
 Singapore (source: xegxef)
Singapore (source: xegxef) Responding to New Vulnerability Disclosures
The techniques to find, fix, and prevent vulnerable dependencies are very similar to other quality controls. They revolve around issues in our application, and maintaining quality as the application changes. The last piece in the vulnerable library puzzle is a bit different.
In addition to their known vulnerabilities, the libraries you use also contain unknown vulnerabilities. Every now and then, somebody (typically a library’s authors, its users, or security researchers) will discover and report such a vulnerability. Once a vulnerability is discovered and publicly disclosed, you need to be ready to test your applications for it and fix the findings quickly—before attackers exploit it.
The Significance of Vulnerability Disclosure
A new vulnerability disclosure is not a new vulnerability. The security flaw existed in your library’s code all along, introducing a weakness in your application. However, when a vulnerability is made public, its likelihood of being exploited skyrockets.
Consider the effort required for an attacker to find a vulnerability in a library. There are literally millions of open source libraries out there, with tens of thousands of them in heavy use. A large portion of these libraries are in active development, with regular code changes introducing new functionality and fixing old bugs. Many of these packages are also quite complex, reaching many thousands of lines of code. Understanding the code in all of these libraries and finding a security flaw is a massive undertaking.
When a vulnerability is disclosed, an attacker is spared all this effort. Instead, they can jump straight to the next steps: assessing whether the vulnerability is interesting enough to exploit, building such an exploit if so, and seeking out potential victims through fingerprinting or automated tests.
It’s no wonder that once a severe vulnerability is disclosed, it quickly shows up in automated attack tools around the world, running up the exploit counts as attackers rush to capitalize on the new low-hanging fruit. Long story short, a known vulnerability requires far more urgent action than a hidden one.
Setting Up for Quick Remediation
The good news is that a vulnerability disclosure also makes it easier for defenders to act. Once a vulnerability is made known, you can find the applications using the library in question and fix or otherwise mitigate the risk.
Because vulnerabilities are discovered often, it’s critical to make this process quick and efficient, allowing you to remediate the issues faster than attackers can exploit them. Setting up for fast response includes a few steps:
Monitor which dependencies each application is using.
Get a feed of vulnerability notifications.
Automate matching and notification of a new disclosure to your dependencies.
Automate the remediation steps.
Let’s dig into each of these steps in a bit more detail.
Monitoring Which Dependencies Your Apps Are Using
To be able to ascertain if a future vulnerability affects you, it’s critical to know which applications you have, and which libraries each application uses. The enumeration of the artifacts (including libraries) each app is using is often referred to as the application’s Bill of Materials (BOM), a term borrowed from the world of physical manufacturing, describing the materials used to create the final product.
Keeping the BOM up to date is critical, as an outdated one can easily cause more harm than good. There are three primary ways to keep it continuously updated:
Monitoring your source code management (SCM) platforms
Integrating into your continuous deployment (CD)
Monitoring deployed applications
Let’s delve into the details of each.
Source Code Management Platform Integration
The first way to track your dependencies is by attaching directly to your source code management (SCM) platform, such as GitHub, BitBucket, or GitLab. When using an SCM, there is almost always a “master” branch that represents the code currently deployed to production, including the dependency-related manifest files.
Monitoring dependencies in SCM is elegant and powerful. It enables great prevention and remediation capabilities, as discussed in previous chapters, and allows for automated remediation pull requests, as I’ll explain shortly. I highly recommend monitoring the dependencies used via SCM integration. That said, monitoring source code can sometimes be inaccurate, due to several scenarios.
First, as I’ve explained in Chapter 2, source code scanning requires the testing tool to approximate what would be the eventual dependency tree. This approximation can be very accurate (depending on the tool you use), but it’s not as perfect as testing a built app, especially in platforms that do not use a lock file or applications using a more complex build flow.
Second, source code is always a few steps ahead of deployed code. By definition, you modify your source code, test and evolve it, and then deploy. In the fastest scenario, merges to the master branch are immediately rolled out, meaning the master source code branch is just minutes (or even seconds) ahead of the deployed code. Most setups, however, are not quite that fast, allowing source code to evolve for hours, days, or weeks before deploying it. Therefore, if you’re monitoring your dependencies in SCM, you may be monitoring tomorrow’s dependencies and be blind to vulnerability disclosures that affect the libraries used in production today.
Lastly, monitoring source code doesn’t capture potential complexity in how you deployed code in the past. Are you using a canary version of your code to test out new changes? Do you have an older version of the application deployed to support a large historic customer? Did someone manually publish a modified version of your app to some machine when addressing an ops problem? Source code monitoring would remain blind to such scenarios.
