Chapter 4. Strive for Transparency
In the Lord of the Rings trilogy, the fate of Frodo Baggins is tied to the ring of power. The ring provides incredible power, but at a terrible cost. In the end, it invades his sleep, every hour of consciousness, and even his relationships. He is so possessed by the ring that he cannot drop it, although it is consuming him. I’ve suffered projects where our frameworks felt a little too much like that ring. In the beginning, the power blinds us, and near the end, it invades the core of our being, from the design philosophies all the way to the thoughts and mood of the whole team. In fact, I’ve even helped to build, and sell, such a framework, a demon disguised by the false name of CORBA. I’m not alone. I’ve been approached to rescue many an application from a cloud of doom, whether it’s CORBA, VisualBasic, EJB, or even database stored procedures and user-defined functions.
In Chapter 3, our goal was to focus our software efforts on a central task. There weren’t any earth-shattering techniques. You probably already do some kind of layering, and at least understand the value of decoupling. In this chapter, you’ll see techniques to take the power of decoupling to the next level. In fact, it’s often important enough to decouple critical layers like your domain model from all other services from the very beginning. You’re looking for transparency, and this chapter introduces the techniques that you need to get there.
Benefits of Transparency
For most of this chapter, I’m going to explore the relationship between a service and a model. Your ultimate goal is to build a layer that’s completely independent from the services that it uses. In particular, you want to keep all peripheral systems out of the domain model—persistence, transactions, security—everything. Why should the business domain model get such special treatment?
Business models tend to change rapidly. Transparency lets you limit the changes to business logic.
With transparency, you can limit changes to other parts of the system when your model changes.
You can understand and maintain transparent models much more quickly than solutions with tighter coupling.
By separating concerns of your layers, you can focus business, persistence, and security experts in the areas that make them the most productive.
You can also build completely generic services that know nothing in advance about the structure of your model. For example, a persistence service can save any generic Java object; a security service needs no additional code, but is based on configuration instead; a façade gets the capability to make a series of steps transactional just by adding a POJO to a container; a serialization service can turn any object into XML without knowing its structure in advance.
The core techniques in this chapter—reflection, code injection and other code generators—pack a punch, but they also add complexity and weight to your applications. My hope is that with a little supporting theory on your side, you’ll be able to use these techniques to pry that ring out of your hand.
To be sure, none of these ideas are new, but I don’t believe that they’ve received the weight that they deserve in the Java mainstream. I’ll first talk about moving the control centers of the application to the appropriate place. Then, I’ll give an overview of the tools that limit transparency, and wrap up with a few recommended tools to achieve it: code generation, reflection, and byte code enhancement, with an emphasis on reflection. If you’re not used to coding this way, you’ll find that it’s going to warp your mind a little. Take heart. You’ve probably seen these techniques before, though you may need to rearrange the ideas a little. In the end, you’ll find the ideas that percolated in the center of Smalltalk and around Java’s perimeter have the power that you want, and even need.
Who’s in Control?
Close to the center of my universe are my two little girls. One Christmas, we splurged a little and traded in our out-of-date 19-inch TV for a much larger model. We set the new television up. A little later, I looked around the room: one of my daughters was staring with a blank, passive face at frantic Disney images on the TV. The other kid had the cardboard box. With her mother, she had carved out doors and a window, and was actively jumping and dancing around the passive box. The contrast was striking. On one side, I saw an active toy, and a passive kid; on the other side, a passive toy and an active kid. Since then, I’ve repeated the experiment, albeit more intentionally. I’ve filled my house with passive toys that let the kids actively build, imagine, create, or act (at least, when I can pry them away from the TV).
Active Domain Models
Modern programming is undergoing
a similar transition from active to
passive domain models. Figure 4-1 shows the
organization of classic services in a client-server application.
Designers put services on the bottom, so their clients could build
applications that use the
services directly. Essentially, active
business logic invoked services as needed. The passive services
presented an interface, and waited idle until invoked. Early
programmers found it easy to build applications with active business
layers. When they needed a transaction, they called a function like
BeginWork. When they needed data, they asked for
it directly from the database. Easy development gave way to complex
maintenance and foiled attempts at extension, because the
architecture muddied and entangled concerns between layers.
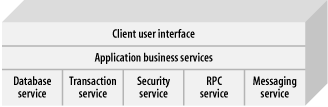
The problem at the core of this type of design is the commingling of business entities and business rules. The entities themselves, representing the central concepts of the problem domain, manage their own state and their interactions with other entities. This makes changing them more difficult, since structural changes will at the very least entail wading through the logic, and usually involve editing it as well.
When your model actively reaches into other areas of your application, passive services like persistence, logging, and security tend to cut across all aspects of an application. Said another way, a crosscutting concern applies to every aspect of an application. Object-oriented technologies do not handle crosscutting concerns very well.
The Power of Passive Models
You’ve seen that active models tend to couple much more tightly to individual services. Lately, new object-oriented architectures make an improvement over the all-controlling domain model. Figure 4-2 shows that the business domain model can relinquish control and act like other passive services. The business domain model, if anything, is just another service, albeit an important one. Usually, peer relationships exist between the model and services. You should strive to diminish them. Using this paradigm, controllers marshal data between the model and other services as needed. Controllers model the rules of the application, while the domain model represents the entities. Whole frameworks, like Struts or JDO, solve this problem for user-interface development or persistence.

Still, today’s developers rely too heavily on hard-wired peer interfaces directly between the business layers and individual services. The next natural step in development evolution is to build a model with generic services that have no advanced knowledge about the model at all. It’s a difficult problem that raises some complex questions:
How can a service support a business object without explicit knowledge of it? For example, how can you save an
Accountobject without knowing about the account in advance?How can you build a business model that uses services in a complex way, without prior knowledge of those services? For example, how can you make sure that the first four business rules execute in one transaction, while the next two occur in another?
