
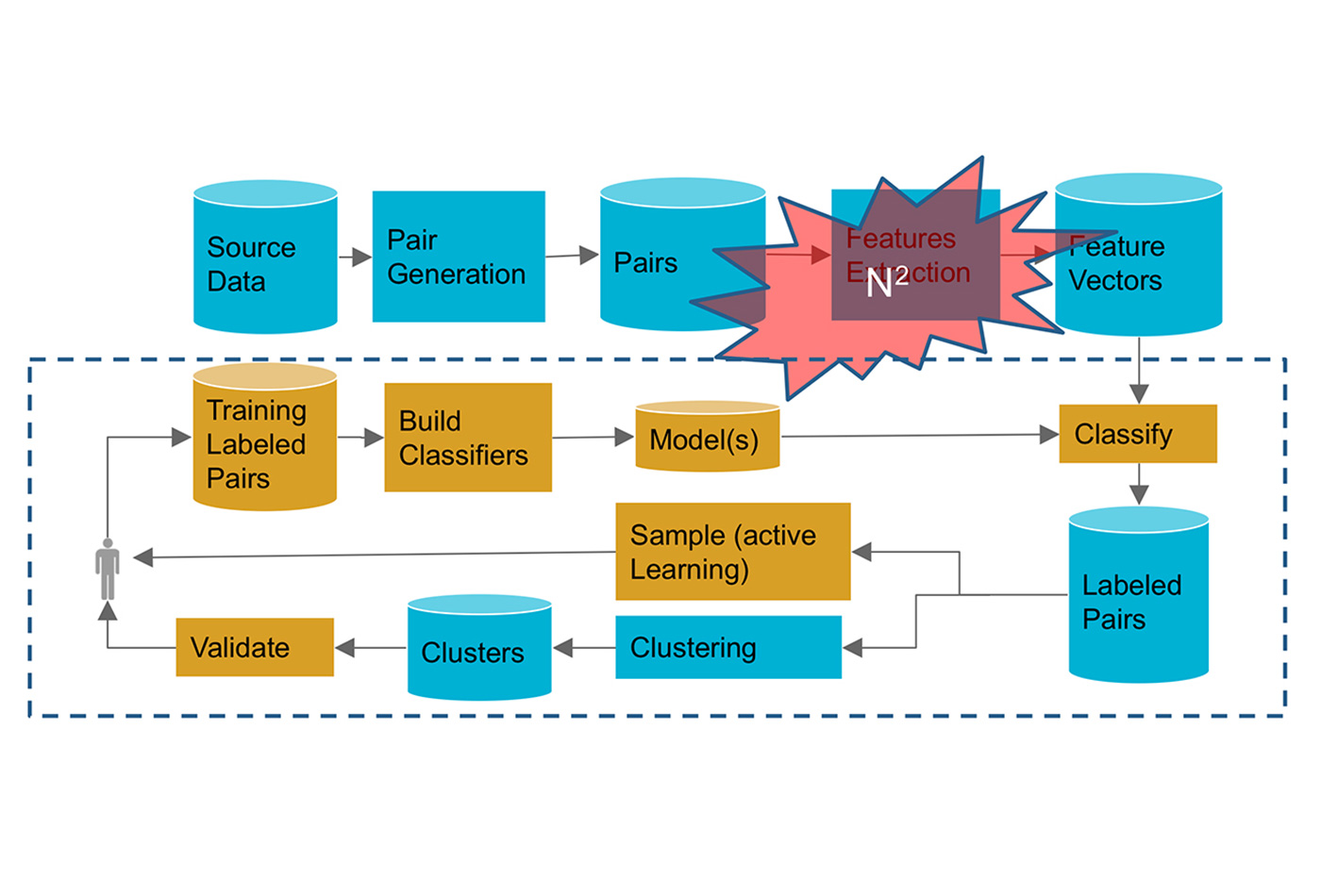
 An ML pipeline for record deduplication (source: Image by Ihab Ilyas, used with permission)
An ML pipeline for record deduplication (source: Image by Ihab Ilyas, used with permission) Data unification is the process of combining multiple, diverse data sets and preparing them for analysis by matching, deduplicating, and otherwise cleaning the records (Figure 1). This effort consumes more than 60% of data scientists’ time, according to many recent studies. Moreover, it has been shown that cleaning data before feeding it to machine learning (ML) models (e.g., to perform predictive analytics) is far more effective than trying to fiddle with model parameters and feature engineering applied to dirty data. These facts render data cleaning activities absolutely necessary, yet unfortunately both tedious and time-consuming, given the state of the tools available to most data scientists. The use of machine learning models for analytics is well-understood for predicting end-of-quarter spending, capacity planning, and deciding on investment portfolios. However, the application of machine learning to data unification and cleaning, although effective in dealing with vast amount of dirty and siloed data, faces many technical and pragmatic challenges.

