 Brick tower (source: klimkin via Pixabay)
Brick tower (source: klimkin via Pixabay) Overview
Privacy and the potential violations thereof are intrinsic to our everyday notions of trust. When customers and citizens entrust private companies, NGOs, and government agencies with sensitive data, they would like to be assured that those organizations can and will handle it responsibly. In turn, organizations that serve as stewards of sensitive data must trust in their own people accordingly, often in new and uncharted ways. But sometimes people are untrustworthy—occasionally because of malicious intent, but more often because of honest mistakes and accidental errors. It’s therefore imperative to become familiar with various ways to design technical methods that minimize the risk of having a class of users who must be trusted—of their own volition—to behave within a set of rules in order to safeguard privacy. A thorough security architecture will help you avoid creating a single point of trust in your systems.
Separating Roles, Separating Powers
Privacy controls serve to limit the behavior of users inside the system. However, to protect data from access occurring beyond the confines of the privacy-protected application (but rather at some lower system level), it’s important to strictly separate the roles of individuals interacting with the system.1 It’s then possible to establish a clear separation of powers between these different roles.
Generally, an effective privacy-protection regime should account for the following five roles:
The end user, who uses the software, either outside or within the data-stewarding organization
The application administrator, responsible for the user-facing software’s system maintenance—including data and users
The system administrator, responsible for the operating system (e.g., Linux, Windows) and other components on which the application depends
The hardware or cloud administrator, responsible for the upkeep and maintenance of the physical and/or virtual machines on which the software runs
The network administrator, responsible for the secure operations of the organization’s data-transfer systems
To properly separate roles, a few guidelines are necessary:
Access controls must be used to refine what areas of the system users at each level can affect—both up and down the stack. For example, an end user should not be able to log in to one of the servers as a system-level user, and a system administrator must not be able to read application data. This method operates in contrast to the most common security architecture, in which each escalating level expands on the privileges of the level below. Rather, we recommend that each role should have its own disjoint set of allowed access.
Each role’s access to its own area must be through a technical intermediary that tracks user actions. In practice, this means that system administrators, for instance, would not be able to have raw shell access to machines and would instead use a management framework like Puppet or Chef to create auditable changes to the machines.
The systems that hold the logs recording the actions taken by users in each role must not be under that role’s control.
This approach effectively solves the “who watches the watchers” conundrum by creating overlapping areas of concern and oversight at each layer boundary.
A typical set of checks that can result from a separation of roles might look like the following: the end user can be checked by the application administrator, the application administrator can be checked by the system administrator, and the system administrator and hardware administrator are unable to view data. The application administrator would be the only administrator who can view data inside the system, giving them a degree of control not shared by the other two administrators. In turn, an insider threat or information assurance team would be responsible for policing all of these roles without having direct access to the hardware, systems, application, or data. Each monitor would receive appropriate alerts when the action of a user in another role trips a threshold that indicates potential abuse.
Separating roles, conveniently, also functionally maps to a system architecture with access control points that log audit trails on every user action. At these crucial monitoring points, it’s possible to automate many system tasks (thereby avoiding the risk of human error or malice), apply server-side access controls to data, and reserve direct system access for genuine emergencies.2 Limiting direct root access is an important step to reducing risk, because it is often very difficult to audit such access, and root access can enable the gravest system vulnerabilities.
However, even in this most risk-laden of roles, it is sometimes still possible to detect behavior that indicates a malicious user trying to hide evidence of tampering. These techniques can be applied to those who administer and maintain system components, be they application, system, or hardware administrators. The practice of logging system events, discussed more thoroughly in not available, can extend to keeping a machine-readable history and lineage of all changes made to every piece of data over time. This allows your team to track how data is used, enabling you to properly specify known patterns or train algorithms for detecting abuse. Keeping tamper-resistant or tamper-evident trails of audit logs on every user action also can contribute to analysis, and help detect and deter privacy violations or other malicious or unintentionally damaging acts.