How can services react to events in a business model?
These are issues are about establishing transparency. If you haven’t dealt with these issues before, it may sound like I am promoting anything but better, faster, and lighter Java. Stay with me, though. These techniques can help you dramatically simplify other areas of your architecture. They are worth the effort.
Alternatives to Transparency
Most people use the term transparent in a very specific sense, referring to code that does a job without explicitly revealing the details of that job. Distributed code with location transparency does not explicitly refer to the location of other machines on the network.
Consider a specific example. Persistence frameworks let you save Java objects. If you don’t have to build in any support to get those benefits, then you’ve got transparent persistence. You’d think that you’ve either got transparency or you don’t, but unfortunately, it’s not always black or white. You may need to make some minor compromises:
Your code may be transparent, but you may have to deal with minor restrictions. For example, some frameworks use JavaBeans API, and require getters and setters on each field (such as earlier versions of Hibernate).
You may have to deal with major restrictions. Some frameworks don’t support threading or inheritance, like EJB CMP.
You may need to add special comments to your code. XDoclet relieves some limitations in other frameworks through code generation, but forces you to maintain specific comments in your code.
You may have to make minor code changes, like supporting an interface or inheriting from a class.
Your framework may generate your code, but you may not be able to modify that code and still support regeneration, like many IDE wizards.
You may need to change the build process, such as in frameworks with code generation like Coco Base, or frameworks like JDO with byte code enhancement.
Some of these restrictions are minor, but some are severe. Before I dig into techniques that promote transparency, you should know about other available techniques, and their possible limitations.
Techniques That Compromise Transparency
In the area of persistence strategies, all frameworks must make serious compromises. The most successful tend to provide the best possible transparency within the business domain model, with respect to persistence. Some of the less-successful techniques invade your programming model in awkward ways.
Invading the model
You may suggest that transparency is not important at all, and you should just add code to the model itself. You could just hardwire create, read, update, and delete (CRUD) methods directly to the model. But keep in mind that persistence is not the only type of service that you’ll likely need to add. You’ll also have to consider security, transactions, and other enterprise services.
Many of my customers applied this approach before calling me to clean up the mess. The problem is that each class gets large and unwieldy, because code for each aspect invades each individual class. It’s tough to get a consolidated view of any one particular problem. Additionally, you end up with a quagmire of redundant code. If you suddenly change databases from SQL Server to Oracle, you might find yourself editing each and every class in your model.
Subclassing
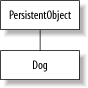
If you want to
build
something
that’s persistent, you could use a persistence
framework that forces you to inherit that capability—for
example, from a class called PersistentObject, as
in Figure 4-3. This creates a problem: since
classes can only support single inheritance, you are limited in your
choice of inheritance hierarchy. You also do not support true
transparency, because you need to make a conscious decision to
inherit from PersistentObject. The result works,
but it complicates your designs.
Building a hardwired service
You could keep the model
transparent, but build knowledge of
each class in your model into your service layer. This technique is a
brute-force approach. For example, you could build a data access
object called PersonDAO that knows how to store
and retrieve a Person object. That DAO would
return Person objects so you could deal with the
model transparently. That’s often a workable
solution. It’s probably the preferred solution for
simple problems, and for novice and intermediate developers.
It’s also the solution used in the Account example
in Chapter 3.
This approach does have real benefits. It’s easy to understand and easy to implement for smaller solutions. It leaves you with a transparent object model. The specific service approach does require you to do more work to implement each service. You can imagine how easy that it would be to load a simple object like a person, but loading a complex object with many parts, like a car, would be much more difficult. With a specific service, you have to manage complexities like this yourself. In this case, you need to add that persistence code to each class in your model, and hardwire each relationship by hand. As your requirements get more complex (such as adding caching or an ID generator to your persistence layer), you’ll want to think of a more general solution to insulate you from these types of tedious details.
Code metadata
One strategy for persisting a model is to add metadata to pieces of the model that need special treatment, and then generate the code for persistence. For example, you may need to mark persistent classes, and mark each persistent field with a comment. If you’re looking at this technique purely as a means to provide transparency, then it fails, because you need to change your programming model. It only provides an alternate means for coding.
Although these techniques do not improve transparency, I do recommend the combination of code generation and metadata, because it can relieve you from tedious implementation details. If you’re not already familiar with persistence frameworks, here’s a little background. Nearly all persistence frameworks make you build at least three things: the model, the database schema (the tables and indices), and a mapping between the two, often in XML. With metadata, you can automate two of the three artifacts. Using a tool like XDoclet, for example, you can add comments to your code that mark a field as persistent, and describe the relationships between the table and the code. In a pre-compilation step, XDoclet can then generate the mapping and schema based on these comments.
Be aware of what you’re giving up, though. Inserting metadata actually moves some configuration details into your code. The line between metadata and configuration becomes blurry. For example, you may like metadata if you’ve got the responsibility for creating both the code and the schema, because it can help consolidate the mapping, code, and tables in one place. However, the approach tends to couple the concerns of the domain model and persistence, and that can bite you. For example, at some future date, you might not maintain the database schema. Then, you would prefer to keep a separate mapping, so when the schema changed, you’d often need to change only the mapping. The moral is to use the technique to save on redundancy where it makes sense, but be careful.
The metadata problem comes up regularly. Marking future requirements within code, marking persistent fields, and highlighting certain capabilities of a method, class, or property are just three examples. JDK Versions 1.4 and before don’t have an adequate solution. For example, the Java language uses naming to tell the Java reflection API that a method supports a property—if get or set precedes a method name, then it’s treated as a property. The XDoclet tool is growing because Java developers need this capability.