This post highlights two main examples of using ML in data unification and cleaning: record de-duplication and linkage, and automatic data repair. We also discuss the main difference between using ML in data unification and cleaning, in contrast to using ML models in data analytics.
Machine learning for data unification and cleaning
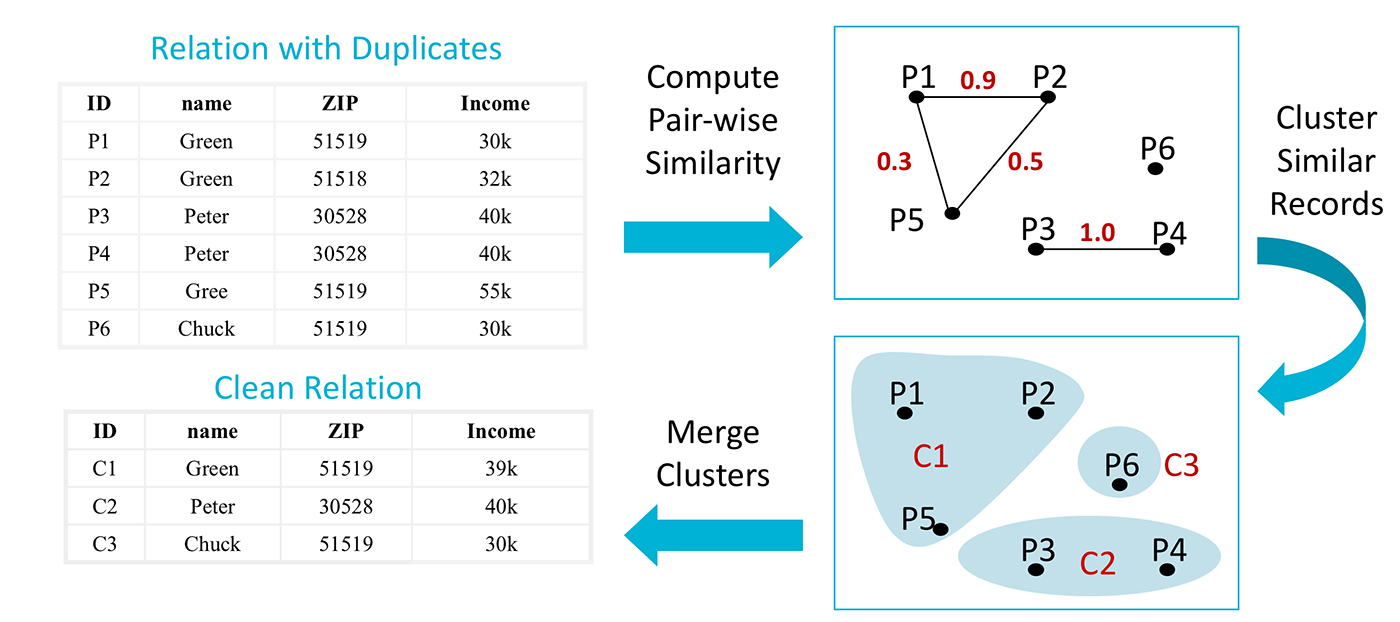
Record linkage (deduplication) is a good example of a machine learning approach to data unification (like the one provided by Tamr or the open source software package Febrl). In deduplication, we are looking for an accurate and scalable way to cluster records (possibly from various data sources) that represent the same entity, and hopefully consolidate the clusters in order to produce “golden” records that can be fed to downstream applications and analytics. Figure 2 shows the main steps of the deduplication exercise. Various use cases need this core capability, from customer data integration to consolidating ERP systems for cost-effective procurement. At the core of record linkage is the task of deciding if two records belong to the same entity (for example, a particular customer). This looks like a classic “classification” exercise, and with enough training data (examples of duplicates and example of non-duplicates), we ought to be able to build multiple models that can classify pairs of records as matches or non-matches. Matched pairs can then be clustered using your favorite clustering algorithm.