By keeping data on the server side, organizations can establish and enforce sound technical protections for privacy while still making data available through client applications that read and analyze (but do not allow bulk export of) data held on the servers. It’s standard practice to limit data access to different users based on what they need in order to do their work and refrain from giving them direct or complete access to database servers.
Once data has been copied from a server to a local hard disk, the risk of undetected abuse increases because the stored information is now only controlled by policy and trust, not technical safeguards. It’s therefore usually wise to prohibit users from downloading and saving data to their local machines. When data does need to be shared, it should be done from server to server. This assists in tagging changes and tracking source information, which in turn informs audit trails.
Making Roles Secure
Since each role should have different powers, it follows that each requires different methods to be made secure. Various controls can be applied in conjunction with regular oversight of alerts and subsequent investigation by your anti-abuse team.
The End User
To secure the end-user role, it is important to apply controls at the application level that lie outside the user’s control. Beyond straight access controls, an organization might also set additional controls that govern the use of the system, such as those that include rate-limiting actions, setting limits on bulk downloads, or restricting export permissions. Such controls can prevent a user from, say, downloading 10,000 documents in 10 seconds. At the very least, if a user were to download 10,000 documents in 10 seconds, controls could trigger an alert to an insider threat team.
Figure 1-1 illustrates a simplified view of a system architecture for privacy-protected operations. End users access the data they need in the database and filesystem. Their access is mediated by the firewall-protected application server, which enforces the access controls on the underlying data and creates audit trails for each user operation. This audit data is sent to a second application server and data store that is used by the various audit and oversight teams to review the users’ actions.
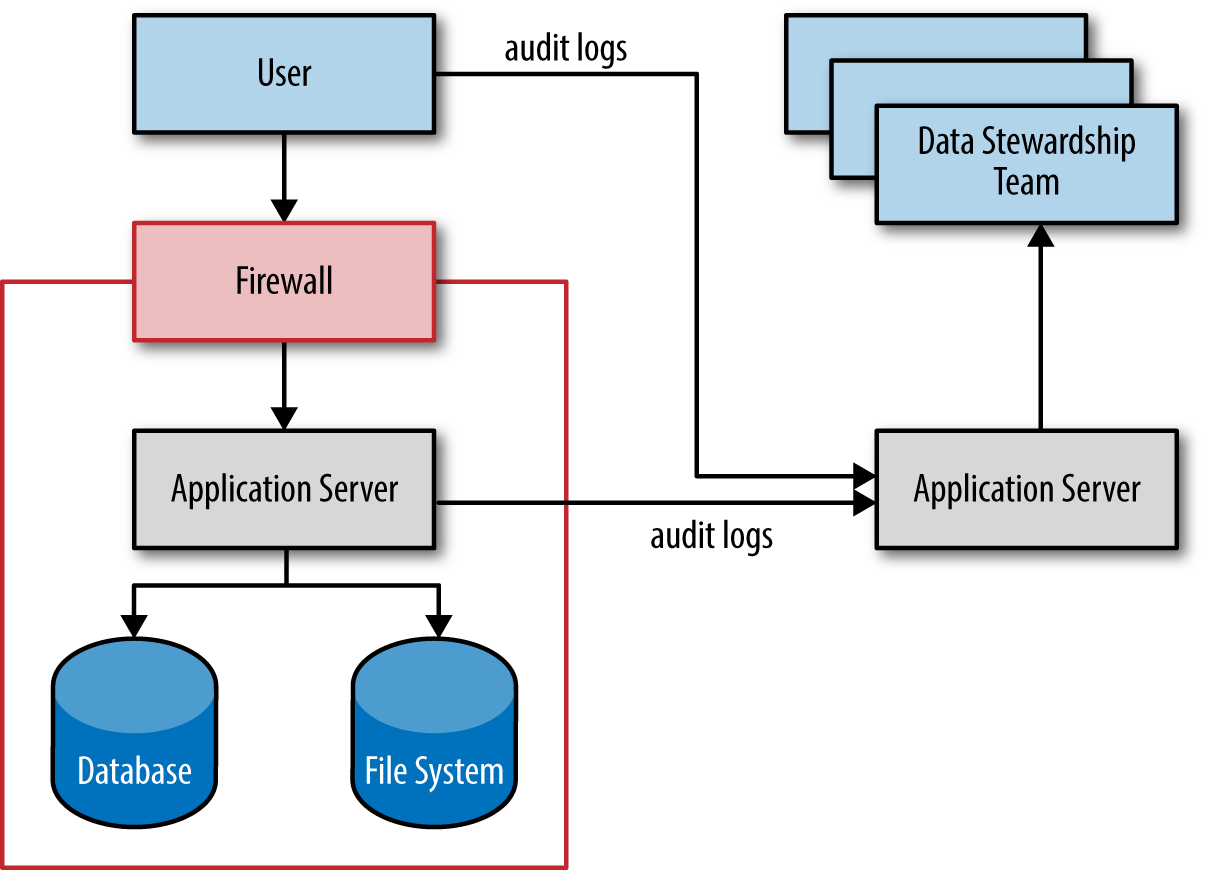
