
 Peggy Bacon in mid-air backflip, Bondi Beach, Sydney, 6/2/1937 / by Ted Hood. (source: State Library of New South Wales on Flickr)
Peggy Bacon in mid-air backflip, Bondi Beach, Sydney, 6/2/1937 / by Ted Hood. (source: State Library of New South Wales on Flickr) What’s commonly expected from a data scientist is a combination of subject matter expertise, mathematics, and computer science. This is a tall order and it makes sense that there would be a shortage of people who fit the description. The more knowledge you have, the better, however, I’ve found that the skillset you need to be effective, in practice, tends to be more specific and much more attainable. This approach changes both what you look for from data science and what you look for in a data scientist.
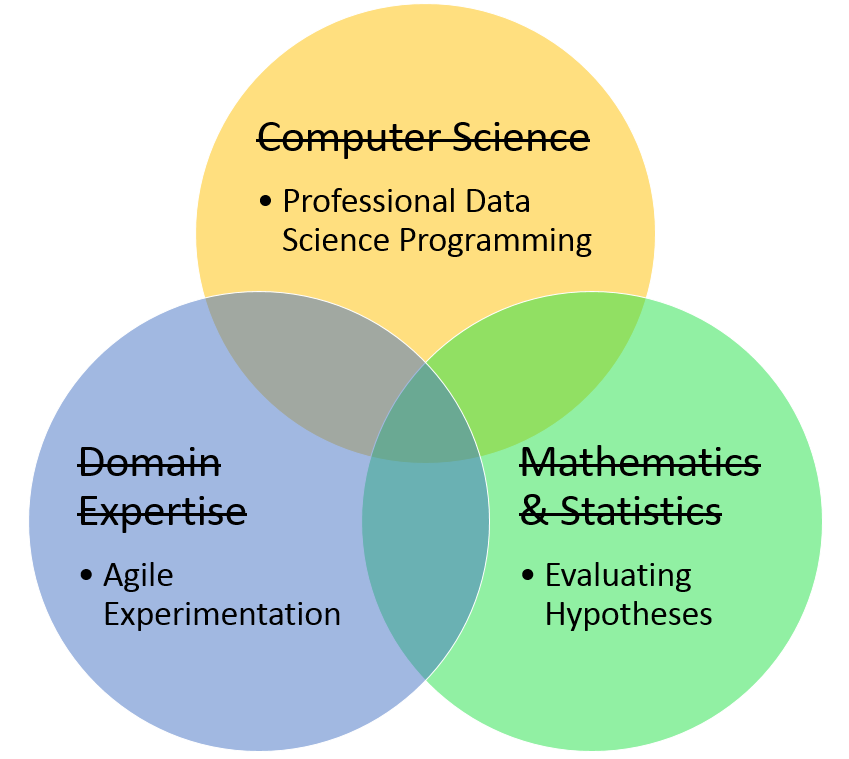
A background in computer science helps with understanding software engineering, but writing working data products requires specific techniques for writing solid data science code. Subject matter expertise is needed to pose interesting questions and interpret results, but this is often done in collaboration between the data scientist and subject matter experts (SMEs). In practice, it is much more important for data scientists to be skilled at engaging SMEs in agile experimentation. A background in mathematics and statistics is necessary to understand the details of most machine learning algorithms, but to be effective at applying those algorithms requires a more specific understanding of how to evaluate hypotheses.
In practice, data scientists usually start with a question, and then collect data they think could provide insight. A data scientist has to be able to take a guess at a hypothesis and use it to explain the data. For example, I collaborated with HR in an effort to find the factors that contributed best to employee satisfaction at our company. After a few short sessions with the SMEs, it was clear that you could probably spot an unhappy employee with just a handful of simple warning signs — which made decision trees (or association rules) a natural choice. We selected a decision-tree algorithm and used it to produce a tree and error estimates based on employee survey responses.
Once we have a hypothesis, we need to figure out if it’s something we can trust. The challenge in judging a hypothesis is figuring out what available evidence would be useful for that task. I believe that the most important quality to look for in a data scientist is the ability to find useful evidence and interpret its significance. In data science today, we spend way too much time celebrating the details of machine learning algorithms. A machine learning algorithm is to a data scientist what a compound microscope is to a biologist. The microscope is a source of evidence. The biologist should understand that evidence and how it was produced, but we should expect from our biologists, contributions well beyond custom grinding lenses or calculating refraction indices.
A data scientist needs to be able to understand an algorithm. But confusion about what that means causes would-be-great data scientists to shy away from the field, and practicing data scientists to focus on the wrong thing. Interestingly, in this matter we can borrow a lesson from the Turing Test. The Turing Test gives us a way to recognize when a machine is intelligent — talk to the machine. If you can’t tell if it’s a machine or a person, then the machine is intelligent. We can do the same thing in data science. If you can converse intelligently about the results of an algorithm, then you probably understand it. In general, here’s what it looks like:
Q: Why are the results of the algorithm X and not Y?
A: The algorithm operates on principle A. Because the circumstances are B, the algorithm produces X. We would have to change things to C to get result Y.
Here’s a more specific example:
Q: Why does your adjacency matrix show a relationship of 1 (instead of 3) between the term “cat” and the term “hat”?
A: The algorithm defines distance as the number of characters needed to turn one term into another. Since the only difference between “cat” and “hat” is the first letter, the distance between them is 1. If we changed “cat” to, say, “dog”, we would get a distance of 3.
The point is to focus on engaging a machine learning algorithm as a scientific apparatus. Get familiar with its interface and its output. Form mental models that will allow you to anticipate the relationship between the two. Thoroughly test that mental model. If you can understand the algorithm, you can understand the hypotheses it produces and you can begin the search for evidence that will confirm or refute the hypothesis.
We tend to judge data scientists by how much they’ve stored in their heads. We look for detailed knowledge of machine learning algorithms, a history of experiences in a particular domain, and an all-around understanding of computers. I believe it’s better, however, to judge the skill of a data scientist based on their track record of shepherding ideas through funnels of evidence and arriving at insights that are useful in the real world.