
 Stockton Infinity Bridge (source: darren price on Flickr)
Stockton Infinity Bridge (source: darren price on Flickr) As more companies begin to experiment with and deploy machine learning in different settings, it’s good to look ahead at what future systems might look like. Today, the typical sequence is to gather data, learn some underlying structure, and deploy an algorithm that systematically captures what you’ve learned. Gathering, preparing, and enriching the right data—particularly training data—is essential and remains a key bottleneck among companies wanting to use machine learning.
I take for granted that future AI systems will rely on continuous learning as opposed to algorithms that are trained offline. Humans learn this way, and AI systems will increasingly have the capacity to do the same. Imagine visiting an office for the first time and tripping over an obstacle. The very next time you visit that scene—perhaps just a few minutes later—you’ll most likely know to look out for the object that tripped you.
There are many applications and scenarios where learning takes on a similar exploratory nature. Think of an agent interacting with an environment while trying to learn what actions to take and which ones to avoid in order to complete some preassigned task. We’ve already seen glimpses of this with recent applications of reinforcement learning (RL). In RL, the goal is to learn how to map observations and measurements to a set of actions, while trying to maximize some long-term reward. (The term RL is frequently used to describe both a class of problems and a set of algorithms.) While deep learning gets more media attention, there are many interesting recent developments in RL that are well known within AI circles. Researchers have recently applied RL to game play, robotics, autonomous vehicles, dialog systems, text summarization, education and training, and energy utilization.
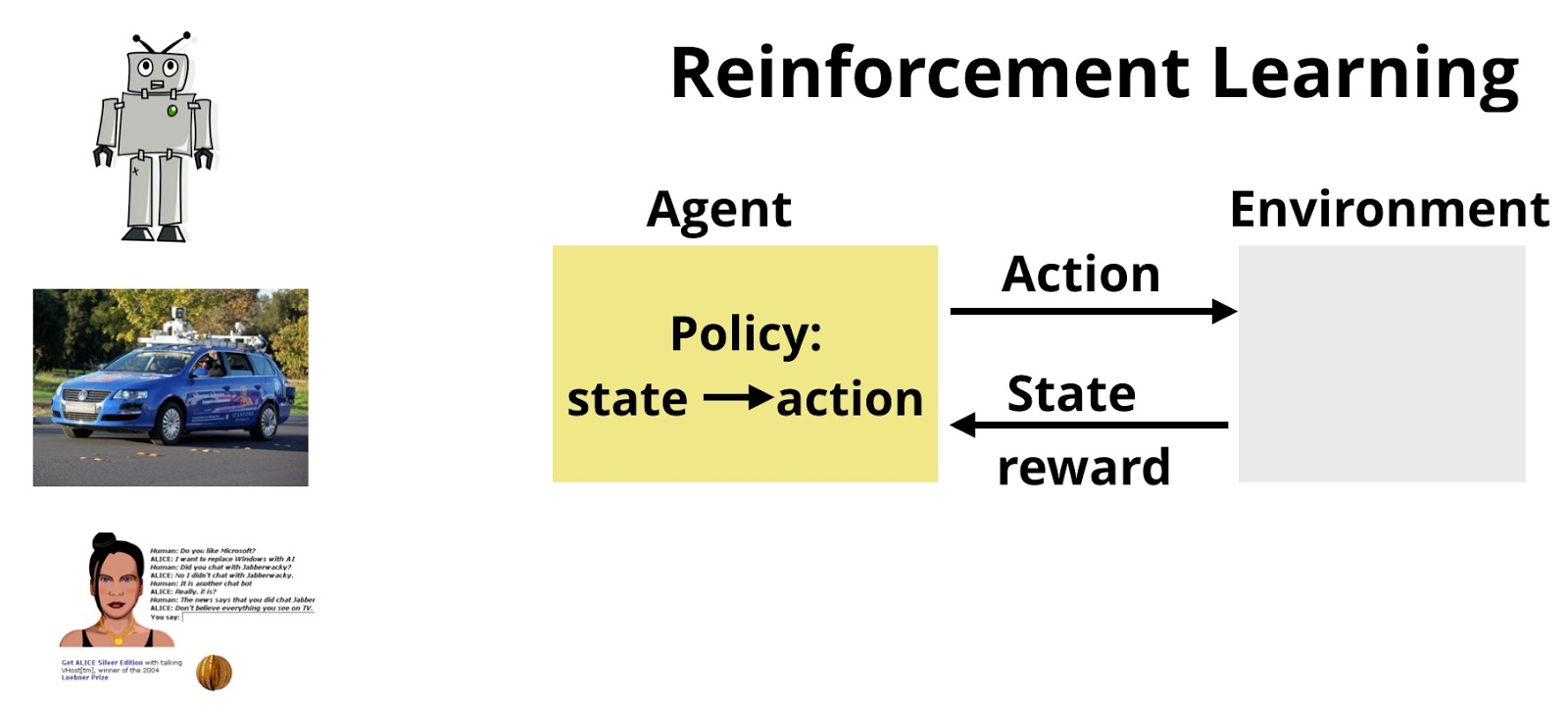
Just as deep learning is slowly becoming part of a data scientist’s toolset, something similar is poised to happen with continuous learning. But in order for data scientists to engage, both the tools and algorithms need to become more accessible. A new set of tools and algorithms—different from the ones used for supervised learning—will be required. Continuous learning will require a collection of tools that can run and analyze massive numbers of simulations involving complex computation graphs, ideally with very low-latency response times.

A team at UC Berkeley’s RISE Lab recently released an open source distributed computation framework (Ray) that complements the other pieces needed for reinforcement learning. In complex applications—like self-driving cars—multiple sensors and measurements are involved, so being able explore and run simulations very quickly and in parallel provides a big advantage. Ray allows users to run simulations in parallel and comes with a Python API that makes it accessible for data scientists (Ray itself is written mainly in C++). While I’m writing about Ray in the context of RL, it’s more generally a fault-tolerant, distributed computation framework aimed at Python users. Its creators have made it simple for others to use Python to write and run their own algorithms on top of Ray, including regular machine learning models.
