 America on 1791 globe by George and Dudley Adams (London) in Teyler's Oval Room, Teylers Museum. (source: By Jane023 on Wikimedia Commons)
America on 1791 globe by George and Dudley Adams (London) in Teyler's Oval Room, Teylers Museum. (source: By Jane023 on Wikimedia Commons) The global economy is maturing around the backbone of the Internet and related technologies. Being a “data-driven” company is now the norm, and globalizing your data—or making your data available to customers worldwide—is the basic entry fee for participating. A lot has changed in the past 20 years to get us here. Traditional solutions that worked then, don’t work today. How do we know? Experience. Infrastructure fails. Users get angry and demand change or go somewhere else. Projects with big aspirations fall into ruin.
This isn’t meant to be all gloom and doom. Those 20 years of experience amount to an engineering problem that has new solutions. Engineers at Amazon were facing this problem in 2007, and as a result, released the Dynamo paper, which described how to build a database that was scalable and resisted inevitable failures. Following the release of this paper, many implementations followed to chase that ideal. The one that has risen to the top and is leading the charge on distributed database problems is Apache Cassandra. This is the one database that follows a simple principle: if your business is global, your data should be, too.
It’s 3 a.m., where is your data?
No matter how well you plan, getting anything close to 100% reliability in a single data center is almost impossible. There are too many things conspiring against your uptime. Natural disasters. Human error. Sharks attacking undersea cables. I don’t think anyone predicted the latter, but it happened, and it caused a lot of problems. Even inside a data center, partial failures can lead to complete outages. As a result, we have built incredibly complex ways to deal with potential failure. As it goes, complex things fail in complex ways.
The original Dynamo paper was driven by the need for uptime. Cassandra followed with adhering to replication as a first principle. Expecting failure puts you in the right position for dealing with its inevitability. Single servers fail, so spread data around the data center. Data centers fail, so spread data geographically. All these layers combined give you the best chance at 100% uptime. Cassandra handles this with very little interaction from the operator.
What about in-cloud deployments? You could almost say that Cassandra was built for the cloud. Typical deployments in AWS spread data over multiple availability zones (AZs) and then multiple regions. Netflix has been quite vocal about how they deploy across multiple regions in a multiple-data-center configuration. Now we are starting to see cross-cloud vendor deployments. If one public cloud is having a problem, no worries. Your data is safe and you are online. This will be a more prevalent theme over the coming years as consumers of cloud computing take steps to avoid lock-in.
Slow is as good as down
It may seem as if the world is shrinking as business becomes more global, but no surprise: it’s still the same physical size. Why am I mentioning something so obvious? Because of what’s not so obvious to many—that distances impact the latency across a network connection. If a single photon was sent on a trip around the planet in the most optimal conditions, that trip will take a noticeable 134 milliseconds. Sorry, there is no way to speed that up. That’s physics, and that’s the law.
What does that mean in more real-world terms? A round trip to New Delhi from San Francisco can take a painful 300 milliseconds over the Internet. Amazon and Google have both presented how increased latency can lead to decreased revenue. As little as 100 millisecond difference can lead to a measurable drop. If you are a U.S. company trying to do business in India, your baked-in 300 millisecond delay is going to be a distinct disadvantage to any company working out of a local data center. Anyone serving data locally will have an instant advantage with user satisfaction.
Users of Apache Cassandra are dealing with this reality head on. Servicing users simultaneously from two or more data centers (known as Active-Active) is not just about uptime, but also about user satisfaction. Making your data available closer to your users is a competitive advantage. Spotify realized this a long time ago and made their business more global. If you are too slow, users move on to a similar, faster version of whatever you are doing and never come back. With reliable replication at the data layer, you can serve your data using the application layer closest to your users.
All your data belongs to us
Doing business globally means working within the laws of the countries you do business. Government lawmakers have been catching up with the rapid proliferation of data and the implications on their citizens. Just recently, the EU Data Protection commissioner ruled that the “Safe Harbour” provisions in EU data protection laws are invalid. The impact of this decision now means users’ personal data must remain inside the EU borders and can no longer be used in the U.S. If you have data centers in both regions, be very careful about how that data is replicated.
