What is the Docker workflow?
From spinning up containers to shipping software as a team.
 Boxcars on tracks (source: Unsplash via Pixabay)
Boxcars on tracks (source: Unsplash via Pixabay)
In this chapter, we cover some of the ideas around deploying and testing containers in production. This chapter is intended to show you how you might take containers to production based on our experience doing so. There are a myriad of ways in which you will probably need to tailor this to your own application and environment. The purpose of this chapter is really to provide a starting point and to help you understand the Docker philosophy in practical terms.
Deploying
Deployment, which is often the most mine-ridden of the steps in getting to production, is made vastly simpler by the shipping container model. If you can imagine what it was once like to load goods into a ship to take across the ocean before shipping containers existed, you can get a sense of what most deployment systems look like. In that old shipping model, random-sized boxes, crates, barrels, and all manner of other packaging were all loaded by hand onto ships. They then had to be manually unloaded by someone who could tell which pieces needed to be unloaded first so that the whole pile wouldn’t collapse like a Jenga puzzle.

Learn faster. Dig deeper. See farther.
Shipping containers changed all that: we have a standardized box with well-known dimensions. These containers can be packed and unloaded in a logical order and whole groups of items arrive together when expected. This is the Docker deployment model. All Docker containers support the same external interface, and the tooling just drops them on the servers they are supposed to be on without any concern for what’s inside.
Now that we have a running build of our application, we don’t have to write much custom tooling to kick off deployment. If we only want to ship it to one server, the docker command-line tooling will handle most of that for us. If we want to send it to more, then we might look to some community tooling.
There is a progression you will follow while getting your applications to production on Docker:
-
Locally build and test a Docker image on your development box.
-
Build your official image for testing and deployment.
-
Deploy your Docker image to your server.
As your workflow evolves, you will eventually collapse all of those steps into a single fluid workflow:
-
Orchestrate the deployment of images and creation of containers on production servers.
We talked about some of those steps already, but it is worthwhile to look at them again to see where deployment fits into the life cycle of getting Docker up and running.
If you don’t already have an application to ship, you don’t need to spend too much time on deployment. But it’s good to know ahead of time what you’ll encounter when you do get there, so let’s look at how that is done.
Classes of Tooling
Deployment by hand is the simplest, but often the least reliable, way to get an application into production. You can just take your image and docker pull and docker run it on the servers in question. That may be good enough for testing and development. But for production, you will want something more robust.
At the most basic level, a deployment story must encompass two things:
-
It must be a repeatable process. Each time you invoke it, it needs to do the same thing.
-
It needs to handle container configuration for you. You must be able to define your application’s configuration in a particular environment and then guarantee that it will ship that configuration for each container on each deployment.
The Docker client itself can only talk to one server, so you need some kind of orchestration tool to support deployment at any scale. Docker’s Swarm tool, which we talk about in not available, solves the problem of talking to multiple servers, but you would still need additional tools to support items one and two above. You could script that behavior with shell scripting or your favorite dynamic language. As we mentioned earlier, you could also talk directly to the Docker Remote API, which is the API exposed by the docker daemon. If you have complicated needs, the Remote API might be the right solution since it exposes much of the power of the docker command line in a programmatically accessible way.
But for most people, there are already a large number of community contributions that can address your needs. These are already being used in production environments in many cases and thus are far more battle-hardened than anything you’ll cook up in-house. There are really two classes of community tooling for deployment:
Orchestration Tools
We’ll call the first set of tools “orchestration tools” because they allow you to coordinate the configuration and deployment of your application onto multiple Docker daemons in a more or less synchronous fashion. You tell them what to do, then they do it at scale while you wait, much like the deployment model of Capistrano, for example. These tools generally provide the simplest way to get into production with Docker.
In this category are tools like:
This class of tools in many cases requires the least infrastructure or modification to your existing system. Setup time is pretty minimal and the standardized nature of the Docker interface means that a lot of functionality is already packed into the tooling. You can get important processes like zero-down-time deployment right out of the box.
The first two concentrate on orchestration of the application and Docker alone, while Ansible is also a system-configuration management platform and so can also configure and manage your servers if you wish. Centurion and Ansible require no external resources other than a docker-registry. Helios requires an Apache Zookeeper cluster.
Distributed Schedulers
The second set of tools looks at Docker as a way to turn your network into a single computer by using a distributed scheduler. The idea here is that you define some policies about how you want your application to run and you let the system figure out where to run it and how many instances of it to run. If something goes wrong on a server or with the application, you let the scheduler start it up again on resources that are healthy. This fits more into Solomon’s original vision for Docker: a way to run your application anywhere without worrying about how it gets there. Generally, zero downtime deployment in this model is done in the blue-green style where you launch the new generation of an application alongside the old generation, and then slowly filter new work to the new generation.
