Chapter 4. Loading Knowledge Graph Data
In Chapter 3 you became acquainted with graph databases and query languages, and even learned a little about database internals. You also saw how to query and update knowledge graphs. But there’s a special case of updating that warrants more depth: bulk imports, which are useful across the whole lifecycle of a knowledge graph.
Tip
For each of the techniques in this chapter, it makes sense to start small. Take a small, representative slice of your data and import it into the database. Check that the model works as intended before running the full import job. A quick check can save you minutes or hours of frustration.
In this chapter, you’ll learn about three ways of bulk loading data into a knowledge graph. You’ll learn how to incrementally load bulk data into a live knowledge graph and how to bootstrap a knowledge graph with huge amounts of data. But first you’ll learn how to use a graphical tool to define the structure of a knowledge graph and map data onto that structure for bulk imports.
Loading Data with the Neo4j Data Importer
You should start with the easiest of the three popular tools for Neo4j bulk data loading. The Neo4j Data Importer is a visual tool that allows you to draw your domain model as a graph and then overlay data onto that graph, with comma-separated values (CSV) files that contain the data for your nodes and relationships.
Data Importer greatly simplifies bootstrapping your knowledge graph, especially for beginners. However, it does still require that you have your data in CSV files ready to use.
To keep the examples short, they’ll use the social network data that you saw in Chapters 1 and 3. Bear in mind that this simple example works but real imports tend to use much larger files!
First, draw the social network.
The diagram in Figure 4-1 shows the domain model, consisting of Person and Place nodes and FRIEND and LIVES_IN relationships.
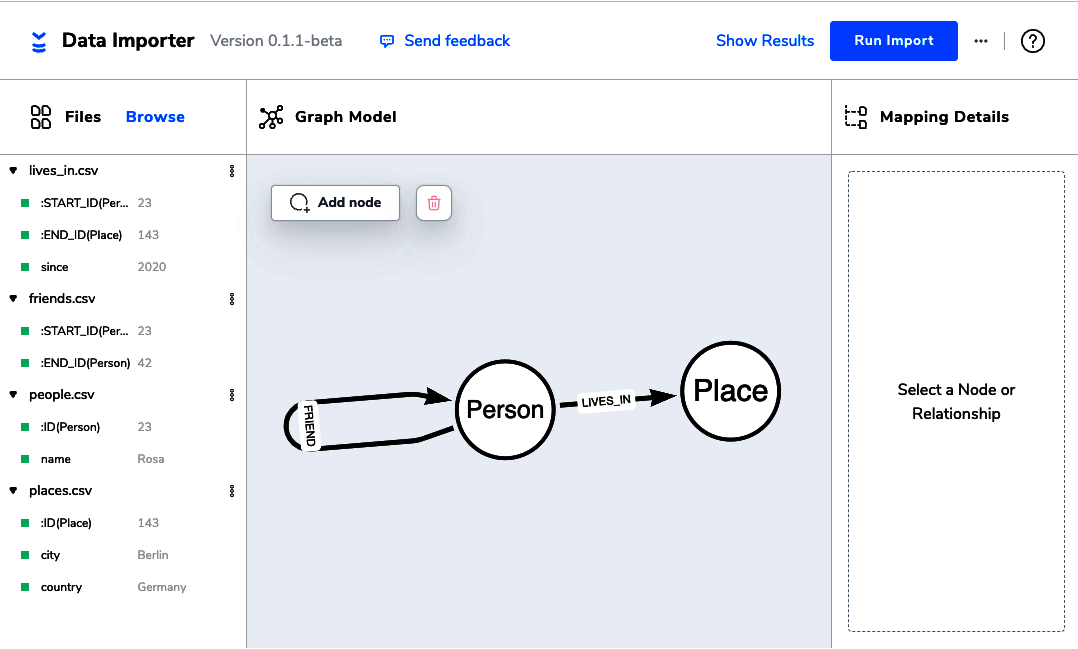
Figure 4-1. Setting up the domain model in the Neo4j Data Importer
First, add your CSV files like those shown in Examples 4-1, 4-2, 4-3, and 4-4 by browsing for them in the left panel of the tool. Draw the nodes and relationships that constitute the domain model using the simple drawing tools, and annotate each of them using the mapping details panel on the right.