Replication in Apache Cassandra is configurable to the needed granularity to solve this problem. I’ll use the diagram below as an example:
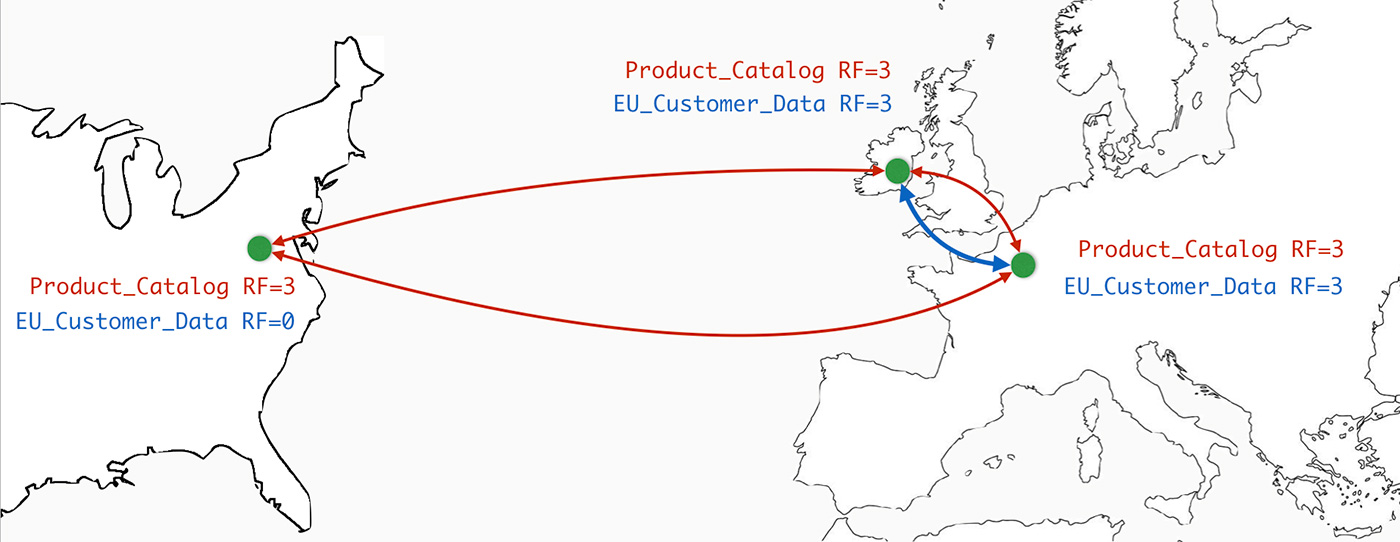
In this scenario, we have two separate keyspaces configured for different use cases. A keyspace contains tables of data and holds replication parameters. The number of replicas, called replication factor (RF), can be specified for each data center. So an RF=3 would mean we have three copies of data per data center.
The “Product_Catalog” keyspace contains no personal data, so it is safe to cross international boundaries. For each data center, we specify an RF of three. This data is now being served locally wherever the customers reside.
The “EU_Customer_Data” keyspace has different requirements. Because this is personal data, we will restrict the replication to just inside the EU and prevent replication to the U.S. By specifying an RF of zero, we are effectively turning off any replication to the U.S. data centers. Replication can still occur between data centers in Germany and Ireland. Since this is a configuration value, audits and process control can be put in place to ensure enforcement.
The future is now and ready to use
Take a good look in your data center. If you are using 20th century databases to serve 21st century needs, then it’s time to plan your next move—it’s almost guaranteed your competitor is. Learn more about Apache Cassandra through free online courses by the DataStax Academy, with topics ranging from data modeling to operations and architecture. Plus, join me at Strata + Hadoop World San Jose for An Introduction to Time Series with Team Apache on March 29th, 2016.