A committee is looking into adding metadata directly to the Java
language in a specification request called JSR 175. For example, when
you create a DAO, there’s no good place to keep the
JDBC connection. You can sometimes solve this problem through
instrumentation. In order to define a metadata attribute called
Persistent, create an interface like this:
@Documented
public @interface Persistent {
public String jdbcURL( );
public String username( ) default "sa";
public String password( ) default "";
}In order to use the interface, add it to your class like this:
@Persistent(jdbcURL="jdbc:odbc:MyURL", username="btate", password="password")
public class Person
{
// enter the rest of the code here
}You can access the attribute through reflection. Then, you won’t have to pass the JDBC connection through to each DAO. You could potentially use this technique the same way people use XDoclet today. The difference is that the Java compiler itself would be examining your attributes, not a third party.
Imposing an invasive programming paradigm
Many people have tried to solve the problem of crosscutting concerns. Some of those attempts actually improved our lives, but many were mediocre or downright awful. For example, Java’s first attempt to solve crosscutting enterprise concerns used components. The idea makes sense. You can build a container that supports services. When you add a component to the container, it has access to the services, without requiring any code changes to the model. Your components are transparent (Figure 4-4). The devil is in the details, however. This approach depends heavily on how you define a component.
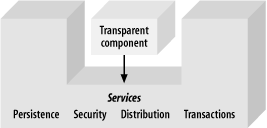
Java’s most ambitious attempt at component-oriented development for the enterprise, EJB, has been in many ways a disaster. Here’s how it works: the container accepts EJB components. To build a component, you define an interface that conforms to the specification and build a separate implementation. You then bundle deployment details in a configuration file called a deployment descriptor. When you deploy the EJB, the framework generates a component that uses your implementation and the interface you defined.
In this model, the container accepts frighteningly complicated
components and the programming model blows away any notion of
transparency. For example, to create a persistent component, a
developer needs to build five Java classes, plus a deployment
descriptor, plus the database schema. Further, the component model
does not completely hide the service from the implementation. To use
the persistence service, you must implement the
entityBean interface and create a
primaryKey class. This approach is not
transparent. It’s invasive.
Finally, you cannot readily extend or modify the services of the model. They are so integrated and coupled that it’s nearly impossible to inject new services or modify the old ones in meaningful ways. Commercial vendors don’t encourage you to even try. For example, RMI is the communication protocol for EJB. It’s so tightly integrated with the container and other services that it’s nearly impossible to replace.
Table 4-1 shows a summary of the alternatives that limit transparency. Notice it’s not all cut and dried. Usually, generating transparent code takes time and effort, so save that technique for the problems that will benefit it most.
|
Technique |
Advantages |
Disadvantages |
|
Invading the model |
Easy to build |
Model becomes too complex Maintenance gets tougher Combines concerns of services with model |
|
Subclassing |
Provides services without additional coding Uniform interface |
It complicates introduction of new services It abuses inheritance, leading to confusion It imposes code changes on the model |
|
Hardwired service |
The model remains transparent |
Changes in the model also force changes in the services layer |
|
Instrumentation |
Reduces replication of code Consolidates code and configuration, often easing implementation |
Imposes code changes related to a service on the model Couples configuration and code, possibly complicating maintenance |
|
Imposing invasive coding models |
Subject to implementation |
Subject to implementation |
In general, as your domain model increases in complexity, insulating the model and services from one another becomes more important and you need to achieve better transparency. In the next chapter, we’ll discuss techniques that take an extra step to achieve transparency.
Moving Forward
Now that you’ve seen (and likely used) many of the techniques that limit transparency, it’s time to examine some of the preferred techniques. Think about transparency in more general terms. You want to perform a service on a model without imposing any conditions on the model at all. In other words, you want to isolate your passive model to its own box. You also want to build services that have no advanced knowledge of your model. Here are some basic assumptions about transparency (as I am defining it) to know before we continue:
- The model consists purely of plain old Java objects (POJOs) or beans.
The services cannot assume anything about the objects, and will need to deal with the model in the most general terms. That means the service will deal with the model as plain Java objects, or beans.
- New services or model improvements must not force developers to make source code changes elsewhere
In other words, the service should not arbitrarily force changes on the model. Neither should the service need to change to support a different model.
- All model and service code changes must be automated, and may happen no sooner than build time
If the user can’t make changes, you’ve got to automate any coding changes. Further, you can make those changes no sooner than build time, meaning there should be no specialized preprocessor, macro language, or other type of nonstandard build step.
I intentionally allow two types of changes: first, I allow configuration, because it’s not Java code, and it’s flexible enough to change after build time. In fact, configuration is a preferred part of most solutions. I also permit controllers and impose no restriction on them. Controllers need not be transparent. This strategy makes sense if you think of controllers as clients of both the service and the model. It doesn’t make sense to hide an interface from its client, so I allow unrestricted access to the model, or the service, from the controller.
Since so many people value transparency and work to make it happen, it pays to look at a few problem spaces and examine the solutions that have been suggested. Persistence frameworks, lightweight containers, and aspect-oriented programming frameworks all need transparency to function. These are the ways that other frameworks solve the transparency problem.
Reflection
The most accessible way to build a service that depends on model data is runtime reflection. I don’t know why Java developers never have embraced runtime reflection the way that other languages have. It tends to be used by tool developers and framework providers but not general application programmers. You don’t have to use reflection everywhere, nor should you try. Instead, apply a little reflection where it can have a tremendous impact. Here are some things to keep in mind:
- General needs versus specific needs
When you need to access an object’s features in a general way, use reflection. For example, if you’re moving the color field from an object to a buffer for transport, and you don’t ever use the field as a color, consider reflection for the task, in order to reduce coupling. If you’re reading the color and setting other objects to the same color, direct property accesses might be best.
