
 Twyfelfontein Binoculars. (source: By Santiago Medem on Flickr)
Twyfelfontein Binoculars. (source: By Santiago Medem on Flickr) In the first post of this series, I reviewed the various technologies and approaches developed over the past 25 years to analyze the data that organizations produce and collect. I argued that our ability to manage data is getting better, but our ability to analyze data is falling behind. Even though we have the tools and the processes to deal with the soaring volume, velocity, and variety of big data, we are not producing enough data scientists. Furthermore, relying strictly on data scientists to analyze data no longer suffices. In order to make effective decisions utilizing the data we collect, we need big data applications and, increasingly, insightful applications. In this post, I’ll focus on big data applications, and track their evolution and present the current state of their practice. In the next and final post, I’ll present insightful applications, which represent the future of big data applications.
Early adopter experimentation gives way to cross-industry excitement
According to a 2012 Forbes article, which referenced a Gartner survey, initial interest in big data came from the usual suspects—financial services, telco, manufacturing (particularly consumer packaged goods), and government.
Early adopters in these industries started using their newly installed big data infrastructures (e.g., HDFS, MapReduce, NoSQL databases) to experiment with a few applications. According to data gathered by Pacific Crest, shown in Figure 1, these initial efforts centered around trying to use the log data collected from their IT infrastructures (servers, network routers, and various IoT sensors they increasingly connect to their networks) to address problems such as network analysis and IT system performance analysis. According to the same research, other areas that drew corporate interest included the analysis of financial data (to detect fraud), and the analysis of Web data (to perform sentiment analysis, provide more personalized experiences, and improve the effectiveness of online marketing).
| Use Case | Early Adopters Penetration |
|---|---|
| Network analysis | 29% |
| IT system log analysis | 28% |
| Sensor data analysis | 19% |
| Web behavior data analysis | 16% |
| Genome data analysis | 9% |
| Social media sentiment analysis | 6% |
| Fraud detection | 6% |
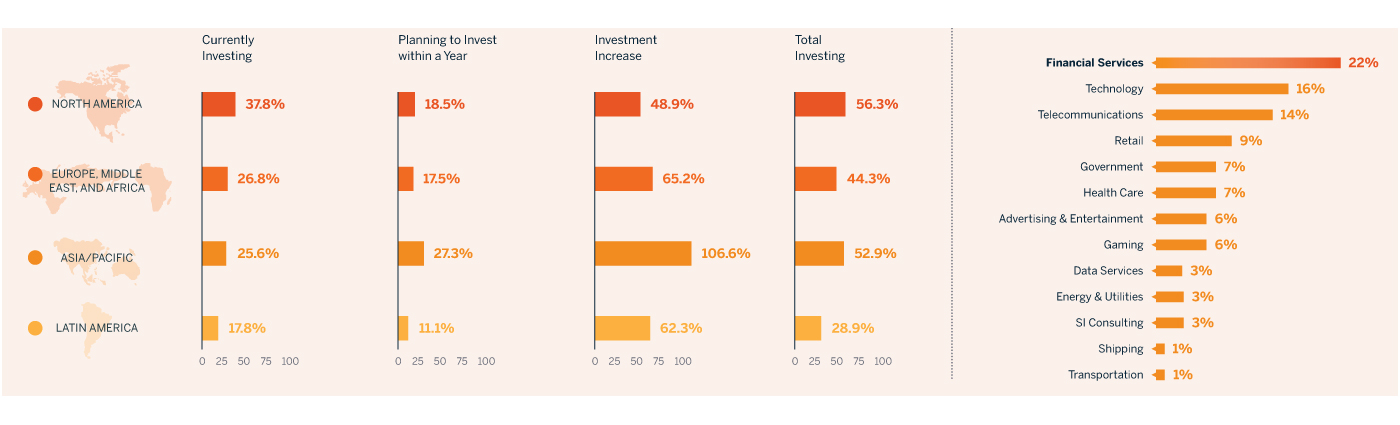
The initial experimentation was extremely important in helping the early adopters understand the benefits, opportunities, and shortcomings of the installed big data infrastructures. However, according to a report published by CapGemini in 2014, this experimentation by the early adopters was not broadly successful. There are three main reasons for this lack of initial success: 1) the data was scattered across many different teams; accessing it required more effort than initially anticipated. 2) The data was housed in legacy systems; extracting and storing it in big data infrastructures was difficult. 3) There was a lack of clear coordination between a corporation’s data management and the data analysis functions; deriving value from the stored data was more challenging. Because these issues were eventually overcome and the early adopters started reporting growing numbers of reported successes and strong returns on their investment (and here), we have recently started seeing strong interest in the broader adoption of big data infrastructures across every geography and from additional industries (see Figure 2).
Continued corporate investment leads to aggressive venture investment in big data startups
Corporate investment in big data continues to grow. According NewVantage, 27% of the corporations surveyed indicated that they will invest more than $50 million in big data projects by 2017. In a 2014 survey by the same firm, only 5.4% of the corporations that participated invested more than $50 million in big data projects.
