9 ENSEMBLE FEATURE SELECTION
9.1 PRELIMINARIES
9.1.1 Right and Wrong Protocols
It is important that feature selection experiments are “clean,” an issue that has been often overlooked [370]. In this context, “clean” means that the testing data which evaluates the quality of a classifier and a feature subset must not have been seen at any point during the training. This concern is valid for any feature selection protocol, ensemble based and nonensemble based alike. A typical example of a wrong protocol is shown in Figure 9.1. Suppose that we are interested in evaluating a ranking method R using a labeled data set Z, and the parameter that needs tuning is the number of selected features d out of n. The steps in the protocol shown in the figure are as follows:
- Carry out a cross-validation on Z. Train a ranker on the training part of the ith fold, and estimate the number of features di on the testing part of the fold. Average the results to find one final recommended value of d.
- By this point, the parameter d is tuned, and can be applied to the whole data set to find an optimal feature subset S. The ranker is applied to Z, and the top d features are retained as S.
- A new cross-validation on Z is carried out to evaluate the testing error of classifier C using only subset S.
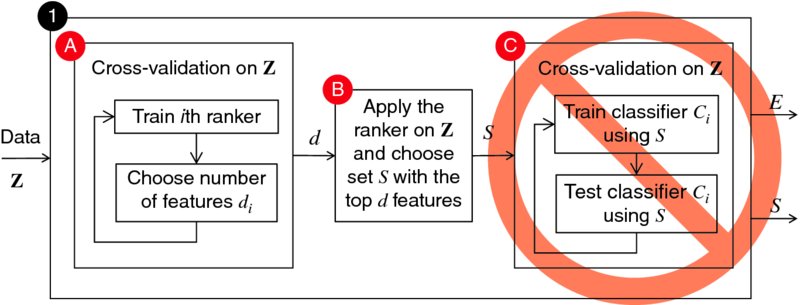
FIGURE 9.1 Incorrect but often used protocol for feature selection and classification.
The misconception ...
Get Combining Pattern Classifiers: Methods and Algorithms, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