Example 4-1. people.csv data for Person nodes in the Neo4j Data Importer
:ID(Person),name 23,Rosa 42,Karl 55,Fred
In Example 4-1, the ID of the node and its label are specified as :ID(Person) with a single property name.
In the subsequent rows, you can see data that matches that pattern, like 23,Rosa.
Note that the ID column is used later to link the graph together; it’s not (necessarily) part of the domain model and can be expunged from the model at a later point.
Example 4-2. friends.csv for FRIEND relationships between Person nodes in the Neo4j Data Importer
:START_ID(Person),:END_ID(Person) 23,42 42,23 42,55 55,42
In Example 4-2, the start and end IDs of the Person nodes are specified with :START_ID(Person),:END_ID(Person).
You have a relationship that goes from one Person node represented as an ID to another.
In each row you can see the corresponding IDs of the start and end nodes of a FRIEND relationship, which matches the data in Example 4-1.
Example 4-3 follows the same pattern as Example 4-1, but for Place nodes rather than Person nodes.
The header specifies that there will be an ID for Place nodes followed by city and country properties to be written onto each of those nodes.
Example 4-3. places.csv data for Place nodes in the Neo4j Data Importer
:ID(Place),city,country 143,Berlin,Germany 244,London,UK
Finally, Example 4-4 declares the LIVES_IN relationships between Person and Place nodes.
The header specifies the ID of Person nodes as the start of the relationship, the ID of Place nodes as the end of the relationship, and an optional since property on the relationship.
The CSV data then follows that pattern.
Example 4-4. lives_in.csv for LIVES_IN relationships between Person and Place nodes in the Neo4j Data Importer
:START_ID(Person),:END_ID(Place),since 23,143,2020 55,244 42,244,1980
Given these CSV files, you can now run the Neo4j Data Importer. It executes against a live database and so requires an endpoint and credentials in order to work. Once the Data Importer has successfully executed, you will receive an import report like the one shown in Figure 4-2.
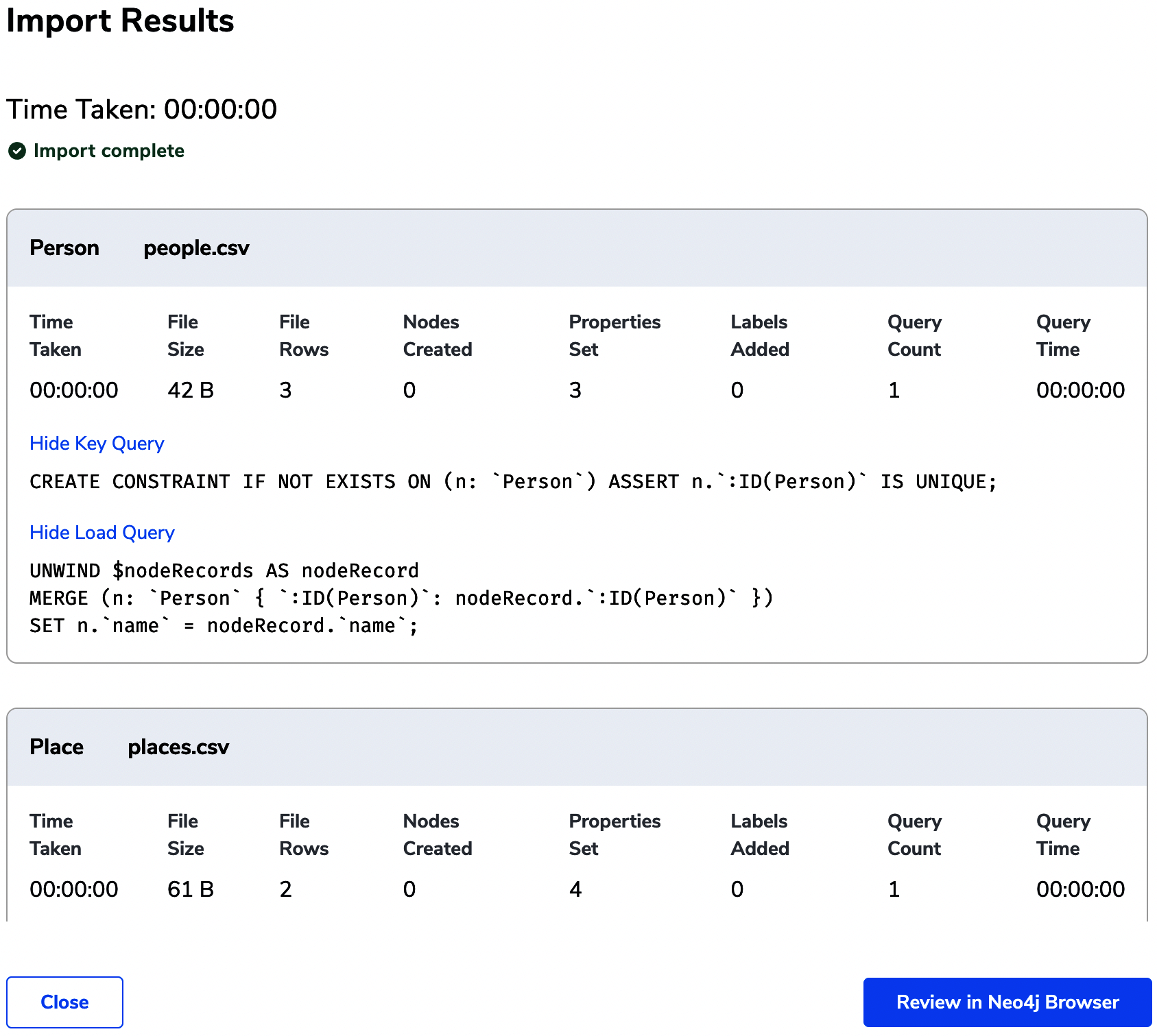
Figure 4-2. The Data Importer has finished, and you can see the Cypher queries it used to load data into Neo4j
In Figure 4-2, you can see some of the Cypher scripts that have executed against the database along with statistics on the import.
A handful of common Cypher idioms stand out from the report: CREATE CONSTRAINT, UNWIND, and MERGE.