While it may seem obvious, it’s important to stress that all access controls must be applied on the server side. Sending data to the client, and trusting that code running there will adequately enforce policies surrounding which data can be seen, presents far more opportunities for security breaches. Only send to the client data that the user has access to.
Similarly, a system outside the end user’s control must be used to record activity logs for later auditing. An anti-abuse team would then be responsible for actively reviewing those logs. With audit logs, application-level controls, and active oversight securing the end user’s behavior, it becomes possible to significantly reduce the risk of bulk access or unauthorized disclosure. Additional controls can also be set and enforced on the user’s computer. For more on audit logging, see not available.
The Application Administrator
It’s important to monitor the application administrator, who has significant power because he or she needs to understand what data is in the system. Traditionally, this role is given login access to view all data inside the system. The application administrator may also frequently be given system tools access to address problems, filesystem access to transfer data, and database access to debug software and other system and data-integrity issues. In addition, they might have access to audit-log data. Consequently, a rogue administrator could theoretically turn off application server audit logs, log in as an end user, and then exfiltrate data. She could also deploy malicious code if the architecture allows plugins and extensions to be added to the system.3
To protect against these risks, organizations can use a standard technique to deny the administrator direct access to servers. Connections instead must pass through a host maintained by a third party, commonly called a jumphost. While connections to and from the jumphost are encrypted, the jumphost itself can peer into the commands as they traverse the system, creating a single point of monitoring to record all application administrator behavior that might take place outside of the audit logs recorded by the application itself. An insider threat team—perhaps part of the overall information security organization or a dedicated audit team specifically for this system—would then be responsible for actively reviewing those audit logs.
Figure 1-2 illustrates the use of a jumphost to monitor the actions of an application administrator. The jumphost produces audit data that is sent over to the systems used by the insider threat team.