- Delaying decisions
If you don’t know the name of a method or class until runtime, consider reflection. If you already know the name, there’s no reason to delay the decision—a simple method call is a better choice. For example, through configuration, you can frequently decouple code and delay decisions until runtime. Reflection gives you a tool to help this happen.
Bear in mind that although the performance of reflection has improved in recent years, postponing binding decisions until runtime has a performance cost. Jumping to a specifically named method or property is much faster than going through the reflection API by a factor of two or more. Reflection offers great power, but be judicious.
The Reflection API
The Java reflection API lets you access all of the elements that make up a class at runtime without requiring source code or any other advanced knowledge of the classes. Using reflection, you can:
- Access a class’s definition
When you declare a class, you specify a class name and a set of modifiers (like synchronized, static, and public).
- Get all field definitions in a class
You can get the names, types, and modifiers for all of the fields in a class.
- Get all of the method definitions in a class
You can get the names, return types, parameters and types, and modifiers for all of the methods in a class.
- Get the parent class
Of course, since you can get a superclass, you can get all of the indirect methods and fields as well.
- Access an instance’s fields
You can read or write directly to the fields or utilize any getters and setters the instance might expose.
- Call an instance’s methods
Using reflection, you can also call methods on an instance.
In short, you can learn anything that you need to know about a class and directly manipulate an instance of that class. If you want to build a service that’s independent of the structure of an object, that’s a powerful combination of tools. You can inspect any method or field. You can load a class, call a method, or get the data from a field without knowing anything about the class in advance.
Further, reflection works well with a passive model because through reflection, the model already has all of the information that a potential service might need. That service can accept the whole model (or one class from the model) as input and use reflection to extract the data to do something useful, such as serialize the data to XML (like Castor), save it to a database (like Hibernate), or even wire together behaviors and properties (like Spring).
When you use the reflection framework, you must import the reflection libraries:
import java.lang.reflect.*;
The java.lang.reflection package
contains
everything you need, including four major classes:
Class, Constructor,
Field, and Method. These
classes let you deal with each major element of a Java class.
Java’s runtime architecture makes it possible.
If you’re like most Java developers, you probably deal much more with an instance of an object rather than the class object, but the class object is an integral part of Java’s runtime architecture. It contains the basic DNA for a class. It’s used to create classes and serves as an attachment point for static methods and members. It keeps track of its parent, to manage inheritance. You’ve probably used classes in these ways, but it’s also the tool that enables reflection. Figure 4-5 shows a class instance at runtime. Each object has an associated class, which is the DNA for a class that determines its type. The class is the central entry point for the Java reflection API. Using it, you can access the fields, methods, and constructors for any class. You can also invoke methods and access the data for an individual instance of the class. The rectangles in grey represent the Java reflection framework.
Accessing a Class
The class is the entry point for reflection. Once you have the class, you can call specific methods to get the associated methods, constructors, and fields. Using the class, you can get a single method or field by name, or get an array of all of the supported fields or methods.
You can get the class in several ways. Sometimes, you don’t have an instance. For example, if you’re working on a factory, you might have access to only the name of a class. In that case, load the class like so:
Class c = Class.forName(aString);
Other times, you might have nothing more than an object. In that case, you’d get the class from the instance, like this:
Class cls = obj.getClass( );
It’s actually not quite that simple. But for now, you just need to understand that Java supports more than one class loader (though the architecture for doing so changed for Version 1.2 and beyond). Chapter 6 fills in the details about class loading.
Accessing Fields
You’re probably ready to see a method that’s a little more concrete. Let’s use reflection to build a transparent service. Assume that you need a service to emit XML for a given object. Further, you want the model to remain transparent to the service, so you won’t need to change any model code to support new objects. Given a target object, you’re going to attack the problem using reflection:
Get the class for the target object.
Get the declared fields from the class.
Get the value for each field.
If the object is primitive, emit the appropriate XML.
I’ll show you the code all together, and then we’ll go through it in pieces. Here’s the entire method to process an object:
public static void doObject(Object obj) throws Exception {
[1] Class cls = obj.getClass( );
emitXMLHeader(cls);
[2] Field[] fields = cls.getDeclaredFields( );
for (int i=0; i < fields.length; i++) {
Field field = fields[i];
[3] field.setAccessible(true);
[4] Object subObj = field.get(obj);
[5] if (!Modifier.isStatic(field.getModifiers( ))) {
if ((field.getType( ).isPrimitive( )) ||
((field.getType( ).getName( ) == "java.lang.String"))) {
[6] emitXML(field.getName( ), subObj);
} else {
[7] doObject(subObj);
}
}
}
emitXMLFooter(cls);
}That’s it. Let’s see how the individual pieces work.
