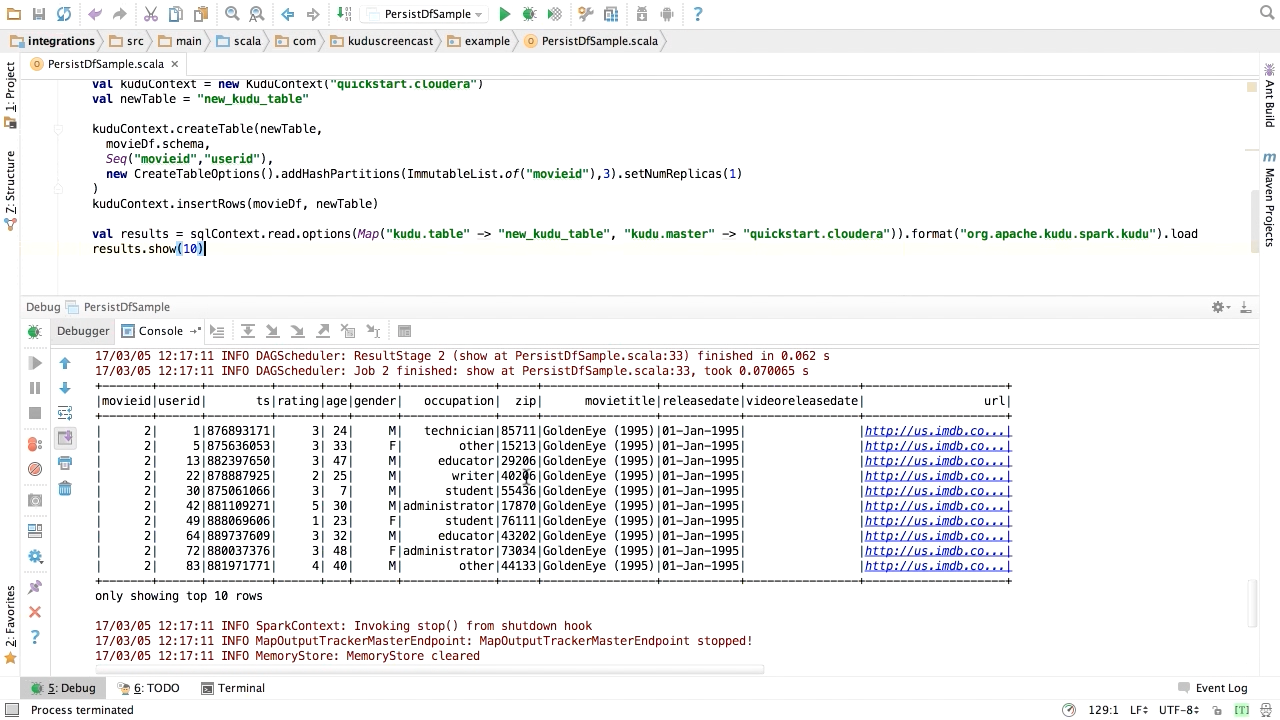
 Screen from "How can I bulk-load data from HDFS to Kudu using Apache Spark?" (source: O'Reilly)
Screen from "How can I bulk-load data from HDFS to Kudu using Apache Spark?" (source: O'Reilly) Apache Spark dominates the big data landscape with its ability to process data on a large scale and handle machine learning workloads. In this video Ryan Bosshart explains how to pair Spark with the Hadoop storage layer for easy, scalable data storage. All you need to follow along is IntelliJ IDEA and access to Kudu Quickstart VM. Data architects and developers will be able to:
- Use the Kudu-Spark module to move data between HDFS and Kudu.
- Create a new Kudu table from a Spark SQL DataFrame.
- Create data processing pipelines that transform data from a raw to processed, queryable format.
Continue learning Kudu with our Using Kudu with Apache Spark and Apache Flume course.
Ryan Bosshart is a Principal Systems Engineer at Cloudera, where he leads a specialized team focused on Hadoop ecosystem storage technologies such as HDFS, Hbase, and Kudu. An architect and builder of large-scale distributed systems since 2006, Ryan is co-chair of the Twin Cities Spark and Hadoop User Group. He speaks about Hadoop technologies at conferences throughout North America and holds a degree in computer science from Augsburg College.