Probably the first publicly available tool in this arena is Fleet from CoreOS, which works with systemd on the hosts to act as a distributed init system. It is by far the easiest to use on CoreOS, CentOS/RHEL 7, or any version of Linux with systemd. It requires etcd for coordination, and also needs SSH access to all of your Docker servers.
The tool in this category with the most press right now is Google’s Kubernetes. It makes fewer assumptions about your OS distribution than Fleet and therefore runs on more OS and provider options. It does, however, require that your hosts be set up in a very specific way and has a whole network layer of its own. If your data center happens to have its networks laid out like Google’s, you can skip the network overlay. If not, you must run Flannel, an IP-over-UDP layer that sits on top of your real network. Like Fleet, it requires etcd. It supports a number of backends, everything from the Docker daemon, to Google Compute Engine, Rackspace, and Azure. It’s a powerful system with a good API and growing community support.
Apache Mesos, which was originally written at the University of California, Berkeley, and most publicly adopted by Twitter and Airbnb, is the most mature option. At DockerCon EU in December 2014, Solomon described Mesos as the gold standard for clustered containers. Mesos is a framework abstraction that lets you run multiple frameworks on the same cluster of hosts. You can, for example, run Docker applications and Hadoop jobs on the same compute cluster. Mesos uses Zookeeper and has been around for much longer than most of the other options because it actually predates Docker. First-class support for Docker appeared in recent versions of Mesos. Some of the popular Mesos frameworks like Marathon and Aurora have good support for Docker. It’s arguably the most powerful Docker platform right now, but requires more decisions to implement than Kubernetes. Work is in progress to allow Kubernetes to run as a Mesos framework as well.
A deep dive into Mesos is out of the scope of this book. But when you are ready for serious at-scale deployment, this is where you should look. It’s an impressive and very mature technology that has been used at scale by a number of high-profile organizations. Mesosphere’s Marathon framework and the Apache Aurora project are two frameworks actively engaging with the Docker community.
In December 2014, Docker, Inc., announced the beta release of a Docker native clustering tool called Swarm, which presents a large collection of Docker hosts as a single resource pool. It’s a lightweight clustering tool with a narrower scope than Kubernetes or Mesos. It can, in fact, work on top of other tools as needed. But it’s reasonably powerful: a single Docker Swarm container can be used to create and coordinate the deployments of containers across a large Docker cluster. We will take a deeper dive into this tool in not available.
Tip
If you are interested in diving deeper into orchestration and distributed schedulers for Docker, consider reading the Docker Cookbook by Sébastien Goasguen.
Deployment Wrap-Up
Many people will start by using simple Docker orchestration tools. However, as the number of containers and frequency with which you deploy containers grow, the appeal of distributed schedulers will quickly become apparent. Tools like Mesos allow you to abstract individual servers and whole data centers into large pools of resources in which to run container-based tasks.
There are undoubtedly many other worthy projects out there in the deployment space. But these are the most commonly cited and have the most publicly available information at the time of this writing. It’s a fast-evolving space, so it’s worth taking a look around to see what new tools are being shipped.
In any case, you should start by getting a Docker infrastructure up and running and then look at outside tooling. Docker’s built-in tooling might be enough for you. We suggest using the lightest weight tool for the job, but having flexibility is a great place to be, and Docker is increasingly supported by more and more powerful tooling.
Testing Containers
One of the key promises of Docker is the ability to test your application and all of its dependencies in exactly the operating environment it would have in production. It can’t guarantee that you have properly tested external dependencies like databases, nor does it provide any magical test framework, but it can make sure that your libraries and other code dependencies are all tested together. Changing underlying dependencies is a critical place where things go wrong, even for organizations with strong testing discipline. With Docker, you can build your image, run it in on your development box, and then test the exact same image with the same application version and dependencies before shipping it to production servers.
Testing your Dockerized application is not really much more complicated than testing your application itself, but you need to make sure that your test environment has a Docker server you can run things on and that your application will allow you to use environment variables or command-line arguments to switch on the correct testing behavior. Here’s one example of how you might do this.
Quick Overview
Let’s draw up an example production environment for a fictional company. We’ll try to describe something that is similar to the environment at a lot of companies, with Docker thrown into the mix for illustration purposes.
Our fictional company’s environment has a pool of production servers that run Docker daemons, and an assortment of applications deployed there. There is a build server and test worker boxes that are tied to the test server. We’ll ignore deployment for now and talk about it once we have our fictional application tested and ready to ship.