| [1] First, you’ve got to get the class object, given an instance. You need the class to emit the XML tags that bracket an entire object. You’ll also get individual fields from the class. Since you’re getting the class from a known instance, you use this method. |
[2] Next, the class must declare the fields. The
Class object lets you use several methods to
access its fields. At times, you’ll want to get a
specific field, given the name of a property. You can do so with
getField
(String name),
a method on class. Sometimes, you want to get only the declared
fields for a class. Do this with getDeclaredFields(
), which returns an array of fields. Other times, you also
want to get inherited fields. You can do this with
getFields( ), which returns an array of all fields
declared in a class and its parents. In this case,
you’ll get the declared fields, get back an array,
and iterate over the array. |
[3]Often, your service will need to access fields with a
narrow scope, such as private fields. You wouldn’t
want to always package such a service with your model, so the
Field class lets you step outside of the scoping
rules for convenience. In this example, you’ll want
to make sure that the field is accessible, even if
it’s a private field. To do so, simply call
setAccessible(true) on the field. |
[4]Access the field’s value by calling the
get( ) method on your field object, to get the
value for the individual field. |
[5]Look at the modifiers to see whether the field is
primitive or static. If it’s primitive, emit the
XML. If it’s static, you’ll want to
skip it, because it’s attached to the class instead
of your object. The reflection API encodes all of the modifiers
within an integer, so they’ll take up less space. In
order to read them, use a helper class called
Modifier to check if a modifier applies to your
class. You can access any modifier on a class, field, method, or
constructor in this way. |
| [6]If it’s primitive, emit the appropriate XML and complete the XML for the class. |
[7]If it’s not a primitive, call the method
doObject again, this time with the field value. |
The bulk of the work is done within the doObject
method, as it should be. The code to emit the XML is surprisingly
simple. Here are the methods to emit XML for the overall class, and
for a field:
public static void emitXML(String name, Object value) {
System.out.println("<" + name + ">");
System.out.println(value.toString( ));
System.out.println("</" + name + ">");
}
public static void emitXMLHeader(Class cls) {
System.out.println("<"+cls.getName( )+">");
}
public static void emitXMLFooter(Class cls) {
System.out.println("</"+cls.getName( )+">");
}The nuts and bolts are all there for an XML emitter. You’ve probably noticed that I cheated and handled only the simplest case. In fact, you’ll need to handle at least four types of fields for a general-purpose emitter:
- Primitives
With reflection, you deal with everything as an object. Since primitives are not objects, reflection wraps them in type wrappers. For example, to wrap the int 37 in a wrapper, you’d say
IntegerintWrapper=newInteger(37). To get the value from a wrapper, call a method on theIntegerclass, likeintWrapper.intValue( ).- Objects
If a field value is not an array or primitive, it’s an object. You can deal with other classes recursively. Get the class from the object and iterate through its fields.
- Arrays
Reflection uses a special class to wrap arrays called
Array. This class lets you access the type of the array and also provides access to each individual element of the instance.- Special classes
Generally, you’re going to want to treat some classes differently than others. For example, you may want special treatment for strings or collections.
We’ve only handled the first two types of fields, plus strings, but you can see how reflection works. You’ve supported a surprising number of classes without needing to alter model code at all. I must note that the emitter we’ve constructed here, though generic and useful, is not a full implementation. For a truly generalized emitter, our class would have to be able to handle circular references between classes, optional omission of referenced classes, logically transient fields, and some kind of optional name-substitution mapping pattern. Regardless, the point is no less salient: reflection can provide an enormous amount of power without any tight coupling.
You’ve seen how many transparent services use reflection: they simply access a list of properties, recursively if needed, and do the appropriate service. The types of services are unlimited:
Hibernate, a persistence framework discussed in Chapter 7, looks at the value of your model before and after you change it, and then generates SQL based on your mappings to save the changes to a database.
Spring, a lightweight container discussed in Chapter 8, populates fields in your objects based on a configuration file to wire your target objects to services.
XML emitters like Castor scan an object’s fields recursively to emit XML.
Distributed messaging services can use reflection to scan an object’s fields so that they can store compound objects without depending on a memory address.
So far, I’ve only told you how to deal with data. Fortunately, the reflection API also makes it easy to deal with behavior.
Accessing Methods and Constructors
You can use reflection to
examine and execute methods. You can
access methods through java.lang.reflection.Method
and constructors through
java.lang.reflection.Constructor.
I’ll describe the way that methods work;
you’ll find constructors work the same way.
As with fields, you can use Class to access
methods in two ways: getMethods( ) returns an
array with all supported methods, and getDeclaredMethods(
) returns only the declared methods for a class. You
t
hen can access the parameter types, modifiers,
and return value from the Method class.
Here’s an example that prints all of the declared methods in a class. It also prints out the types of each parameter, and the return value:
public static void printMethods(Object obj) throws Exception {
Class cls = obj.getClass( );
[1] Method[] methods = cls.getDeclaredMethods( );
for (int i=0; i < methods.length; i++) {
Method method = methods[i];
[2] System.out.println("Method name:" + method.getName( ));
[3] Class parmTypes[] = method.getParameterTypes( );
for (int j = 0; j < parmTypes.length; j++) {
System.out.print(" Parameter " + (j+1) + " type:");
System.out.println(parmTypes[j]);
}
System.out.println(" Returns: "+method.getReturnType( )+"\n");
}
}Here’s what the annotations indicate:
| [1] As with the field example, you’ll use the class object to return all of the declared methods for the class. |
| [2] Once you have a method, you have access to its name and type. |
| [3] You can also access each of the parameters. This example simply iterates through them to print their types. |
As you can see, inspecting methods works a whole lot like inspecting fields. All that remains is to invoke a method.
Invoking a method
Often, you’ll want to invoke a method or constructor without knowing all of the details until runtime, such as configuring an object from a file. To do so, you’ll need several things:
- The name of the method
Remember, that’s not enough to identify a method in Java.
- The types of parameters
You’ll also need an array with the parameter types, because two methods with different signatures can share the same name.
- The parameter values
You’ll need to build an array of parameters. If a parameter is an object, you’ll place it in the array directly.
