Kapitel 1. Fehlerbehandlung
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Die Fehlerbehandlung ist ein wichtiger Bestandteil beim Schreiben von Software, und wenn sie schlecht gemacht ist, wird die Software schwierig zu erweitern und zu warten. Programmiersprachen wie C++ oder Java bieten "Ausnahmen" und "Destruktoren", die die Fehlerbehandlung erleichtern. Solche Mechanismen sind für C nicht von Haus aus vorhanden, und die Literatur über gute Fehlerbehandlung in C ist im Internet weit verstreut.
Dieses Kapitel bietet gesammeltes Wissen über gute Fehlerbehandlung in Form von C-Fehlerbehandlungsmustern und einem laufenden Beispiel, das die Muster anwendet. Die Muster bieten bewährte Entwurfsentscheidungen und erläutern, wann sie anzuwenden sind und welche Konsequenzen sie haben. Für den Programmierer bedeuten diese Muster, dass er nicht mehr so viele feinkörnige Entscheidungen treffen muss. Stattdessen kann er sich auf das Wissen verlassen, das in den Mustern präsentiert wird, und sie als Ausgangspunkt für das Schreiben von gutem Code nutzen.
Abbildung 1-1 zeigt einen Überblick über die in diesem Kapitel behandelten Muster und ihre Beziehungen, und Tabelle 1-1 enthält eine Zusammenfassung der Muster.
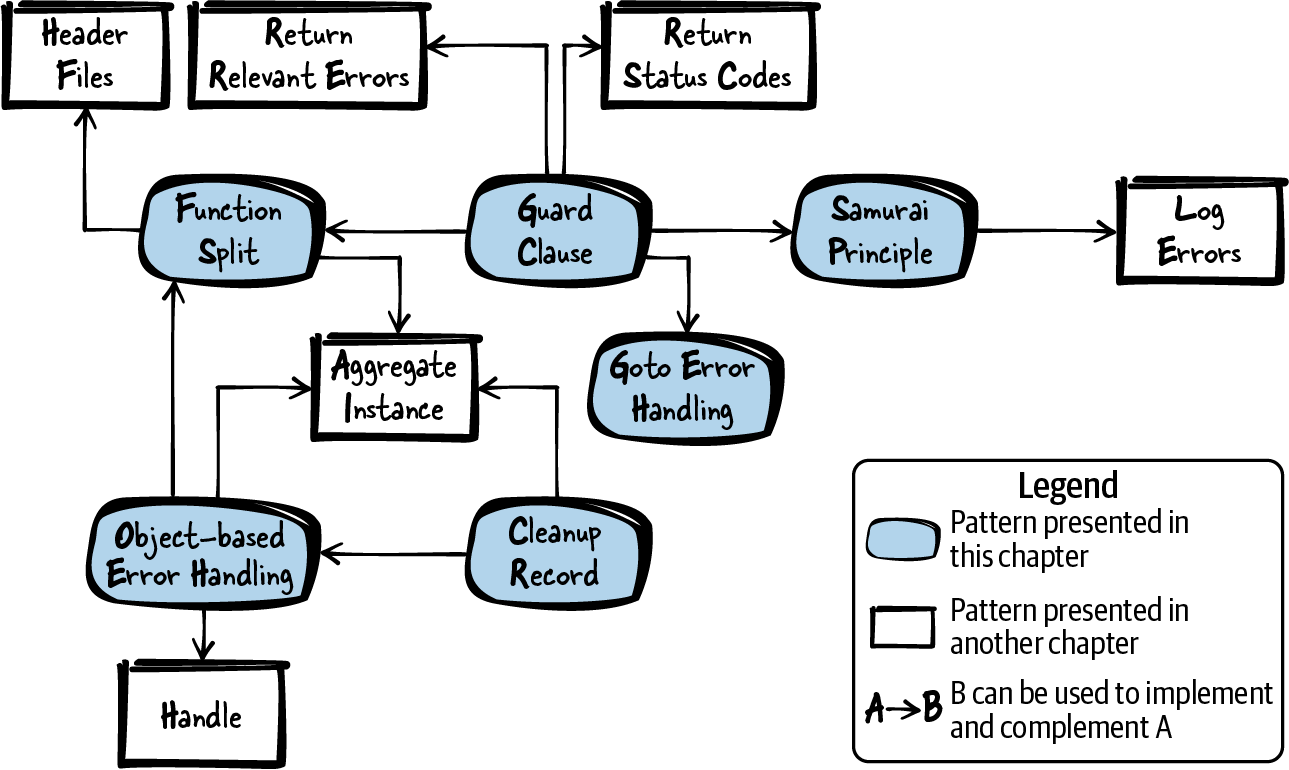
Abbildung 1-1. Übersicht der Muster für die Fehlerbehandlung
Laufendes Beispiel
Du möchtest eine Funktion implementieren, die eine Datei nach bestimmten Schlüsselwörtern durchsucht und Informationen darüber zurückgibt, welche der Schlüsselwörter gefunden wurden.