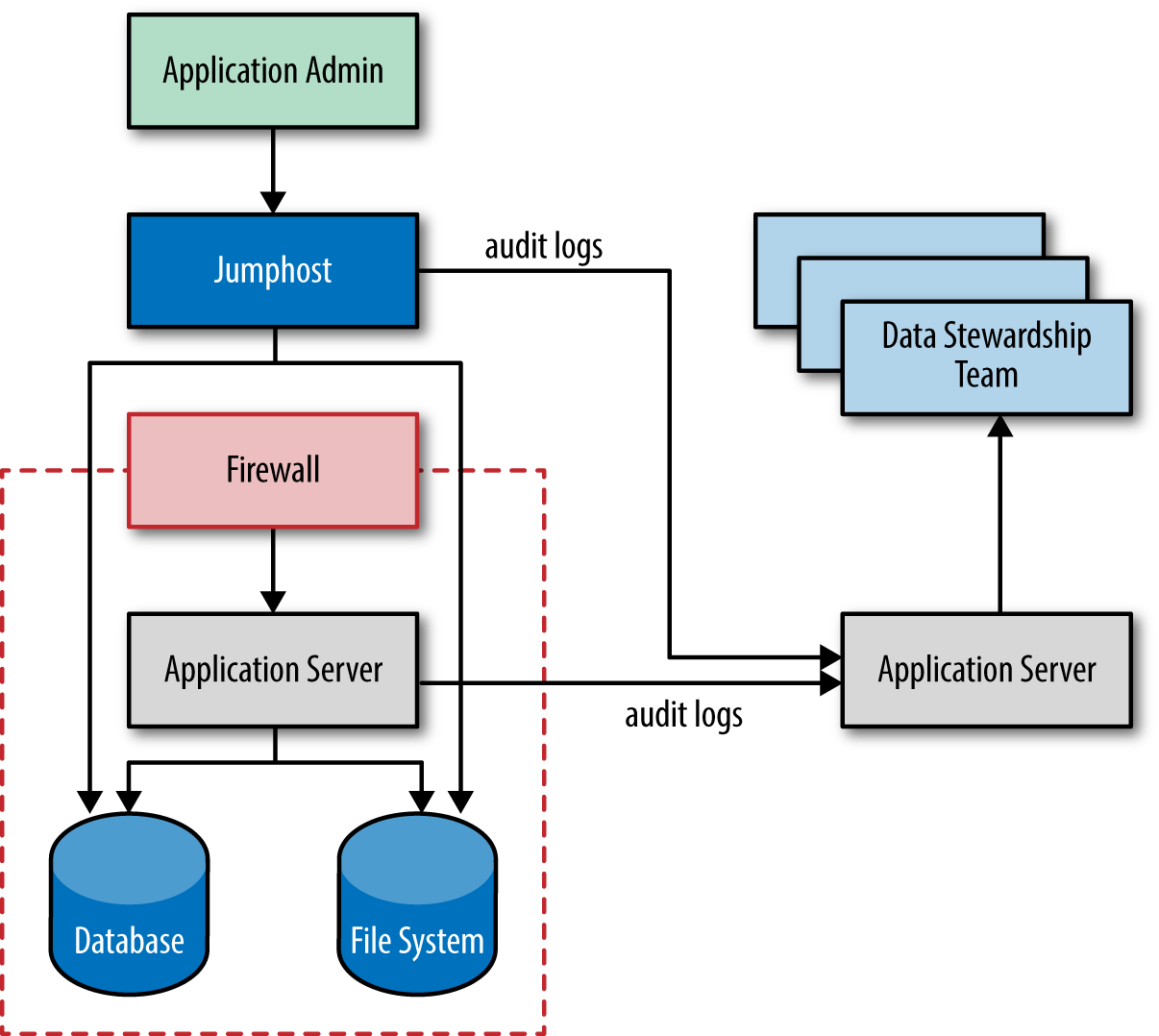
This process can even be made transparent to the application administrator through careful configuration of the jumphost. By preventing the administrator from altering or deleting the audit log of his or her actions, organizations can review the administrator’s actions without requiring synchronized two-person review, a policy that is sometimes cumbersome to implement but often the only option for monitoring the behavior of someone who has root access to the system, as application administrators frequently do.
Since audit logs can be made machine-readable, organizations can also apply rules to detect suspicious behavior patterns and take action in real time, as discussed in not available. Organizations can also review the audit logs to identify potential areas of risk based on the administrator’s past actions. The insider threat team would be responsible for conducting this type of continuous monitoring and analysis.