If a parameter is a primitive or array, you’ll need to wrap it first. For example, call
new Integer(59) to wrap a primitive integer. To wrap an array, you wrap it in an instance of Array. For example, to wrap an array of five Integers, a single parameter would look likewrappedArraybelow:int a[]={1,2,3,4,5); Object wrappedArray = Array.newInstance(Integer.TYPE, a);- The return type
The invocation returns an object or nothing at all. You’ll need to cast it to the appropriate type.
Here’s the code to invoke a method called sum on
class Adder that takes two int
parameters and returns an Integer:
// target object is called "target"
Class c = Class.forName("Adder");
Class parameterTypes[] = new Class[2];
parameterTypes[0] = Integer.TYPE;
parameterTypes[1] = Integer.TYPE;
Method m = c.getMethod("sum", parameterTypes);
Object parms[] = new Object[2];
parms[0] = new Integer(1);
parms[1] = new Integer(1);
Integer returnValue = (Integer)m.invoke(target, parms);That’s really the bulk of working with reflection. Compared to a simple method invocation or a simple field access, it does not look simple. When you consider the overall impact, though, the effort makes a huge difference.
Injecting Code
To get better transparency, you can always automatically generate code and add it to the model. To date, most frameworks use this approach. Of course, since most Java developers use Ant to build their projects, adding a simple code enhancer to your applications is relatively easy to do with little intrusion on your build process. You can use code enhancement in two ways:
- Source code enhancement
This technique uses a program to read through your source code and make additions in the necessary places. For example, to make code transparent with respect to a performance tool that does performance profiling, you might run a precompiler program that injects code that takes a timestamp any time you enter or exit a method you want to measure.
- Byte code enhancement
Since Java programs compile to a standard compiled form called byte code, you can inject byte code to add services and still maintain transparency. For example, most JDO implementations use a byte code enhancer.
Often, when you inject code, you’re actually injecting methods that perform the work of your intended service, as with the source code enhancer in Figure 4-6. Source code enhancement takes a class as an input and then generates code, typically method calls, to inject service capabilities into code, completely preserving transparency in the original class.
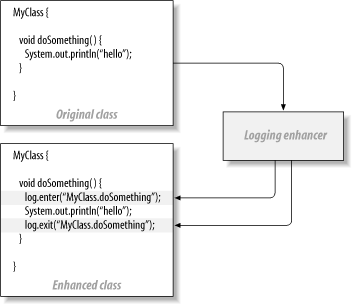
JDO enhancers work this way: you create a class
that’s transparent with respect to persistence. The
job of the JDO enhancer is to
implement the
PersistenceCapible interface. In order to make the
class persistent, let your build process run it through a JDO
enhancer. (Some of these use source code enhancement but most use
byte code enhancement.) The enhanced class then calls the JDO
framework to actually implement persistence. Some aspect-oriented
programming frameworks use byte code enhancement, as well. The
technique has many benefits:
You don’t have to make any changes to source code.
You don’t impose any restrictions on your class, so you completely preserve transparency.
Code injection is fast at runtime. The additional steps occur at build time, so you pay any performance penalty once, at build time.
This is a build-time technique. If you’re using Ant or something similar, after a one-time change to your build scripts, you will not need to make other changes to your build process.
For the most part, source code injection works well for techniques that are easy to parse and inject with simple code. Tasks such as adding logging, instrumenting code for performance analysis, or intercepting method calls all work well with a simple code injector.
Byte code enhancement frameworks
Byte code enhancement is a little more difficult to pull off. You’ll need a strong knowledge of compilers, the Java byte code specification, and finer issues like threading. For this reason, most people use byte code enhancement through other frameworks.
Some developers frown on byte code enhancement. It’s been my experience that fear of the unknown drives this attitude more than practical experience. Knowledgeable teams can and do build byte code enhancers for commercial applications. Still, some perceive disadvantages:
Some fear that byte code enhancement may be difficult to debug. If you’re the type of programmer who needs to see the Java source for every line of code in your system, byte code enhancement is not for you. I’ve generally found that enhancements are little more than method calls into a services layer, so it’s usually not an issue.
Theoretically, two byte code enhancers applied to one class could possibly collide, causing some breakage. I haven’t seen this happen in practice. In fact, not many byte code enhancers exist.
The framework you choose depends on the services you need. JDO uses code enhancement to add transparent persistence. Some tools that make understanding decompiled code more difficult, called obfuscators, also use byte code enhancement to help you protect your intellectual property. In addition, some AOP frameworks enhance byte code at runtime when they load classes. You’ll probably wind up using byte code enhancement solely through one of these.
Generating Code
As you’ve probably noticed, many Java frameworks require a whole lot of tedious, redundant syntax. In his book Refactoring (Addison-Wesley), Martin Fowler calls such a design a “code smell.” Since Java developers are a lazy and creative lot, they seek ways to automatically generate repeated bits of code. Further, they think of ingenious ways to configure their code generation engines. Take an EJB application, for example. In order to create the persistent model with a remote interface, you’ll need to create at least seven files: the home object for lifecycle support, a local that serves as a proxy, the interface, implementation, primary key, deployment descriptor, and schema. With code generation tools like XDoclet, you can automatically generate at least five of the seven, and often six of the seven. You create an XDoclet by instrumenting your code with simple JavaDoc comments. While this technique doesn’t make your code completely transparent with respect to persistence, it certainly makes it more transparent.
How Code Generation Works
While novice and intermediate Java developers see code generation as black magic, it’s really quite simple. If you’ve ever used a mail merge program, you know how it works. You create a working piece of code. Then you mark the areas of the code that vary from instance to instance. Together, these form your template. Next, you provide data to fill in the variables. Like a mail merger, the code generator takes your template, fills in the blanks, and generates working code, as in Figure 4-7.