Here you should use UNWIND to feed rows of CSV data into a MERGE operation that creates a Person node with an ID property.
It then writes a since property on that node using SET.
If there is no since property for any row, that’s not a problem because SET tolerates the absence of data for those relationships.
Tip
UNWIND is a Cypher clause that takes a list of values and transforms them into rows that are fed into subsequent statements.
It’s a very common way to handle input data, and you’ll see it frequently in this chapter.
Its usual form is
UNWIND [1, 2, 3, null] AS x RETURN x
where the values 1, 2, 3, and null will be returned as individual rows to the caller.
UNWIND is again used to feed relationship data from Example 4-4 into the graph, as shown in Figure 4-3.

Figure 4-3. Mixing MERGE and MATCH with data fed by UNWIND
Also in Figure 4-3, you can see how a combination of MERGE and MATCH is used.
Remember that in Chapter 3 you used MERGE when it wasn’t clear whether or not a node or relationship existed, since MERGE acts like MATCH when a record exists and like CREATE when it does not.
Here you don’t MERGE for Person and Place nodes because they are guaranteed to exist in the input CSV file.
Instead, you only need to MERGE the LIVES_IN relationship between those existing nodes, where MERGE will ensure there are no duplicate relationships.
Of course, you could write the equivalent Cypher by hand and run it as a set of scripts, and it would have the same effect (as per the following section, “Online Bulk Data Loading with LOAD CSV”). You could also take this Cypher and treat it as an automatically generated source, which could be modified and hosted in source control so that it can be evolved as the knowledge graph grows over time.
The Neo4j Data Importer gives you a head start not only with the Cypher code for ingestion but also by visualizing, verifying, and debugging the model and the data that will flow into it before you start the import. As such, it’s valuable to experienced Neo4j developers as well as folks who are new to graph databases.
Online Bulk Data Loading with LOAD CSV
In Chapter 3 you saw how to create (and update) records in the database using the CREATE and MERGE Cypher commands.
In “Loading Data with the Neo4j Data Importer”, you learned how a visual tool generates Cypher code that then loads CSV data into a live database.
But there is another way of scripting CSV imports: using Cypher’s LOAD CSV command.