Fundamentally, monitoring dependencies by integrating into your SCM is a great first step, as it’s the easiest and most elegant integration into your developer’s workflow, and greatly simplifies prevention and remediation steps. However, to be fully protected, you should also monitor dependencies in deployed code.
Monitoring Deployed Code
If source code is the start of the dependency journey, the final destination is the deployed application. As I mentioned in Chapter 2, looking for vulnerable libraries in a deployed application gives you the most accurate picture of the security flaws you actually deployed, regardless of how they got there.
The tools you need to continuously monitor deployed apps depends on the platform running these apps. If you are managing your own servers, the common way to monitor deployed applications is using infrastructure monitoring (IM) products, which many endpoint security solutions include. These tools are not aware of specific applications, but rather attempt to discover which components exist on every system (e.g., host, container), and report on known flaws in them. The tools in the infrastructure monitoring are quite evolved and do a great job reporting on vulnerable OS dependencies, but typically fall short or completely ignore vulnerable application dependencies. If you’re using such a tool, make sure to inspect how well it would report on issues in application dependencies.
Infrastructure monitoring products unfortunately don’t work for applications deployed on a Function-as-a-Service (a.k.a FaaS or Serverless), such as AWS Lambda or IBM OpenWhisk, nor for Platform-as-a-Service (PaaS) solutions like Heroku and Cloud Foundry. In their absence, some SCA tools can connect directly to such platforms and inspect each app for vulnerable libraries. As the marketplaces around PaaS and FaaS offerings evolve, I expect we’ll see more continuous monitoring solutions show up, including ones inspecting for vulnerable libraries.
An alternative to monitoring deployed code is to take a snapshot of the dependencies used as part of the application’s (hopefully continuous) deployment process, which brings us to the third common location for monitoring the dependencies used.
Integrating into Continuous Deployment
The path from source code to a built application is captured in our deployment process. If you have a continuous deployment system, you can use it to track which dependencies you’re about to deploy, which you could then use to monitor for vulnerabilities over time. Note that unlike the “prevent” step, which could run in either CI or CD, updating the BOM should be integrated into your continuous deployment workflow, but not the CI (i.e., you shouldn’t update the BOM every time you build, only when you’re about to deploy).
Different tools offer different means to track your BOM in CD. Platform integrations, such as Artifactory or Snyk, integrate into the build system via plug-ins and relate the downloaded packages to the builds to automatically track the BOM. CI systems like Jenkins allow you to store metadata with each build, which can be used to include the BOM. And other tools let you explicitly take a snapshot by calling an API or CLI command at the right time.
Capturing the BOM during CD is typically more accurate than source code, and can be as accurate as monitoring built apps if you also know which apps are deployed and where, so you can respond accordingly. In reality, it tends to work better for capturing the primary and most active applications, which tend to be tracked better, but can get complicated in tracking the long tail of apps you have deployed, or in more elaborate deployment scenarios (e.g., having multiple live versions in parallel).
There’s no single perfect place to track your BOM, as each phase has pros and cons. My recommendation is to track it as part of your source code always, and to amend that by either tracking it in CD or monitoring deployed apps.
Getting a Feed of Vulnerability Notifications
Now that we know the dependencies used at any given time, we need the second data feed: a feed of known vulnerabilities.
If you’re using a commercial SCA tool, odds are it already includes a vulnerability DB within. When running tests using an online solution, the DB is likely to be updated continuously. However, if the SCA tool you use supports running without internet connectivity and you use it in that fashion, you will need to download the DB frequently to ensure it’s up to date.
If you are monitoring your libraries for vulnerabilities without a complete SCA solution, or wish to augment such a tool, you can also license a vulnerability DB directly. Many SCA vendors will offer such a license, and some independent threat intelligence companies sell such vulnerability feeds as products in and of themselves. When licensing a DB directly, make sure it covers open source libraries well, as most vulnerability DBs focus on operating system dependencies but contain minimal information about security flaws in application dependencies.
While a vulnerability DB is always a part of your SCA treatment, the different databases vary greatly in the coverage they offer. The number and caliber of DBs change regularly, requiring you to evaluate the quality of your solution’s DB before you buy. It’s also important to assess the DB against your technology stack, as some DBs do better in certain ecosystems (e.g., Maven) but have minimal coverage for others (e.g., npm), or vice versa.
Beyond the specific differences, there are two particular aspects of a DB we can call out: non-CVE vulnerabilities and early notifications.