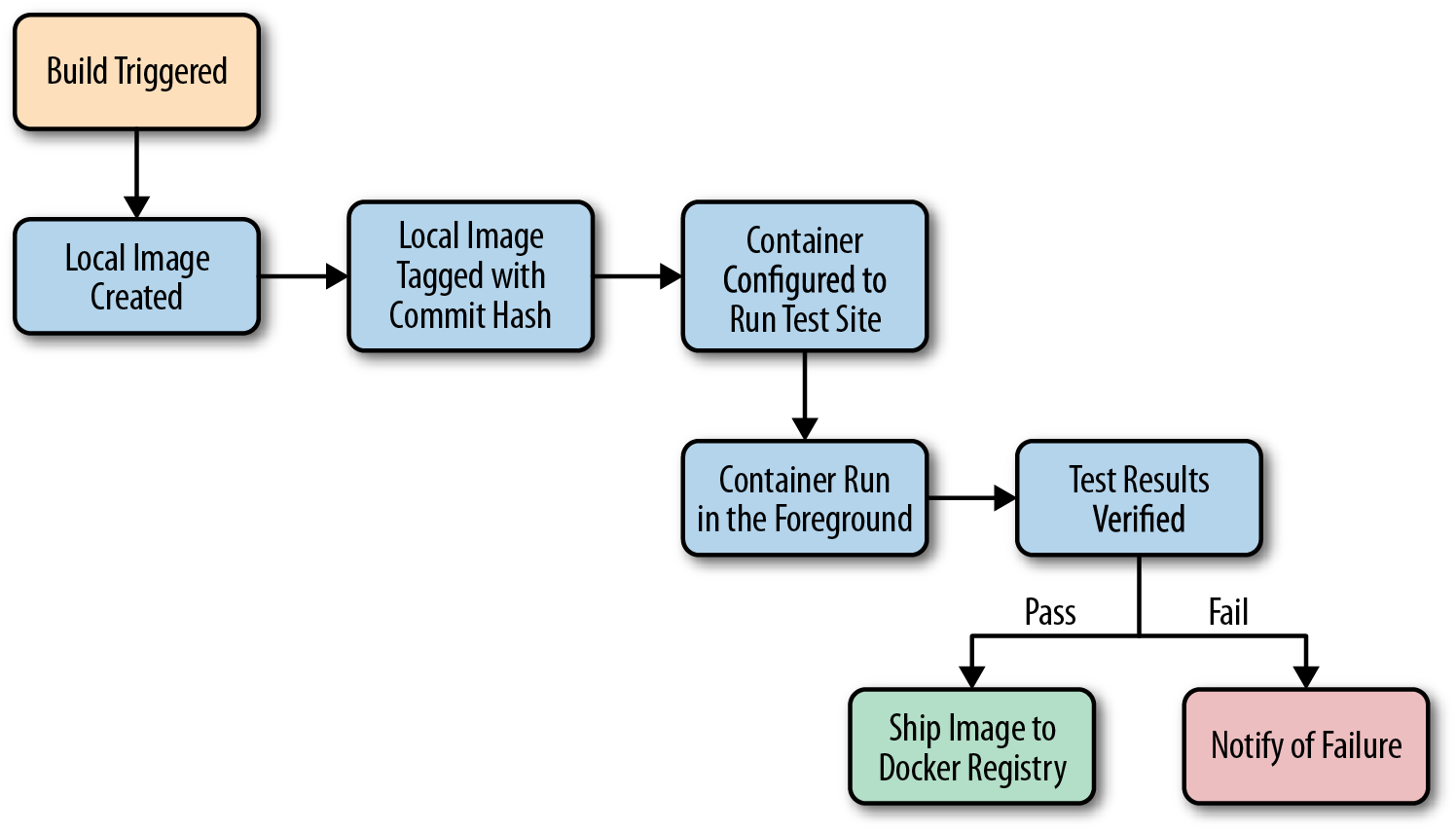
Figure 1-1 shows what a common workflow looks like for testing Dockerized applications, including the following steps:
-
A build is triggered by some outside means.
-
The build server kicks off a Docker build.
-
The image is created on the local
docker. -
The image is tagged with a build number or commit hash.
-
A container is configured to run the test suite based on the newly built image.
-
The test suite is run against the container and the result is captured by the build server.
-
The build is marked as passing or failing.
-
Passed builds are shipped to an image store (registry, etc.).
You’ll notice that this isn’t too different from common patterns for testing applications. At a minimum you need to have a job that can kick off a test suite. The steps we’re adding here are just to create a Docker image first and invoke the test suite inside the container rather than on the raw system itself.