Protecting against malicious code deployment is more difficult. Organizations may consider requiring reviews of all code written by insiders in order to prevent the application administrator from deploying malicious code. If implemented, the code review process should be conducted in small batches to improve the quality of review. In a secure code deployment pipeline, the application administrator should check the source code into a repository that is then reviewed by a second developer. The code should then be compiled and signed by an automated build system outside of the developer’s control. The system administrator should then enforce a check at the application-server level that only permits signed binaries to be deployed. This step prevents the application administrator from deploying code outside the review process.4
The System Administrator
It’s common practice for system administrators to have root or “superuser” access to the operating system—allowing them to alter any part of the system in ways that are difficult to detect. This presents risks because the system administrator can turn off or cripple functions in undetectable ways, and enforcing controls at the system level against any superuser is clearly ineffective. Instead, the most effective way to audit system administrator behavior is proxy-shell access through jumphosts, as discussed above. Using a jumphost will record all the behavior of the system administrator as a series of issued shell commands.
However, while auditing the shell commands issued by the superuser is theoretically effective, it presents some challenges. First, given the free-form nature of command-line administration, it requires someone with system administrator-level knowledge to decode what the commands mean. Second, even when the commands themselves are clear, decoding what the effect of any given shell command is can sometimes be very difficult to do—even for another system administrator—without painstakingly reconstructing the state of the system at the time the shell command was run. Finally, given that command shells are effectively programming languages, it is easy to carefully obfuscate the true meaning of a sequence of commands, effectively making automation useless in detecting malicious behavior.
Because of all this, in a production system with sensitive data, superuser access to a live production server should be reserved for emergencies. The easiest way to do this is by implementing automated system configuration management, which requires system edits in more or less the same way that source code is controlled. To be deployed against a server containing sensitive data, commands should be written into a script, reviewed by another administrator, and automatically deployed once approved.
These technical and procedural steps, illustrated in Figure 1-3, prevent any single administrator from inserting commands directly into a production system as the superuser. These techniques for command scripting and review have become standard engineering practice for companies practicing cloud deployment. In some cases, emergency access may be necessary, but these contingencies are rare, discrete, and easily monitored. In other words, manual access should only be granted in highly-controlled special cases and not during normal business operations.