LOAD CSV allows you to import CSV data into an online graph from a variety of places.
You can load CSV data via web addresses (like Amazon S3 buckets or Google Sheets) and filesystems, and LOAD CSV imports happen while the database is live and serving other queries.
Usefully, CSV files can also be compressed, which helps when transferring large amounts of data.
LOAD CSV is most simply explained by example.
First load all the Place nodes from the social network using LOAD CSV.
The CSV file used is in Example 4-5.
Example 4-5. CSV data for Place nodes
city,country Berlin,Germany London,UK
Since the place data is uniform, you can use a straightforward LOAD CSV pattern to insert the nodes into the knowledge graph, as shown in Example 4-6.
Example 4-6. Simple LOAD CSV for Place nodes
LOAD CSV WITH HEADERS FROM 'places.csv' AS line
MERGE (:Place {country: line.country, city: line.city})While Example 4-6 isn’t a complete solution to loading the knowledge graph (since it only loads places), it exemplifies the basic pattern for using LOAD CSV.
The first line breaks down as follows:
-
LOAD CSVis the Cypher command you want to execute. -
WITH HEADERStells the command to expect header definitions in the first line of the CSV file. While headers are optional, it’s usually a good idea to use them. Headers allow you to refer to columns with a friendly name (rather than just a numerical index), as shown in the theMERGEstatement in Example 4-6. -
FROM 'places.csv'tells the command where to find the CSV data. Note that Neo4j security permissions may have to be altered if you want to import from nondefault locations in the filesystem or from remote servers. -
AS linebinds each row in the CSV file to a variable in Cypher calledlinethat can be accessed subsequently in the query.
The data about people is much less regular. The only thing known for all people is their name. For some people, you might also know their gender or age, as shown in Example 4-7.
Example 4-7. CSV data for Person nodes
name,gender,age Rosa,f, Karl,,64 Fred,,
Having irregular data (just like in the real world) means you need to take a slightly more sophisticated LOAD CSV approach.
You’ll need to change the script to be like Example 4-8.
Here you can use SET to avoid writing any null properties into the node, which would cause the operation to fail.
If you try to use the simpler approach from Example 4-6, the query will fail, complaining about null property values.
Example 4-8. More sophisticated LOAD CSV for irregular Person nodes
LOAD CSV WITH HEADERS FROM 'people.csv' AS line
MERGE (p:Person {name: line.name})
SET p.age = line.age
SET p.gender = line.genderFinally, you can add the LIVES_IN and FRIEND relationships to link the new nodes into a knowledge graph (or link them to existing nodes if you have a knowledge graph already).
In Example 4-9, the FRIEND relationships are encoded in CSV such that, for example, there is a FRIEND relationship from Rosa to Karl and another from Karl to Fred.
Example 4-9. FRIEND relationships in CSV format
from,to Rosa,Karl Karl,Rosa Karl,Fred Fred,Karl
Tip
This is a small example, so the names of the people are sufficiently unique to act as IDs. For a real import, this is unlikely to hold, and introducing unique numeric IDs for nodes is sensible. In practical terms, this would mean adding an incrementing integer ID for each row in the people and places CSV files.
You can use that data to create FRIEND relationships (if they don’t already exist), as shown in Example 4-10.
Note that because you know the Person nodes have already been populated in Example 4-9, you can just MATCH them and fill in any relationships between them using MERGE in Example 4-10.
Example 4-10. Loading FRIEND relationships
LOAD CSV WITH HEADERS FROM "friend_rels.csv" AS line
MATCH (p1:Person {name:line.from}), (p2:Person {name:line.to})
MERGE (p1)-[:FRIEND]->(p2)The LIVES_IN relationships are a little trickier since they optionally have since properties on them.
In Example 4-11, the line Fred,London,, has a trailing double comma, which indicates no value in the since field.
Care is needed when handling this situation.
Example 4-11. LIVES_IN relationships in CSV format
from,to,since Rosa,Berlin,2020 Fred,London,, Karl,London,1980
To load the data from Example 4-11, you use the Cypher code in Example 4-12.
Note that you are not using MERGE (person)-[:LIVES_IN {since:line.since}]->(place) to set the since property value because it would fail for those rows where the property is omitted.
