerting maturity
Inactionable alerts have a cost: if too many conditions trigger alerts, it becomes increasingly difficult to prioritize the most important alerts in a sea of noise. This results in worse uptime and more toil and burnout, harming both short- and long-term system reliability. You’ll want to climb up the pyramid again as you gain more control over the system, but only after you have reached and sustained a reasonable level of alerting—for example, for a month or longer.
SLO/SLI alerting is insufficient to discover common outages
Although you’ve set up SLO-based alerting, you’re often notified of outages that threaten business goals by some other alerting—proactive alerts, investigative alerts, or even just user escalations.
Symptom:
More than one or two of your past 10 postmortems resulted from issues not captured in SLO alerts.
Remedy:
Resist the urge to craft more investigative and/or proactive alerts—your problem lies in the bottom layer of your alerting hierarchy, not the upper layers.
Instead, figure out why you experienced an outage that’s not covered by your SLIs. Either:
- You need to augment your SLIs to better cover the business aspects of your service, or
- Your definition of an outage is overly sensitive and needs to be reexamined
Cause-based alerts aren’t wrong!
…they’re just misunderstood. As described in the first anti-pattern above, cause-based alerts are problematic if they’re the only type of alerting you use. When used in conjunction with other types of alerts, cause-based notifications can provide a deeper understanding of the system and improve its robustness. But your aggregated alerting must not lead to toil, and when it does, we recommend revisiting your alerting strategy.
All too frequently, we treat alerting as a haunted graveyard: we shy away from removing an alert (because what if it catches something important?!) just as much we shy away from enabling a new alert (because what if it causes toil?!).
Throughout SRE history, alerting setups have been built based mostly on opinion and conjecture, rather than by actually analyzing which setups best serve the end goal of running reliable services with minimal toil. An alerting hierarchy allows us to approach alerting as a path we can walk, describing what is good or bad in a given situation instead of in absolutes. With this framework, we can iterate and improve our alerting based on data, rather than sound bites.
This post is part of a collaboration between O’Reilly and Google. See our statement
of editorial independence.