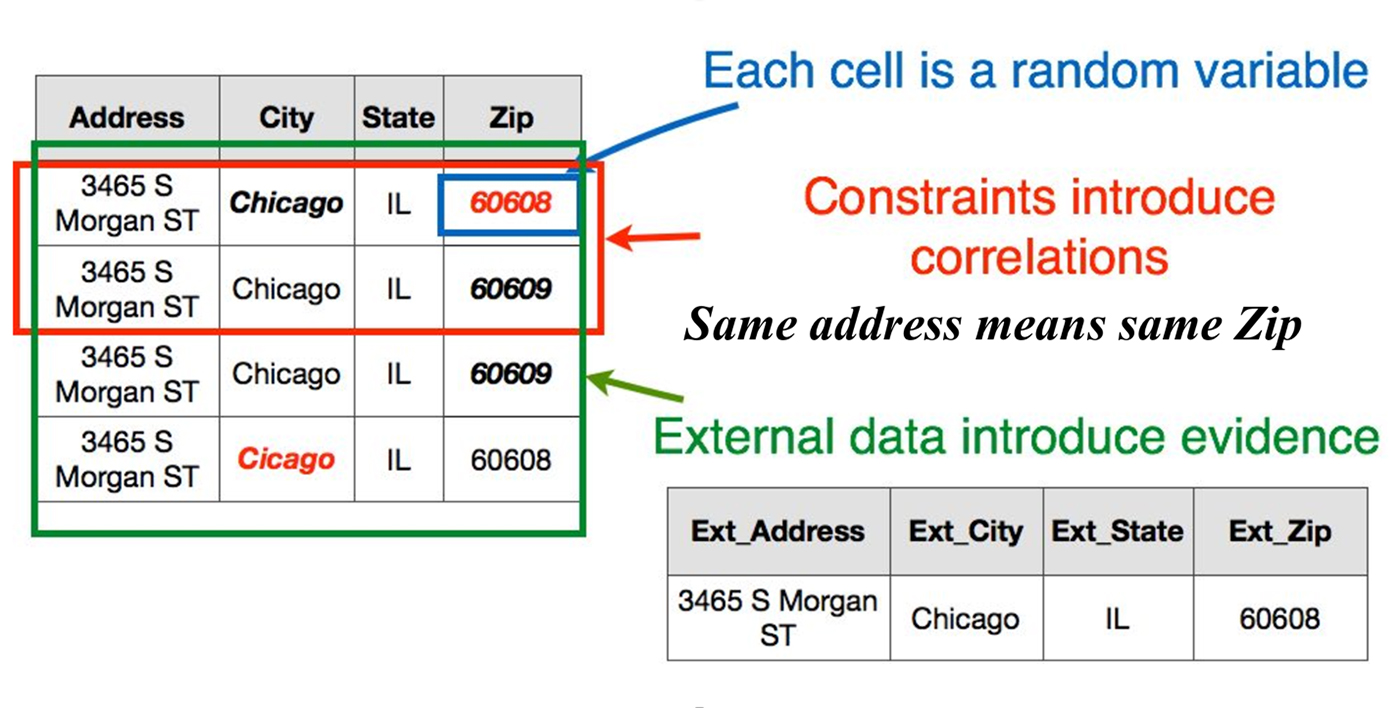
Record repair is another use of ML in data cleaning, and an important component of unification projects. Repairing records is mainly about predicting the correct value(s) of erroneous or missing attributes in a source data record. The key is to build models that take into account all possible “signals” in predicting the missing or erroneous value. For example, in the HoloClean system (read a blog post about it here), we can view each cell in a source table as a random variable, and we need to use dictionaries, reference data sets, available rules and constraints, and similar entries in the database to provide the “maximum likelihood” value for these random variables (see Figure 3).