Once again, you should use SET after the relationship record has been created to add the property.
This is perfectly fine because the statement is executed transactionally, so the relationship and its property will be written atomically despite being separated syntactically.
Example 4-12. Loading FRIEND relationships with property data
LOAD CSV WITH HEADERS FROM "friend_rels.csv" AS line
MATCH (person:Person {name:line.from}), (place:Place {city:line.to})
MERGE (person)-[r:LIVES_IN]->(place)
SET r.since=line.sinceFor very large data imports, say one million records and up, it’s often sensible to break the operation into smaller batches.
This ensures that the database isn’t overwhelmed with large inserts and keeps the other queries on the knowledge graph running smoothly.
Prior to Neo4j 4.4, you would use the apoc.periodic.iterate function from the APOC library for this purpose.
From Neo4j 4.4, similar functionality is available directly in Cypher using CALL {...} IN TRANSACTIONS OF ... ROWS.
Using this method you can change the loading of Person nodes into smaller batches, as shown in Example 4-13.
In a real system, the number of rows and number of batches would both, of course, be much higher.
Example 4-13. Loading People nodes in batches (prefix with :auto if running from the Neo4j Browser)
LOAD CSV WITH HEADERS FROM 'people.csv' AS line
CALL {
WITH line
MERGE (p:Person {name: line.name})
SET p.age = line.age
SET p.gender = line.gender
} IN TRANSACTIONS OF 1 ROWSOne of the nice things about using LOAD CSV is that it’s regular Cypher.
So all the things you’ve learned about Cypher can be put to use, including EXPLAIN and PROFILE to analyze, debug, and tune bulk ingestion.
For example, the simple query plan for loading FRIEND relations is shown in Figure 4-4.
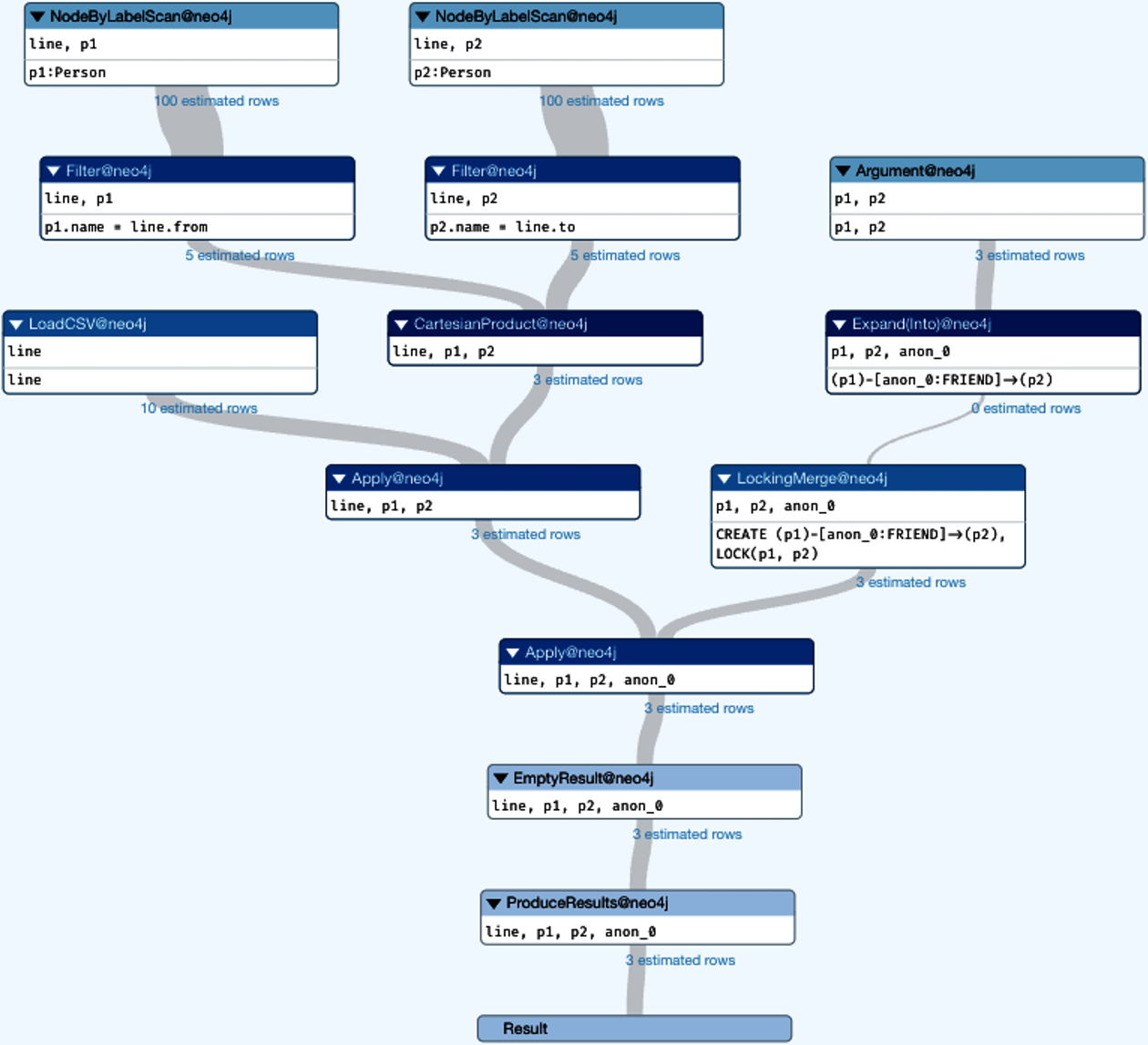
Figure 4-4. Visualizing the query plan for a LOAD CSV operation
Figure 4-4 looks good overall.
Even the Cartesian product operator (which the Neo4j Browser will warn you about) is not a problem because it’s fed by a filter that reduces its inputs to just two matching nodes and the corresponding CSV line.
Of course, that might not always be the case, and using EXPLAIN or PROFILE on a small amount of representative input data can help solve any performance problems before they start.
Tip
In addition to Cartesian products, look out for any eager operators in the query plan or profile.
Eager operators pull in all data immediately and often create a choke point.
Mark Needham has an excellent blog post on strategies for removing eager operators.
LOAD CSV is fast and can be used at any time during the lifecycle of your knowledge graph.
The database remains online during updates so that it can process other queries.