Today, corporations in trillion-dollar industries such as health care, insurance, agriculture, energy, pharmaceutical, education, automotive, and transportation and logistics are aggressively exploring how big data will enable them to address important problems while they continue to bring big data systems into production. In each such industry, one or two strategic problems typically drive corporate investments. For example, automakers are interested in analyzing consumer infotainment choices to provide personalized in-vehicle infotainment experiences, and they’re also interested in analyzing each vehicle’s performance data to better understand a vehicle’s preventive maintenance needs. Wireless carriers are interested in analyzing consumer usage data to better understand how to monetize the content they offer.
Buoyed by rising corporate investments and the overall prospect of revolutionizing the industries mentioned above, venture investors have also been investing aggressively (and here) in big data startups, many of which are shown in Figure 3. In 2015 alone, VCs invested $6.7 billion in big data startups, up from $6 billion in 2014.

For the same reasons we’re seeing rising corporate and venture investment in big data, we have also started to see acquisitions of some big data startups. Notable early transactions include AOL’s acquisition of Convertro, Google’s acquisition of Adometry, Apple’s acquisition of Topsy, Teradata’s acquisition of Aster Data and Think Big Analytics, and Salesforce’s acquisition of Edgespring. More recently, we saw the acquisition of Revolution Analytics by Microsoft, Pentaho’s acquisition by HDS, and 1010Data acquisition by Advance. While these are more notable because of the transaction size, there are several other smaller acquisitions such as Amiato’s acquisition by Amazon.
As can also be seen in Figure 3 above, the majority of the venture investments to date have been in the areas of big data infrastructures and tools. While the deployment of infrastructure and tools will continue as more industries in more geographies embrace big data, we are now starting to see the introduction of big data applications.
The rise of big data applications
Every new field of information technology (e.g., business intelligence, client/server computing, cloud computing, mobile computing) typically develops in three phases:
- Deployment of infrastructure. In the case of big data, such infrastructure is used for the storage, management, movement, and transformation of data.
- Deployment of tools that capitalize on infrastructure. In the case of big data, such tools are used for the search and analysis of the various forms of big data as well as for the presentation of results.
- Introduction of applications typically capitalizing on the infrastructure and the tools.
Following such a phased approach, corporations such as Aetna, Walgreens, JP Morgan Chase, and many others have been deploying big data infrastructures and various tools in order to analyze the data they collect.
Because we are now entering the application development and deployment phase, it is important to look more closely into this type of software. To date, we have identified three types of big data applications:
- Shallow applications that perform such tasks as customer churn analysis and are developed around general-purpose analytic tools (e.g., Dataminr, DataRobot). These applications are supported by data scientists working through a well-defined process. These typically horizontal applications provide a shallow layer of business logic on top of the analytic tool on which they are based. The analytic models and reports driving the application are developed and maintained by data scientists as well as other services professionals, some of whom may be provided by management consulting firms, that understand the domain and the end user’s needs. The end user is typically a business analyst.
- Applications processing big data but not utilizing any form of predictive or prescriptive analytics (e.g., Socrata, Zuora). These applications may be horizontal, such as Zuora’s, or vertical, such as Socrata’s that targets government. They give the end-user, typically a business analyst, the ability to understand the data they process through a variety of reports. For example, the City of New York uses Socrata’s system for financial reporting.
- Applications with embedded predictive analytics. These applications are further subdivided into two groups.
- The first group includes the applications whose predictive models are developed, and periodically updated, offline by data scientists. This means that the vendors of these applications must have a strong services capability in addition to their software capability. Example applications in this group are developed by AgileOne, OPower, Zephyr Health, Duetto, and several online advertising applications such as DataXu and MediaMath.
- The second group includes the applications whose predictive models are developed automatically by the application itself. Example applications in this group are developed by Oration and Namogoo.
The applications that belong in this category may be either horizontal (e.g., AgileOne, Namogoo) or vertical (e.g., OPower for utilities, Duetto for travel, or Oration for insurance).
These three big data application types can be thought of as predecessors to insightful applications, which represent a fourth big data application type. The applications in the third group come the closest to insightful applications with one important distinction: they are able to predict but are not able to generate insights. In other words, they are not able to perform actions in response to the predictions they make. Instead, they rely on their user to identify and perform an appropriate action in response to a particular prediction.
Conclusion
Despite facing some bumps (which happens with the adoption of every new technology), early adopters of big data have been joined by corporations from many industries across all geographies in investing aggressively in big data projects and deploying big data systems that address important industry problems. Realizing big data’s cross-industry potential, venture investors have been investing aggressively in big data startups whose solutions are at the heart of the systems adopted by corporations. Having laid the requisite big data infrastructure and deployed analytic tools, corporate attention has been turning to big data applications. We identified three types of big data applications that have been introduced to date. Several of these early horizontal and vertical applications are able to provide predictions but not insights and actions, the key differentiating characteristic of insightful applications. In the next post, I will explore insightful applications, which represent the fourth and most promising type of big data application.