Characteristics and differences from ML for analytics
The main difference in using ML models in data unification is a matter of scale, legacy, and trust. Here are some key differences between ML for analytics and ML in cleaning:
- Upstream versus downstream: Analytics are exploratory in nature, and data scientists usually feel free to use all sorts of models to answer “what-if” questions. On the other hand, data unification and data cleaning introduce fundamental updates to the upstream source data, which propagates through all the processing and analytics pipelines. For example, changing the address of one of your key customers is an irreversible action that will be fed into all future analytics and reporting. As a consequence, data owners have to “trust” these fundamental changes before consuming the data downstream. The idea of a “human in the loop” is not only advisable, but a key component in any effective ML-based cleaning approach, as it goes beyond labeling training data to reviewing results, assessing downstream impact, and explaining predictions in a way a business analyst can understand. The impact of building “trustworthy” solutions is pervasive and affects model choices, training data acquisition, and integrated provenance systems that allow explainability and “rollbacks.”
Legacy scripts and rules: The legacy of traditional approaches to data integration have left companies with many man-years of encoding business rules as ETL scripts, which collectively represent the institutional memory of the enterprise around various data sources. Ignoring this legacy is usually a non-starter, and a main cause of disconnect between the solution provider and the use case owner. A concrete ML challenge is how to “absorb” and “compile” all available rules into signals and features that bootstrap and guide the learning process. The obvious choice of using available rules and scripts to generate training data, while plausible, faces multiple technical challenges: how to avoid building a biased model, how to reason about the quality of the training data generated this way, and how to learn from such noisy training data. Recent research in ML, such as Snorkel, addresses some of these points; however, applying these principles in the enterprise is still an open challenge.
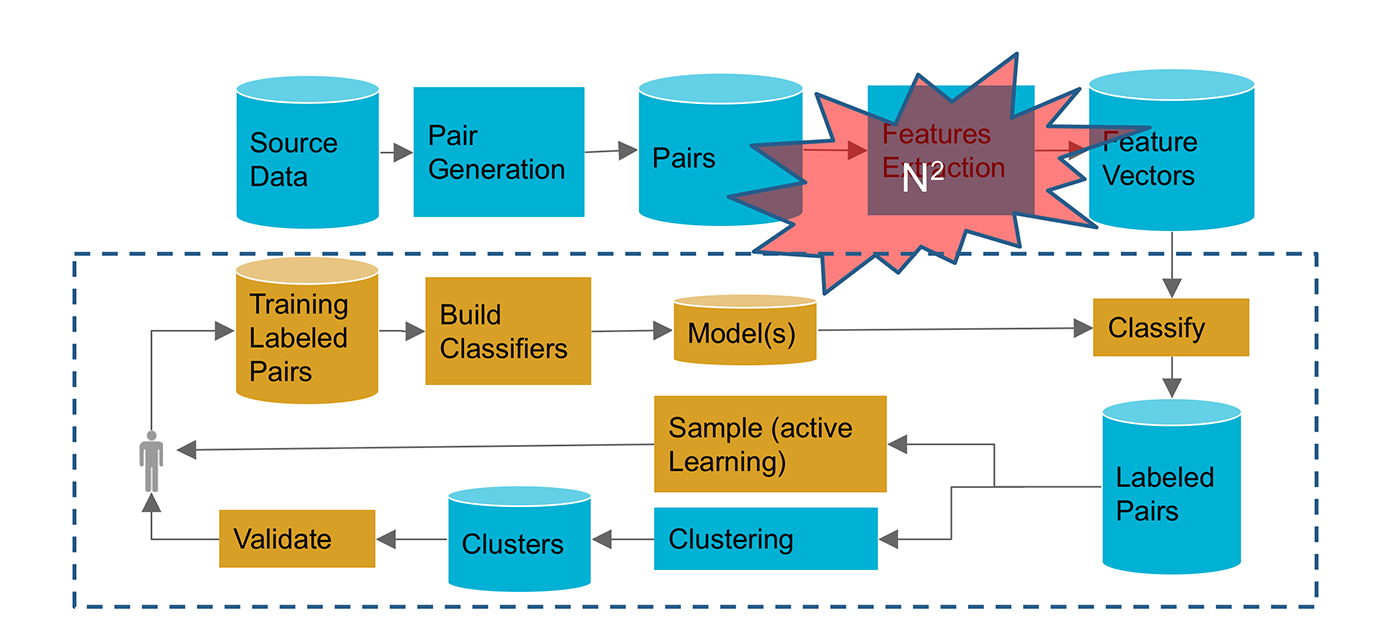