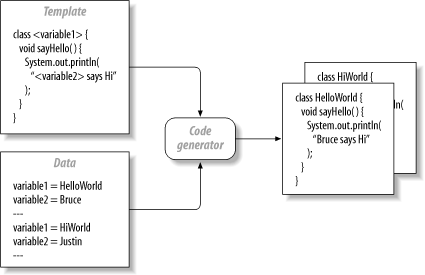
Figure 4-7 shows the general concept, although it simplifies the problem in several ways. You can generate multiple targets. You can also generate code with complex structures, such as repeated or conditional blocks. In general, if you can describe the patterns in your code and clearly define areas of duplication, you can probably find or build something to generate it. There are several types of generation strategies:
- Wizards
Many an IDE uses wizards to provide data for code generation templates. Microsoft Studio is famous for these, but others use wizards prolifically as well.
- Code inspection
Some generators, like XDoclet, parse source code to understand what to generate. The generator may parse the Java application and look for specialized commands in comments or certain naming conventions. It may also use reflection to determine generation requirements.
- Template engines
Some code generators work with a general-purpose template engine and let you generate targets from a variety of prepackaged templates. Perhaps the most popular is Apache’s Velocity.
- Alternative model transformations
If you’re starting with a non-Java model (most commonly, XML), you can simply use XML’s transformation stylesheets (XSLT) to generate your targets, or do a transformation in other ways.
- Combined approaches
The MiddleGen open source project combines approaches, using Velocity, XDoclet, Ant, and JDBC to build a database-driven template approach to generate code for EJB, Struts, and a variety of others.
As you can see, code generation lets you minimize redundant data through a variety of approaches. The end result is a happier developer who’s not a slave to tedious details.
Code Generation and Transparency
You can use code generation for much more than saving duplication. From a configuration file containing classes with properties and their types, you can generate a database schema, a transparent model, and a DAO layer. It’s an interesting way to code, with several tangible benefits:
You can have a completely transparent model.
If you generate your services, your developers will not need to modify them to support your model.
If your requirements of generated services change, you can change a template in one place and generate them all again.
You can create a generalized domain language for your problem domain without writing a compiler for it. (You can solve problems in a specialized template language that generates Java, whose compiler you then take advantage of.)
Whenever you read a list of benefits like this one, keep in mind that there’s always a big “but.” Generated code does have its downside:
When it’s used to solve duplication in an application, code generation treats the symptom (retyping tedious redundant code) and not the cause (too much duplication). As such, it can remove your motivation for refactoring problem areas.
When it’s used with code instrumentation (such as XDoclet), it can couple your configuration with your code. You may be combining concerns that should logically be separated, such as your code and your schema designs.
Code generators often create seriously ugly code. Even if you don’t have to write it or maintain it, ugly code is hard to debug and understand. For example, a wizard may not know whether a class has been loaded or not, so it’s much more likely to generate code that looks like this:
cls = Class.classForName("java.lang.String"); str = c.newInstance( );than code that looks like this:
String str = new String( );
Developers may change generated code, even outside of protected areas. As a result, changes to the template will not make it into production code.
Code generation is just one of the tools in your tool box and with each application, you should look at it with fresh skepticism. In particular, observe these rules:
If you can’t read it, don’t use it. A wizard may seem to help at first, but it’ll spin out of control quickly if you don’t understand every line that it generates. You want to know that the code will perform and that you can maintain it when the time comes.
Try to refactor duplication before addressing it with code generation. In other words, put away that sledgehammer, and grab a flyswatter instead.
Change the templates instead of the generated code. If you must change generated code, make sure that you’ve got a protected area to do so, and that you stay within it. To enforce this rule, don’t check in generated code. Build it from scratch each time.
Use respected templates and products. Treat generated code with the same skepticism that you reserve for human-written code.
As with the other techniques mentioned here, many readers of this book will never build a code generator. You don’t have to. Instead, you can choose from a number of frameworks or products that enable code generation or use it under the covers. While code generation does not always provide transparency by itself, it can relieve you of many of the details when you’re forced to use a framework that lacks transparency.
Advanced Topics
Now you’ve seen three tools for achieving transparency. If you’re anything like my clients, you’re probably wondering which is best. I’m going to carve that decision into three pieces:
If I’m building a transparent service myself, I prefer reflection. I’d simply prefer to call a library than build a code generator or byte code injector. I prefer to have business logic within my domain model (instead of just data holders), and that eliminates code generation. Though the performance is doubtlessly superior, byte code generation is too difficult and risky for most small or inexperienced IT shops.
If I’m buying a tool or framework, I like the idea of byte code enhancement. I like that you pay much of your performance penalty at build time instead of runtime and I like that after the build, I don’t have to worry about the service. With tools like JDO, I’ve rarely had instances where byte code enhancement made things difficult for me to debug, and I’ve always been impressed with the flexibility of byte code generation over reflection. As a case in point, after coming down hard on JDO vendors in their marketing literature, Hibernate in fact added a byte code enhancement library, called CGLIB, to improve certain aspects (such as lazy loading).
I don’t mind code generators, but I don’t lean on them for transparency. In general, better techniques get the same benefits without some of the drawbacks mentioned earlier in this chapter.
If you’re gung-ho about transparency, keep an eye on a couple of evolving debates. The first is the concept of coarse- and fine-grained services. The second is the future of programming techniques that may enhance your experience.
Coarse- and Fine-Grained Services
Nearly all applications support two types of services: coarse- and fine-grained. You may decide that it makes perfect sense to attach all services to the same point. Be wary, though. Many early EJB applications used that design, God rest their souls. Your problem is two-fold. First, if you present an interface, your users may use it whether it’s a good idea or not. Second, different services have different performance requirements.