CVEs Are Not Enough
As I mentioned at the start of this book, known vulnerabilities are often classified in the public MITRE DB and assigned a CVE. The existence and details of CVEs are in the public domain, allowing all tools to easily query for them and include them in the testing. Many of the open source SCA tools, notably OWASP Dependency Checker, rely exclusively on CVEs and the Common Product Enumeration (CPE) specifications in them to detect vulnerable libraries.
Unfortunately, getting a CVE is a hassle, and because developers and SCA vendors are offered little incentive to file for one, the coverage, accuracy, and content quality of CVEs is severely lacking in the world of open source libraries. CVEs do not capture most new vulnerabilities, the specifications (e.g., vulnerable version ranges) of the vulnerabilities they do capture are often incorrect, and the descriptions they include are typically too short to be helpful.
Many commercial SCA solutions go beyond CVEs and curate their own databases with additional vulnerabilities and richer data, finding issues more accurately and helping to fix them better. When using an SCA solution, check that its DB tracks non-CVE vulnerabilities well.
The failure of the CVE system to properly contain known vulnerability information is a shame, and has sparked many conversations about potential long-term solutions. Hopefully it’ll be solved in the future, but in the meantime—if you want to properly secure your libraries—you will do well to not rely on CVE information alone.
Early Notifications
By definition, known vulnerabilities are public knowledge, and commercial vulnerability databases often track other databases to discover and grow their own lists. In fact, most SCA solutions use a DB that is purely based on copying other databases, and are practically never the first to disclose a new issue. As a consumer, this back-scene process doesn’t impact you greatly, as long as the DB you are using is built legally and is sufficiently accurate and comprehensive.
If you are, however, using a DB that is first to uncover issues, you can take advantage of that by signing up to early notifications. These DBs typically make certain customers aware, confidentially, of vulnerabilities that are going through a responsible disclosure process, allowing them to address these issues before the rest of the world (including attackers) finds out about them. Early notifications are especially valuable for high-value attack targets, such as financial institutions, governments, and similar organizations, as their attackers are often faster then average, while as organizations they’re slower than average to properly defend.
Early notifications require, by definition, exclusivity. If a service offered early notifications to its free or low-cost customers, attackers can easily sign up to receive it as well, defeating the entire point. Therefore, early notifications are, without fail, offered only to enterprise customers or an otherwise hand-curated list of companies. If you work at a large organization and would like to stay a step ahead, look for a DB that is frequently first to disclose vulnerabilities, and inquire about early notification options.
Automating Matching and Notification
Given a DB and the list of dependencies, you’re ready for the final move: intersecting the list of dependencies with the list of vulnerabilities. As long as you have an accurate set of dependencies and vulnerabilities, this step is not that hard—it simply requires looking up each library and version pair in your list in the DB.
Once a vulnerability is found, you can send off notifications in the manner you see fit. As expected, SCA tools offer various notification capabilities, ranging from emails to web hooks to slack notifications. You should also consider more subtle aspects of the notifications, such as which issues merit a notification (e.g., only alert on high-severity issues).
Notifications are a well-understood topic in the world of security and ops, and the majority of SCA functionality in this space is not at all unique, so I will not spend more time on those. I will, however, focus on more SCA-specific topics—notifying dev versus ops, breaking the build on new vulnerabilities, and automating remediation steps.
Who You Should Notify and How
There are at least two audiences that need to find out about a new vulnerability disclosure: security operations and dev.
Security operations (or regular operations in teams that have no SecOps) are the typical recipient of security alerts. They are hopefully familiar with assessing the severity of an incoming issue, responding with the right urgency, and staying alert for potential exploits of this new threat. This team should, at the very least, be alerted on high-severity issues.
The dev team will need to do the actual fixing, and so should be notified as well. Dev teams are accustomed to getting external bug reports as well, typically in the form of a logged issue. What isn’t standard, though, is how to address the urgency of the issue. You should inspect your internal processes to determine the best way to raise urgency in addressing a high-severity security issue, to keep it from being lost in the backlog, or simply pushed to the next sprint.
Automating Remediation Steps
While logging an issue is a standard way to alert the dev team, an even better way is to submit a pull request with the changes needed to fix the problem. The best bug reports are those that come with a fix built into them!
Certain SCA tools offer automated fix pull requests as part of their notifications flow. If connected to your source control, such tools can determine the changes needed to fix the issue (as explained in Chapter 3), and proactively open a pull request with those changes. Automated fix PRs are good for various reasons, including:
Clear indication of what it takes to fix the issue, saving quite a few steps in the triage process
Faster remediation, as opening a fix PR with the needed changes is a step a developer would have to do anyway
Better visibility, as typically dev teams are faster to notice and respond to PRs than they are to issues
Less likelihood of being ignored, as dev teams aim to not keep PRs open forever, and are more likely to either close or merge the issue
Fix PRs are a great way to expedite remediation, but they don’t go all the way. If your system allows it, consider keying off these fix PRs to trigger a non-production deployment and all the tests that go with it. Ideally, by the time a human looks at the issue and approves the fix, the fixed version is just one step away from production. Figure 1-1 shows an automated fix pull request to a newly disclosed vulnerability, made possible by using source code scanning.
