Observe how similar it is to train and make predictions on each model, despite them each being so different internally.
- Train a Random Forest classification model composed of 50 decision trees, each with a max depth of 5. Run the cell containing the following code:
from sklearn.ensemble import RandomForestClassifier forest = RandomForestClassifier(n_estimators=50, max_depth=5, random_state=1) forest.fit(X_train, y_train) check_model_fit(forest, X_test, y_test)

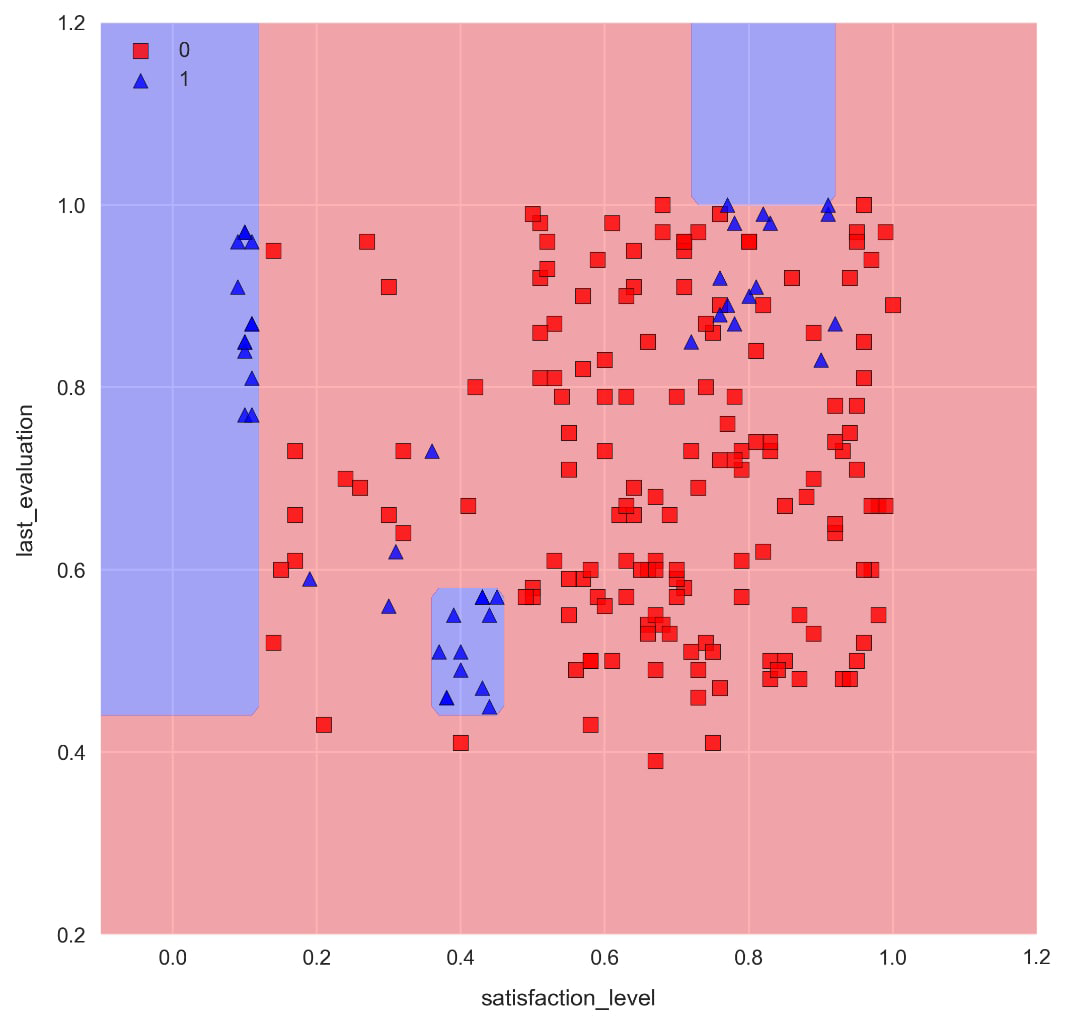
Note the distinctive axes-parallel decision boundaries ...