It can, however, take some tuning to achieve good throughput without dominating regular database operations.
But LOAD CSV is not the last option for bulk inserts—you have one more to add to your toolkit.
Initial Bulk Load
Often there’s an initial import that bootstraps the knowledge graph with potentially large amounts of data.
It’s feasible to use the Neo4j Data Importer or LOAD CSV to do this, but there is a faster way, albeit one that is somewhat low level.
The Neo4j command-line tool neo4j-admin actually has an offline importer built in.
The neo4j-admin import command builds a new Neo4j database from a set of CSV files. (For more depth, there’s a full tutorial on neo4j-admin import.)
The neo4j-admin tool ingests data very rapidly, with sustained performance of around one million records per second, and has optimizations for high-throughput devices like SSDs and storage area networks (SANs).
It’s a high-performance method for building your bulk imports to your knowledge graph—with the caveat that the database must be offline each time it is run.1
Warning
The caveat with neo4j-admin import is that it’s an offline importer, which is why it’s so fast.
The database will be ready for serving knowledge graph queries as soon as the import finishes but is unavailable during building.
To use neo4j-admin import, you first have to assemble your data into CSV files and place them on a filesystem that the importer can access.
The filesystem doesn’t necessarily have to be local—it can be a network mount.
It does have to be a filesystem since neo4j-admin import will not read data from, for example, S3 buckets or other data stores that are not filesystems.
Since data volumes may be large, the tool also supports compressed (gzipped) CSV files.
At a minimum, the importer expects the CSV files to be presented as separate files for nodes and relationships.
However, it’s good practice to have separate CSV files for different kinds of nodes and relationships, for example, splitting out Person and Place nodes and FRIEND and LIVES_IN relationships.
Very large files should be split into multiple smaller CSV files with the CSV header itself in a separate file. This makes any text editing of large files much less painful since smaller files are more convenient for text editing.
Tip
You don’t have to make sure the CSV files are perfect, just in good enough condition. The importer will tolerate different separator characters, ignore additional columns, skip duplicates and bad relationships, and even trim strings for you. However, you’ll still have to ensure there are no special characters, missing quotes, unseen byte-order marks, and the like that can affect the importer.