Let’s look at how this works for the application we’re deploying at our fictional company. We just updated our application and pushed the latest code to our git repository. We have a post-commit hook that triggers a build on each commit, so that job is kicked off on the build server. The job on the test server is set up to talk to a docker on a particular test worker server. Our test server doesn’t have docker running, but it has the docker command-line tool installed. So we run our docker build against that remote Docker server and it runs our Dockerfile, generating a new image on the remote Docker server. We could run docker on the test server itself if we had a smaller environment.
Note
You should build your container image exactly as you’ll ship it to production. If you need to make concessions for testing, they should be externally provided switches, either via environment variables or through command-line arguments. The whole idea is to test the exact build that you’ll ship, so this is a critical point.
Once the image has been built, our test job will create and run a new container based on our new production image. Our image is configured to run the application in production, but we need to run a different command for testing. That’s OK! Docker lets us do that simply by providing the command at the end of the docker run command. In production, we’d start supervisor and it would start up an nginx instance and some Ruby unicorn web server instances behind that. But for testing, we don’t need that nginx and we don’t need to run our web application. Instead, our build job invokes the container like this:
$ docker run -e ENVIRONMENT=testing -e API_KEY=12345 \ -i -t awesome_app:version1 /opt/awesome_app/test.sh
We called docker run, but we did a couple of extra things here, too. We passed a couple of environment variables into the container: ENVIRONMENT and API_KEY. These can either be new or overrides for the ones Docker already exports for us. We also asked for a particular tag; in this case, version1. That will make sure we build on top of the correct image even if another build is running simultaneously. Then we override the command that our container was configured to start in the Dockerfile’s CMD line. Instead, we call our test script, /opt/awesome_app/test.sh.
Note
Always pass the exact Docker tag for your image into the test job. If you always use latest, then you won’t be able to guarantee that another job has not moved that tag just after your build was kicked off. If you use the exact tag, you can be sure you’re testing the right version of the application.
A critical point to make here is that docker run will not exit with the exit status of the command that was invoked in the container. That means we can’t just look at the exit status to see if our tests were successful. One way to handle this is to capture all of the output of the test run into a file and then look at the last line of the file to see if it resulted in success. Our fictional build system does just that. We write out the output from the test suite and our test.sh echoes either “Result: SUCCESS!” or “Result: FAILURE!” on the last line to signify if our tests passed.
Note
Be sure to look for some output string that won’t appear by happenstance in your normal test suite output. If we need to look for “success,” for example, we had best limit it to looking at the last line of the file, and maybe also anchored to the beginning of the line.
In this case, we look at just the last line of the file and find our success string, so we mark the build as passed. There is one more Docker-specific step. We want to take our passed build and push that image to our registry. The registry is the interchange point between builds and deployments. It also allows us to share the image with other builds that might be stacked on top of it. But for now, let’s just think of it as the place where we put and tag successful builds. Our build script will now do a docker tag to give the image the right build tag(s), including latest, and then a docker push to push the build to the registry.
That’s it! As you can see, there is not much to this compared with testing a normal application. We take advantage of the client/server model of Docker to invoke the test on a different server from the test master server, and we have to wrap up our test output in a shell script to generate our output status. But other than that, it’s a lot like a common build system anywhere.
But, critically, our fictional company’s system makes sure they only ship applications whose test suite has passed on the same Linux distribution, with the same libraries and the same exact build settings. That doesn’t guarantee success, but it gets them a lot closer to that guarantee than the dependency roulette often experienced by production deployment systems.
Note
If you use Jenkins for continuous integration or are looking for a good way to test scaling Docker, there are many plug-ins for Docker, Mesos, and Kubernetes that are worth investigating.
Outside Dependencies
But what about those external dependencies we glossed over? Things like the database, or Memcache or Redis instances that we need to run our tests against our container? If our fictional company’s application needs a database to run, or a Memcache or Redis instance, we need to solve that external dependency to have a clean test environment. It would be nice to use the container model to support that dependency. With some work, you can do this with tools like Docker Compose. Our build job could express some dependencies between containers, and then Compose will use Docker’s link mechanism to connect them together. Linking is a mechanism where Docker exposes environment variables into a container to let you connect containers when you have more than one deployed to the same host. It can also add information to the /etc/hosts file inside the container, enabling visibility between them.
Because Docker’s link mechanism is limited to working on a single host, Compose is best for things like development and testing rather than production. But it has an expressive config syntax that’s easy to understand and is great for this kind of testing. If you are interested in linking, Compose is your best option.
Even though containers are normally designed to be disposable, you may still find that standard testing is not always sufficient to avoid all problems and that you will want some tools for debuging running containers. In the next chapter, we will discuss some of the techniques that you can use to get information from your containers that will help diagnose problems that might crop up in production.