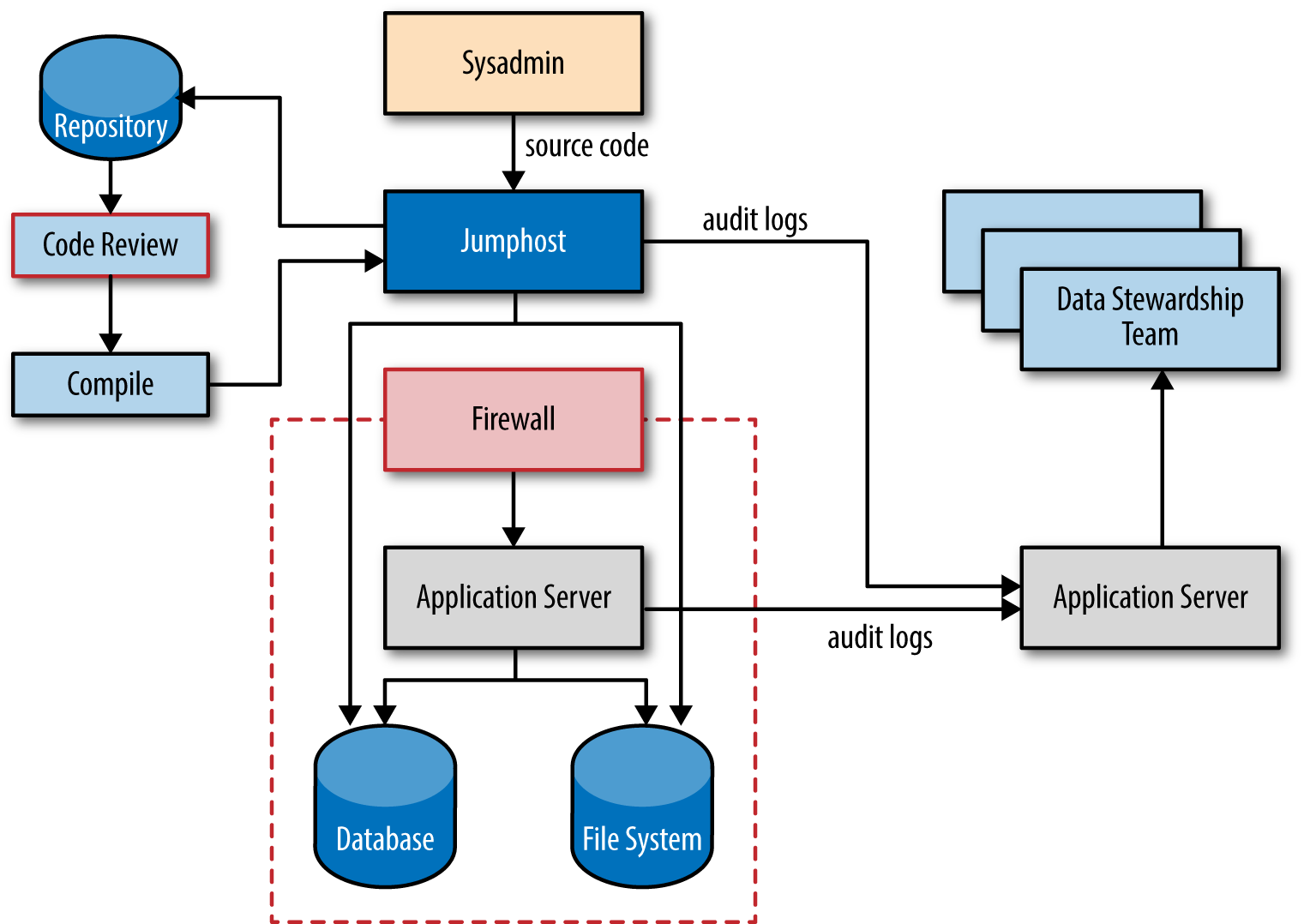
In addition, data should be encrypted at rest, and the keys should be held by the application administrator. If data is encrypted at the application level, then the system administrator should have no access without superuser permissions. And even when encryption is performed at the system level, the system administrator should still not have access to the encryption keys required to start up the protected machines.
This brings us to secure key management. When encrypting data at rest, the encryption keys can either be stored on internal systems or be held externally using a hardware security module (HSM), a tamper-evident and tamper-resistant external device that securely generates and holds encryption keys. Modern server-based information-processing systems (including increasingly popular cloud-based offerings) tend to hold many encryption keys, which in turn are often secured and managed by a single master key. However, you’ll want a secure way of managing all of your keys, because whether you store them on external hardware accessories or on internal systems, a compromised encryption key means substantially increased risks to privacy concerns around sensitive data that is no longer reliably secured.
The following is a generic example of a secure key management system, which is entirely automated and requires no manual entry or transfer of encryption keys.
A master key management system generates, encrypts, stores, and backs up a master key in conjunction with an HSM. The master key manager service communicates with client key management systems that assist in running other independent software on various servers. The client key managers obtain key material from the master key manager. In addition, the client key managers regularly report their status to the master key manager. The master key manager in turn monitors their behavior for anything irregular or suspicious. The master key manager tracks various timeout periods on the master keys as well as on the client key managers and their subcomponents. If a client key manager exceeds the time limit for reporting in as scheduled, or begins communication unexpectedly early, the master key manager will stop trusting it and will not provide it with keys. When a client key manager needs an encryption key (e.g., to mount an encrypted volume or access encrypted data), it asks the master key manager. After the master key manager verifies that the client key manager isn’t raising any security flags, it sends the encrypted key to the HSM, which then decrypts the key and sends it back. It is only at this point that the master key manager provides the appropriate unencrypted key to the client key manager.
This type of a key management setup would provide an additional check on internal and external threats such as rogue system administrators or cloud administrators: if you decide you want to sever your relationship with them, the HSM and master key manager give you the option of destroying the master key and shutting down all the connected client key managers, thus rendering all the data you entrusted to that third party inaccessible.