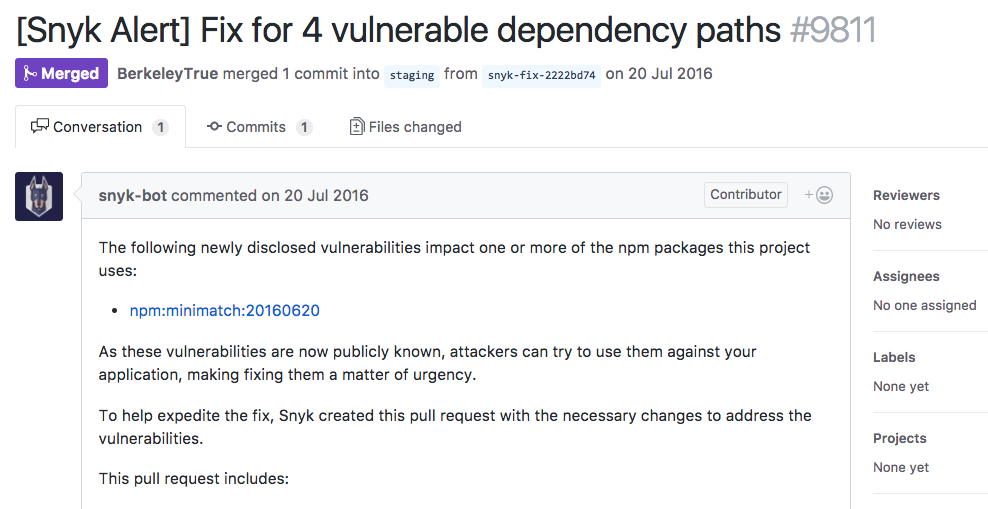
Breaking a Build on a New Vulnerability
Chapter 4 discussed the impact of breaking builds on newly disclosed vulnerabilities versus newly added vulnerabilities. Failing builds (or other gates) is also a form of notification, but a somewhat brutal one. There’s no point in repeating the information from Chapter 4 about testing changesets versus builds, but it’s worth referring back to “Failing on Newly Added Versus Newly Disclosed Issues” when planning your notifications process.
Becoming Vulnerable Due to Dependency Chain Updates
This chapter focused on responding to new vulnerability disclosures that affect you, which is the only way your deployed applications may suddenly have known vulnerabilities. However, your source code may also become vulnerable because of changes in its dependency tree.
For instance, say your app depends on package A@^1.0.0, meaning A at version 1.0.0 or newer, but less than 2.0.0. Let’s also assume version A@1.0.1 is the latest version, and has no further dependencies. Now, what happens if a new version is released, A@1.0.2, which uses a vulnerable package V?
The applications you deployed yesterday would remain unharmed, as they were built before A@1.0.2 came out. They resolved the version range to A@1.0.1, downloaded it, and deployed a vulnerability-free app. However, if you build your app again, without any code changes whatsoever, the version range will resolve to A@1.0.2 and the build will pull in the vulnerable package V!
A similar scenario may occur during conflict resolution or de-duplication performed by your package manager. It’s quite possible a new dependency, either direct or indirect, would change the eventual versions picked for every library, and introduce a new vulnerability.
While not as severe as a new disclosure, it’s important to monitor your source code for these types of changes as well, to facilitate fixes. Because your deployed applications are unharmed, there is no need to look for these issues in built apps. SCA tools that can monitor source code are typically able to address this concern.
It’s worth noting that this scenario only happens if you are using version ranges and not using a lock file. If you are using a pinned version (most common in Maven) or using a lock file that explicitly states each library’s version (e.g., Gemfile.lock, yarn.lock), your library versions are guaranteed to stay the same.
Summary
Responding to newly disclosed vulnerabilities is where your true defensive skills shine. Each vulnerability disclosure triggers a race between attacker and defender, and while attackers are fine with only an occasional win, you need to beat them every single time.
The key to success lies in speed. Learn about the issues quickly, map them to the relevant vulnerable application, and either fix or mitigate the risk. Just like I stated in the summary to Chapter 2, fast response without comprehensive coverage is not going to be enough, so make sure all your apps are under control.