Most of the time, application failure happens because one or more stages fail eventually. As discussed earlier in this chapter, Spark jobs comprise several stages. Stages aren't executed independently: for instance, a processing stage can't take place before the relevant input-reading stage. So, suppose that stage 1 executes successfully but stage 2 fails to execute, the whole application fails eventually. This can be shown as follows:
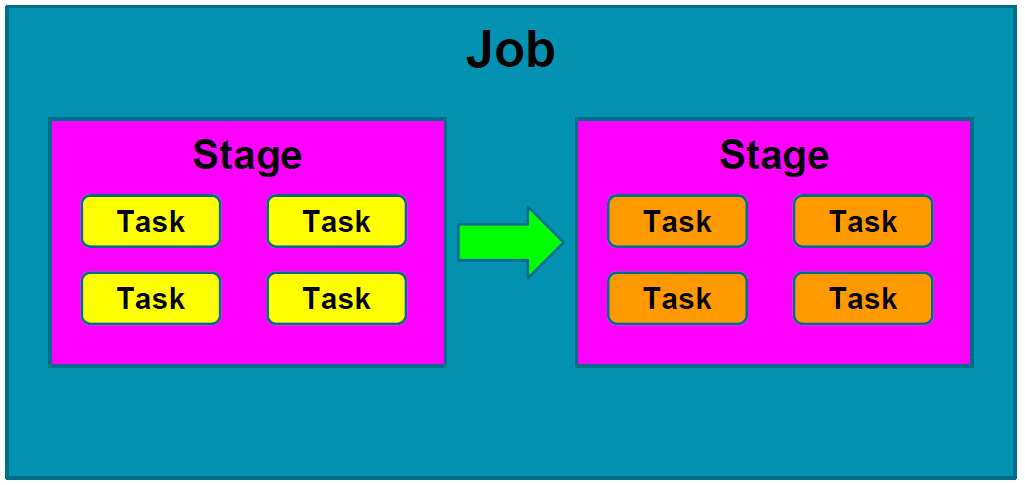
Figure 19: Two stages in a typical Spark job
To show an example, suppose you have the following three RDD operations as stages. The same can be visualized as shown in Figure 20, Figure 21 ...

