JOINS REVISITED
The data in RDBMSs reside in tables which are linked via parent-child relationships, and the number of such links grows as the data model is taken through the normalization process.
Usually, the tables from which data are fetched (the source tables) are linked, or joined, in order to produce related data. In one of the tables, say, table BOOKS from our Library database, every row must have a unique key value (every row must be uniquely identified); in another table, LOCATION, there is a column where the keys from table BOOKS are stored. This column is said to contain the foreign keys for table BOOKS.
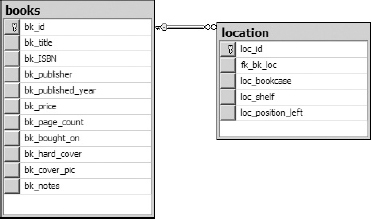
FIGURE 7-1
The diagram in Figure 7-1 is further explored in Figure 7-2, where it presents actual values, and the lines point out the relationship between the tables (because no orphaned records are allowed, every row in the table LOCATION will have a corresponding row in the table BOOKS. The reverse is not true, however, parent tables can have rows without corresponding rows in the child table. According to the best practices rule, each table also has a primary key: BK_ID and LOC_ID respectively. Table LOCATION also has foreign key: FK_BK_LOC.
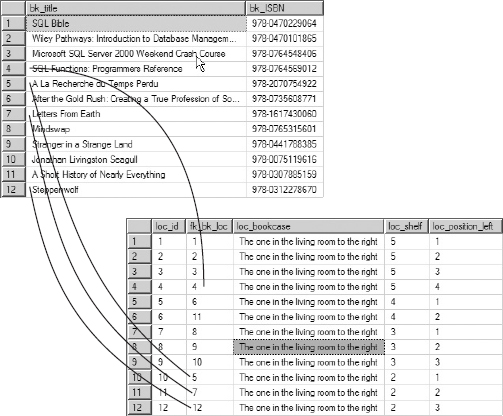
FIGURE 7-2
In the preceding example shown in Figure 7-2, the relation is established through BK_ID (the primary key) and FK_BK_LOC ...
Get Discovering SQL: A Hands-On Guide for Beginners now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