The Hardware or Cloud Administrator
The hardware administrator has physical access to the machines. This role presents risks because hardware administrators can copy and steal hard drives or insert malicious hardware, either of which could result in compromised data. Organizations can limit this risk by employing encryption of data at rest, as described above and in not available, and taking physical security steps. For instance, at most commercial data centers or cloud-computing services, hardware devices are separated and locked in physical cages. There are many other steps, such as using sensors, locking hardware, and auditing, that can further secure this process.
However, the most important step in enforcing adequate physical security is to maintain the proper separation of roles. In a large data center, a hardware administrator should be unaware of the details of the systems he or she is administering. Not knowing which is which, the hardware administrator should instead respond to requests at the level of the server rack and the machine. Sometimes, the hardware administrator role is not carefully separated from others, and some data centers do not control access other than at the border of the facility. Such an approach disproportionately relies on trust rather than technology and verification, and is not recommended. Instead, care should be taken in selecting data centers that are conscientious about the subtleties of protecting their customers’ sensitive data.
The Network Administrator
Another role, overlapping in some cases with some of the responsibilities of the system administrator or the hardware administrator, is the person who administers an organization’s networks. The network administrator operates at one layer of architectural abstraction away from individual systems where data is held and processed; it’s a role that serves as the gateway to the machines but doesn’t actually touch the content of those machines. The network administrator is responsible for authorizing and maintaining LAN, WAN, and VPN access; monitoring incoming and outgoing traffic across networks and between machines on the organization’s intranet; assigning and managing IP addresses; administering firewalls and whitelists; testing for network security weaknesses; and keeping security tracking regimes up-to-date.
In short, the network administrator is involved in managing internal and external risks, focusing primarily on the latter. The network administrator ensures that the initial lines of defense are in place to prevent undesired network traffic and closes gateways through which an attacker could assault the organization’s machines.
To that end, network administrators also capture and analyze (“sniff”) network traffic to determine if malicious actors are monitoring communications over the network. Because of this, we recommend that internal traffic between machines be encrypted to mitigate the risks posed by external snooping and rogue network administrators. To further minimize the risks a network administrator might pose, an organization should allow only encrypted access to its sensitive applications and those applications’ internal communications. Network administrators should also not be granted the power to generate new SSL certificates, which they could use to spoof connections. These steps will substantially reduce their threat profile.
In much the same way that encryption-at-rest limits the damage that someone with access to the hardware can do, encryption-in-flight limits the damage that someone who owns the network can inflict. A network administrator could still execute denial-of-service (DOS) attacks, but these do not represent a privacy risk on a technical level. As part of our recommended loop-of-oversight, an organization’s network information security team (the ultimate monitors) should watch the network administrators, examining system monitoring data and not any raw content.
Conclusion
Separating powers and roles is a traditional mechanism to implement the well-known principle of checks and balances. Different factions in different roles enforce controls against each other such that no faction or single individual can engage in abuse without detection. When properly executed in information-processing systems, such an approach can provide substantial structural improvements to safeguarding privacy. Such a separation of roles inherently creates a framework of oversight, one predicated on carefully controlled access to systems and data.
1This approach is sometimes also referred to as separation of duties.
2Access controls can be applied either at the level of enterprise servers or on individual users’ client machines. Holding and applying access control policies on the server side makes it much more challenging for a user to compromise them. Users will be able to view relevant data held on the server, but they will not make or hold a local copy of the data on their own client machine. In contrast, if access controls are applied on the user’s machine directly, the user will have a copy of the data and will be able to transfer that data elsewhere, either by uploading it to an external server or by copying it to external media that can be taken beyond your organization’s control.
3Whereas textual commands can be audited, at the time of writing, binaries cannot be audited in any practical way.
4See Jez Humble & David Farley, Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation (Addison-Wesley, 2010).