Die Standardmethode, um eine Fehlersituation in C anzuzeigen, besteht darin, diese Informationen über den Rückgabewert einer Funktion bereitzustellen. Um zusätzliche Fehlerinformationen bereitzustellen, setzen ältere C-Funktionen oft die Variable errno (siehe errno.h) auf einen bestimmten Fehlercode. Der Aufrufer kann dann errno überprüfen, um Informationen über den Fehler zu erhalten.
Im folgenden Code verwendest du jedoch einfach Rückgabewerte anstelle von errno, weil du keine sehr detaillierten Fehlerinformationen brauchst. Du kommst zu folgendem Anfangsstück Code:
intparseFile(char*file_name){intreturn_value=ERROR;FILE*file_pointer=0;char*buffer=0;if(file_name!=NULL){if(file_pointer=fopen(file_name,"r")){if(buffer=malloc(BUFFER_SIZE)){/* parse file content*/return_value=NO_KEYWORD_FOUND;while(fgets(buffer,BUFFER_SIZE,file_pointer)!=NULL){if(strcmp("KEYWORD_ONE\n",buffer)==0){return_value=KEYWORD_ONE_FOUND_FIRST;break;}if(strcmp("KEYWORD_TWO\n",buffer)==0){return_value=KEYWORD_TWO_FOUND_FIRST;break;}}free(buffer);}fclose(file_pointer);}}returnreturn_value;}
Im Code musst du die Rückgabewerte der Funktionsaufrufe überprüfen, um zu wissen, ob ein Fehler aufgetreten ist, sodass du am Ende tief verschachtelte if Anweisungen in deinem Code hast. Daraus ergeben sich die folgenden Probleme:
-
Die Funktion ist lang und vermischt Fehlerbehandlung, Initialisierung, Bereinigung und Funktionscode. Das macht es schwierig, den Code zu pflegen.
-
Der Hauptcode, der die Dateidaten liest und interpretiert, ist tief in die
ifKlauseln verschachtelt, was es schwierig macht, der Programmlogik zu folgen. -
Die Aufräumfunktionen sind weit von ihren Initialisierungsfunktionen entfernt, so dass es leicht passieren kann, dass einige Aufräumarbeiten vergessen werden. Das gilt besonders dann, wenn die Funktion mehrere Rückgabeanweisungen enthält.
Um die Sache besser zu machen, führst du zunächst einen Funktionssplit durch.
Funktion geteilt
Problem
Die Funktion hat mehrere Zuständigkeiten, was es schwer macht, die Funktion zu lesen und zu pflegen.
Eine solche Funktion könnte für die Zuweisung von Ressourcen, die Bearbeitung dieser Ressourcen und die Bereinigung dieser Ressourcen zuständig sein. Vielleicht ist die Bereinigung sogar über die Funktion verstreut und wird an einigen Stellen dupliziert. Vor allem die Fehlerbehandlung bei fehlgeschlagener Ressourcenzuweisung macht eine solche Funktion schwer lesbar, denn das endet oft in verschachtelten if Anweisungen.
Bei der Zuweisung, Bereinigung und Verwendung mehrerer Ressourcen in einer Funktion kann es leicht passieren, dass die Bereinigung einer Ressource vergessen wird, vor allem wenn der Code später geändert wird. Wenn zum Beispiel in der Mitte des Codes eine Return-Anweisung hinzugefügt wird, kann man leicht vergessen, die Ressourcen zu bereinigen, die an dieser Stelle in der Funktion bereits zugewiesen wurden.
Lösung
Teile es auf. Nimm einen Teil einer Funktion, der dir für sich genommen nützlich erscheint, erstelle damit eine neue Funktion und rufe diese Funktion auf.
Um herauszufinden, welcher Teil der Funktion isoliert werden soll, überprüfe einfach, ob du ihm einen eigenen aussagekräftigen Namen geben kannst und ob der Split die Verantwortlichkeiten isoliert. Das könnte zum Beispiel dazu führen, dass eine Funktion nur Funktionscode und eine andere nur Fehlerbehandlungscode enthält.
