... xargs -n1 wget
Processing HTML with HTML-XML-utils
If you know some HTML and CSS, you can parse the HTML source of web pages from the command line. It’s sometimes more efficient than copying and pasting chunks of a web page from a browser window by hand. A handy suite of tools for this purpose is HTML-XML-utils, which is available in many Linux distros and from the World Wide Web Consortium. A general recipe is:
-
Use
curl(orwget) to capture the HTML source. -
Use
hxnormalizeto help ensure that the HTML is well-formed. -
Identify CSS selectors for the values you want to capture.
-
Use
hxselectto isolate the values, and pipe the output to further commands for processing.
Let’s extend the example from “Building an Area Code Database” to grab area code data from the web and produce the areacodes.txt file used in that example. For your convenience, I’ve created an HTML table of area codes for you to download and process, shown in Figure 10-1.
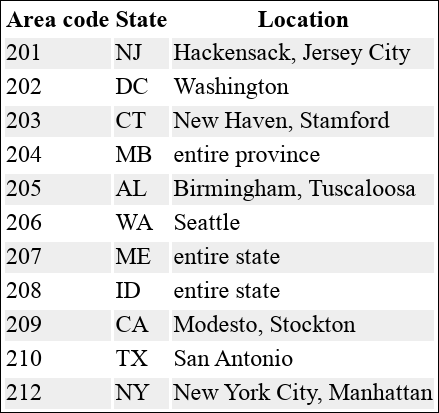
Figure 10-1. A table of area codes at https://efficientlinux.com/areacodes.html
First, grab the HTML source with curl, using the -s option to suppress
on-screen messages. Pipe the output to
hxnormalize -x to clean it up a bit. Pipe it to less to view the
output one screenful at a time:
$ curl -s https://efficientlinux.com/areacodes.html \ | hxnormalize -x \ | less <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> ...
Get Efficient Linux at the Command Line now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