Consider CORBA for a moment. The idea was to have very large object models, which could find and talk to each other whether they were in the same memory space or across the globe. If you bought into that notion (as I did), you know how damaging it can be. The problem is that interfaces often have fundamentally different requirements. If your user interface wanted to display every field on a distributed object, it would need to make a distributed method call for every field, which is very expensive. Let’s take the problem one step further. Let’s say that you wanted to display every line of an invoice from across the network. You’d have to make a call to every field of every object on line item on an invoice, as in Figure 4-8. Each call represents a round-trip across the vast network, and regardless of how efficient your code is, the speed of light is still immutable. You have to be intelligent about the way that you apply transparency.
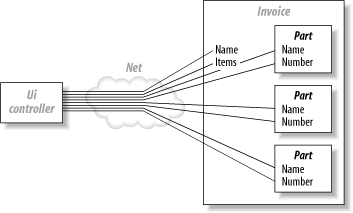
Instead, you need coarse- and fine-grained interfaces. Your model provides your fine-grained interface, and a façade provides a coarse-grained interface. Think of a fine-grained interface as private. You only want to share the most intimate details of an object to a selected number of, ahem, clients. Your public façade will provide the entry point to the rest of the world.
You probably code this way already. If you don’t, you’re in for a treat. Facades make a convenient interface for providing a secure, transactional, or distributed service. You can offer these services transparently with many of the techniques in this book. Your façade need not be a session bean. You can achieve many of the benefits through lightweight containers and possibly RMI. The difference between this model and CORBA is striking: you don’t sacrifice transparency, but you can attach coarse-grained or fine-grained services to the appropriate interfaces. Apply coarse services like messaging, distribution, transactions, and security to your façade, and your fine-grained services—such as logging and persistence—to your model.
A New Programming Paradigm
You might have noticed that object-oriented technologies do not handle services, like security or logging, that broadly reach across many objects very well. Academics call this problem crosscutting concerns. For this reason, many researchers and leading edge developers increasingly tout the aspect-oriented programming (AOP) model. While it’s still in its infancy, AOP lets you insulate the issues of crosscutting concerns from the rest of your application. I’ll talk more about AOP in Chapter 11.
It’s my belief that new programming models evolve much more slowly than predicted. I also believe that once they succeed, they have a much bigger impact than we expect. Such was the case with object-oriented technology, which grew incrementally over 10 years through the adoption of C++, the commercial failure of Smalltalk, and finally the successful adoption of Java. You can find similar adoption patterns around high-level languages, structured programming, and even interpreted languages. While you might not see widespread AOP adoption by next year, you will likely see ideas that support an AOP move to the forefront rapidly:
- Transparency
In this chapter, you’ve seen the impact of transparency across the Java language. The fundamental goal of AOP is to take crosscutting concerns out of your model.
- Byte code enhancement
Many developers and decision makers reacted violently to any framework considering this technology, especially early versions of JDO. Increasingly, Java developers are recognizing the value of byte code enhancement. With each new implementation, support gets stronger.
- Interceptors
Aspect-oriented frameworks intercept program control at critical places, such as when control passes into or from a method, when objects are destroyed, and when variable values change. Interceptors provide a convenient way of attaching behavior to an object through configuration, without forcing changes upon a model.
- Lightweight containers
In Chapter 8, you’ll see a lightweight container called Spring in action. Designers quickly saw that containers such as Spring, Avalon, and Pico make AOP easier.
Networking in person or online is the best way to deal with constant change. You need to be near the buzz so that you can respond to the ceaseless waves of changes as they break.
Summary
If you’re trying to decouple that service from your model and you feel like you’re standing half-dressed after pulling a single thread a little too far, take heart. If you put the effort into building transparency into your application, you’re likely to get where you intended to go, fully dressed and on time.
Some other decoupling techniques don’t go far enough. Inheriting a service leads to awkward models that are tough to extend in other ways. Hardwiring services has a place, but it starts to be limiting as an application grows in scope. New programming models such as AOP may help you some day, but others (like heavyweight invasive containers) can kill you.
Instead, if you’ve got an exceptional need to decouple a service from your model, strive for transparency. Effective frameworks seem to be divided across three camps. All have relative strengths and weaknesses.
Reflection is the tool of choice if you’re building a lightweight transparent service. It’s relatively easy to use and doesn’t require any changes to your build process. The downside is performance but if you don’t overuse it, reflection is fast enough for many applications.
Enhancement techniques directly modify the byte code in your application to perform the appropriate task. They do change the build process, and may theoretically be difficult to debug. In practice, though, it’s a high-performance technique that’s growing in popularity. Some frameworks to provide persistence, obfuscation, and aspect-oriented weavers all use byte code enhancement, either at runtime or build time.
Code generators are relatively easy to understand and use. They merge a template and data to give you working code. Frameworks like XDoclet use code generation less for transparency than to eliminate repetition, but you can use other code generation frameworks like MiddleGen to create services and transparent models, often without any user intervention beyond creating a few JavaDoc tags or an XML file.
Use these techniques to build transparent services. Don’t forget that complete transparency can often burn you, as with CORBA. Instead, create transparent services to handle coarse-grained interfaces, such as façades, and fine-grained services, such as your model. Keep an eye firmly fixed on the future. While AOP languages and environments may still be a ways off, AOP techniques such as lightweight containers and interceptors will creep into the mainstream very quickly.
In this chapter, our focus was on using transparency to decouple services from your model. In the next chapter, you’ll learn to choose the right tool for the job. It may sound like a trivial detail, but using poor technologies or abusing good ones has sunk thousands of Java projects.
Get Better, Faster, Lighter Java now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