Start by getting your CSV files ready.
Example 4-14 is a typical self-contained CSV file.
It has a header row that defines the names of the columns and then rows of data.
The header :ID(Person) says the column represents the ID of a node, and the node has the Person label.
As with the Neo4j Data Importer, the ID isn’t necessarily part of the domain model but is used by the tool to link nodes together.
The name header declares that the second column is a property called name that will be written into the current node.
Example 4-14. people.csv contains unique IDs for Person nodes and a name property for each.
:ID(Person),name 23,Rosa 42,Karl 55,Fred
While Example 4-14 is self-contained, for larger imports it’s more convenient to separate things out.
For example, for FRIEND relationships between Person nodes, you can split the CSV files into a header file that describes the data and several (typically large) data files, as shown in Examples 4-15, 4-16, and 4-17.
This separation makes data wrangling much easier since changes to the header don’t involve opening one really large file in a text editor!
Example 4-15. friends_header.csv contains the signature for relationship data for the (:Person)-[:FRIEND]→(:Person) pattern
:START_ID(Person),:END_ID(Person)
Example 4-16. friends1.csv contains the first set of relationship data for (:Person)-[:FRIEND]->(:Person) patterns
23,42 42,23
Example 4-17. friends2.csv contains the second set of relationship data for the (:Person)-[:FRIEND]→(:Person) pattern
42,55 55,42
The importer treats Examples 4-15, 4-16, and 4-17 logically as a single unit, no matter how many files there are ultimately.
You can use the same separation of concerns for nodes as well as relationships.
Example 4-18 declares a CSV header for Place nodes which have a Place label and ID, city, and country properties.
Examples 4-19 and 4-20 contain the data formatted according to the header.
Example 4-18. places_header.csv contains the signature for Place nodes
:ID(Place), city, country
Example 4-19. places1.csv contains data for Place nodes
143,Berlin,Germany
Example 4-20. places2.csv contains data for Place nodes
244,London,UK
To connect people and places, you need to have something like Example 4-21, which contains relationships starting with Person nodes and ending with Place nodes.
Some, but not all, of those relationships also have since properties on them representing the date when the person began living in the place.
The since property will, if present, come from the third column of the CSV file.
Example 4-21. people_places.csv contains data for LIVES_IN relationships and an optional since property
:START_ID(Person),:END_ID(Place),since 23,143,2020 55,244 42,244,1980
Assuming the CSV data is sufficiently correct, with no superfluous characters or dangling relationships, you can run the importer over the data to bootstrap the knowledge graph.
Example 4-22 shows a command-line example that will insert data from the CSV files into a knowledge graph.
Note that it’s a multiline command, so be careful to include those \ characters at the end of each line.
Example 4-22. Running neo4j-admin import
bin/neo4j-admin import --nodes=Person=import/people.csv \
--relationships=FRIEND=import/friends_header.csv,import/friends1.csv,\
import/friends2.csv \
--nodes=Place=import/places_header.csv,import/places1.csv,import/places2.csv \
--relationships=LIVES_IN=import/people_places.csvThe neo4j-admin import tool is very fast and suitable for very large datasets (containing many billions of records), with approximately a million records per second of sustained throughput.
Bear in mind that large imports need large amounts of RAM and might still take hours to execute.
The tool is not resumable, so be careful not to type Ctrl-c in the terminal window while it’s running; otherwise, you’ll have to start the import all over again, which is painful for long-running tasks.
Summary
At this point, you should be comfortable with the concepts of online and offline bulk imports. You’ve seen how each of these techniques operates and have considered their pros and cons. You should also be able to make sensible choices around which of these methods would be appropriate for the knowledge graph that you’re building, including the possibility of using several tools throughout the knowledge graph’s lifecycle.
From here you’re going to move further up the stack and explore how data can be streamed into the knowledge graph to keep it continuously up to date and trigger further processing.
1 Prior to Neo4j 5, neo4j-admin import could only be used to create an initial knowledge graph for the system. That constraint has been subsequently relaxed to allow multiple offline imports throughout the system lifecycle.
Get Building Knowledge Graphs now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