Why do you need a machine learning library and what algorithms are important for continuous learning? Recall that in RL one needs to learn how to map observations and measurements to a set of actions, while trying to maximize some long-term reward. Recent RL success stories mainly use gradient-based deep learning for this, but researchers have found that other optimization strategies such as evolution can be helpful. Unlike supervised learning where you start with training data and a target objective, in RL one only has sparse feedback, so techniques like neuroevolution become competitive with classic gradient descent. There are also other related algorithms that might become part of the standard collection of models used for continuous learning (e.g., counterfactual regret minimization used recently for poker). The creators of Ray are in the process of assembling a library that implements a common set of RL algorithms and makes them available via a simple Python API.
Most companies are still in the process of learning how to use and deploy standard (offline) machine learning, so perhaps discussing continuous learning is premature. An important reason to begin this discussion is that these techniques are going to be essential to bringing AI into your organization. As with any other new method or technology, the starting point is to identify uses cases where continuous learning potentially provides an advantage over existing offline approaches. I provided a few examples where RL has been deployed or where research has indicated promising results, but those examples might be far removed from your organization’s operations. The set of companies already using bandit algorithms (to recommend content or evaluate products) can probably quickly identify use cases and become early adopters. Technologies used to develop AI teaching agents might map to many other application domains that involve augmenting human workers (including software engineering).
Companies are realizing that in many settings machine learning models start degrading soon after they get deployed to production. The good news is that many AI startups are building continuous learning right into their products. Before you know it, your company might start using RL in the very near future.
Related resources:
- Ray: A distributed execution framework for emerging AI applications (2017 Strata Data keynote by Michael Jordan)
- Deep reinforcement learning for robotics (2016 Artificial Intelligence Conference presentation by Pieter Abbeel)
- Cars that coordinate with people (2017 Artificial Intelligence Conference keynote by Anca Dragan)
- Introduction to reinforcement learning and OpenAI Gym
- Neuroevolution: A different kind of deep learning
- Reinforcement learning explained