Ein guter Indikator dafür, dass eine Funktion aufgeteilt werden sollte, ist, wenn sie die Bereinigung derselben Ressource an mehreren Stellen in der Funktion enthält. In einem solchen Fall ist es viel besser, den Code in eine Funktion aufzuteilen, die die Ressourcen zuweist und aufräumt, und in eine Funktion, die diese Ressourcen verwendet. Die aufgerufene Funktion, die die Ressourcen verwendet, kann dann problemlos mehrere Rückgabeanweisungen haben, ohne dass die Ressourcen vor jeder Rückgabeanweisung aufgeräumt werden müssen, denn das wird in der anderen Funktion erledigt. Dies wird im folgenden Code gezeigt:
voidsomeFunction(){char*buffer=malloc(LARGE_SIZE);if(buffer){mainFunctionality(buffer);}free(buffer);}voidmainFunctionality(){// implementation goes here}
Jetzt hast du zwei Funktionen anstelle von einer. Das bedeutet natürlich, dass die aufrufende Funktion nicht mehr in sich geschlossen ist und von der anderen Funktion abhängt. Du musst festlegen, wo diese andere Funktion stehen soll. Der erste Schritt ist, sie direkt in dieselbe Datei wie die aufrufende Funktion zu packen. Wenn die beiden Funktionen aber nicht eng miteinander verbunden sind, kannst du in Erwägung ziehen, die aufgerufene Funktion in eine separate Implementierungsdatei zu packen und eine Header-Datei-Deklaration für diese Funktion einzufügen.
Konsequenzen
Du hast den Code verbessert, weil zwei kurze Funktionen im Vergleich zu einer langen Funktion einfacher zu lesen und zu pflegen sind. Der Code ist zum Beispiel leichter zu lesen, weil die Aufräumfunktionen näher an den Funktionen liegen, die aufgeräumt werden müssen, und weil sich die Ressourcenzuweisung und die Aufräumarbeiten nicht mit der Hauptprogrammlogik vermischen. Das macht es einfacher, die Hauptprogrammlogik zu pflegen und ihre Funktionalität später zu erweitern.
Die aufgerufene Funktion kann nun problemlos mehrere Rückgabeanweisungen enthalten, da sie sich nicht um die Bereinigung der Ressourcen vor jeder Rückgabeanweisung kümmern muss. Diese Aufräumarbeiten werden von der aufrufenden Funktion an einem einzigen Punkt durchgeführt.
Wenn die aufgerufene Funktion viele Ressourcen verwendet, müssen alle diese Ressourcen auch an die Funktion übergeben werden. Viele Funktionsparameter machen den Code schwer lesbar und ein versehentliches Vertauschen der Reihenfolge der Parameter beim Funktionsaufruf kann zu Programmierfehlern führen. Um das zu vermeiden, kannst du in einem solchen Fall eine Aggregat-Instanz verwenden.
Bekannte Verwendungszwecke
Die folgenden Beispiele zeigen Anwendungen dieses Musters:
-
So gut wie jeder C-Code enthält Teile, die dieses Muster anwenden, und Teile, die dieses Muster nicht anwenden und daher schwer zu warten sind. Laut dem Buch Clean Code: A Handbook of Agile Software Craftsmanship von Robert C. Martin (Prentice Hall, 2008) sollte jede Funktion genau eine Verantwortung haben (Single-Responsibility-Prinzip), und daher sollten Ressourcenhandling und andere Programmlogik immer in verschiedene Funktionen aufgeteilt werden.
-
Dieses Muster wird im Portland Pattern Repository als Function Wrapper bezeichnet.
-
Für die objektorientierte Programmierung beschreibt das Template-Methoden-Muster auch eine Möglichkeit, den Code zu strukturieren, indem es ihn aufspaltet.
-
Die Kriterien dafür, wann und wo die Funktion aufgespalten werden soll, sind in Refactoring beschrieben : Improving the Design of Existing Code von Martin Fowler (Addison-Wesley, 1999) als Extract Method-Muster beschrieben.
-
Das Spiel NetHack wendet dieses Muster in seiner Funktion
read_config_filean, in der Ressourcen behandelt werden und in der die Funktionparse_conf_fileaufgerufen wird, die dann mit den Ressourcen arbeitet. -
Der OpenWrt-Code verwendet dieses Muster an mehreren Stellen für die Pufferbehandlung. Der Code, der für die MD5-Berechnung zuständig ist, weist zum Beispiel einen Puffer zu, übergibt diesen Puffer an eine andere Funktion, die mit diesem Puffer arbeitet, undräumt den Puffer dann auf.