Figure 4. An ML pipeline for record deduplication. Image by Ihab Ilyas. - Scale: Since data unification and cleaning is performed primarily upstream, dealing with large-scale data sources is one of the main challenges in applying machine learning models. Unlike analytics on a specific vertical or on a specific data source, data cleaning often involves running inference or prediction on a massive scale. Take for example the deduplication problem; since we are running a matching classifier on pairs of records, the problem is fundamentally of quadratic complexity: to deduplicate 1M records, we need to run our classifier on O(10^12) feature vectors representing the similarities between every pair (see Figure 4). The problem is not easily parallelizable (due to the cross comparison and shuffling needed). Hence, well-engineered solutions that focus on cutting down this complexity using techniques like sampling, locality sensitive hashing, blocking, and so on are a must. As another example, consider our second use case for predicting data repair: treating each cell in a table as a random variable means running inference on millions of random variables, something that will be break most off-the-shelf inference engines. Applying an extensive set of technologies to scale out probabilistic inference is a harder challenge that systems like HoloClean tackle.
These main characteristics of using machine learning pipelines in data unification and cleaning necessitates a human-guided solution where people are involved in many tasks, such as:
- Helping transition rules and legacy ETL into features and labeling tools to generate training data necessary to train the various models
- Continuously reviewing the results—for example, the produce clusters in case of deduplication—in a way that relates to the business and the use case
- Providing provenance and use information to allow for tracking and explaining ML decisions
- Assessing the impact of the ML pipeline on downstream applications and analytics
Note that these tasks require “different” sets of expertise and distinct roles of people who need to be involved: domain experts are the best choice to provide rules, validate the machine decision, and provide training data; data owners are needed to authorize trusted updates, identify relevant data, and control consumption channels; IT experts deploy and guide the continuous monitoring of the deployed ML pipelines and trigger the need for debugging or revising the models; and finally business analysts judge the effectiveness of the deployed solution and evaluate the effectiveness of the solution on the downstream applications.
In summary, human-guided ML pipelines for data unification and cleaning are not only needed but might be the only way to provide complete and trustworthy data sets for effective analytics. However, applying ML for unification and cleaning involves different sets of logistics and technical challenges, a matter of scale, legacy, and trust.