Angewandt auf das laufende Beispiel
Dein Code sieht schon viel besser aus. Anstelle einer großen Funktion hast du jetzt zwei große Funktionen mit unterschiedlichen Aufgaben. Eine Funktion ist für das Abrufen und Freigeben von Ressourcen zuständig, die andere für die Suche nach den Schlüsselwörtern, wie im folgenden Code gezeigt:
intsearchFileForKeywords(char*buffer,FILE*file_pointer){while(fgets(buffer,BUFFER_SIZE,file_pointer)!=NULL){if(strcmp("KEYWORD_ONE\n",buffer)==0){returnKEYWORD_ONE_FOUND_FIRST;}if(strcmp("KEYWORD_TWO\n",buffer)==0){returnKEYWORD_TWO_FOUND_FIRST;}}returnNO_KEYWORD_FOUND;}intparseFile(char*file_name){intreturn_value=ERROR;FILE*file_pointer=0;char*buffer=0;if(file_name!=NULL){if(file_pointer=fopen(file_name,"r")){if(buffer=malloc(BUFFER_SIZE)){return_value=searchFileForKeywords(buffer,file_pointer);free(buffer);}fclose(file_pointer);}}returnreturn_value;}
Die Tiefe der if Kaskade hat sich verringert, aber die Funktion parseFile enthält immer noch drei if Anweisungen, die auf Fehler bei der Ressourcenzuweisung prüfen, was viel zu viel ist. Du kannst diese Funktion sauberer machen, indem du eine Guard Clause implementierst.
Schutzklausel
Problem
Die Funktion ist schwer zu lesen und zu pflegen, weil sie Vorbedingungsprüfungen mit der Hauptprogrammlogik der Funktion vermischt.
Die Zuweisung von Ressourcen erfordert immer deren Bereinigung. Wenn du eine Ressource zuteilst und später feststellst, dass eine andere Bedingung der Funktion nicht erfüllt wurde, muss auch diese Ressource bereinigt werden.
Es ist schwierig, dem Programmfluss zu folgen, wenn mehrere Vorbedingungsprüfungen über die Funktion verstreut sind, insbesondere wenn diese Prüfungen in verschachtelten if Anweisungen implementiert sind. Wenn es viele solcher Überprüfungen gibt, wird die Funktion sehr lang, was an sich schon ein Codegeruch ist.
Code Geruch
Ein Code "riecht", wenn er schlecht strukturiert oder so programmiert ist, dass der Code schwer zu warten ist. Beispiele für Code Smells sind sehr lange Funktionen oder doppelter Code. Weitere Beispiele für Code Smells und Gegenmaßnahmen werden in dem Buch Refactoring behandelt : Improving the Design of Existing Code von Martin Fowler (Addison-Wesley, 1999).
Lösung
Prüfe, ob es zwingende Vorbedingungen gibt und verlasse die Funktion sofort, wenn diese Vorbedingungen nicht erfüllt sind.
Überprüfe zum Beispiel die Gültigkeit der Eingabeparameter oder prüfe, ob sich das Programm in einem Zustand befindet, der die Ausführung des Restes der Funktion erlaubt. Überlege dir genau, welche Art von Vorbedingungen du für den Aufruf deiner Funktion festlegen willst. Einerseits macht es dir das Leben leichter, wenn du sehr streng bist, was du als Funktionseingabe zulässt, aber andererseits würde es dem Aufrufer deiner Funktion das Leben leichter machen, wenn du hinsichtlich der möglichen Eingaben liberaler wärst (wie es das Postelsche Gesetz beschreibt: "Sei konservativ in dem, was du tust, sei liberal in dem, was du von anderen akzeptierst").
Wenn du viele Vorbedingungsprüfungen hast, kannst du eine separate Funktion für die Durchführung dieser Prüfungen aufrufen. Führe die Prüfungen auf jeden Fall durch, bevor du Ressourcen zugewiesen hast, denn dann ist es sehr einfach, aus einer Funktion zurückzukehren, da keine Ressourcen aufgeräumt werden müssen.
Beschreibe die Vorbedingungen für deine Funktion klar und deutlich in der Schnittstelle der Funktion. Der beste Ort, um dieses Verhalten zu dokumentieren, ist die Header-Datei, in der die Funktion deklariert wird.
Wenn es für den Aufrufer wichtig ist, zu wissen, welche Vorbedingung nicht erfüllt wurde, kannst du dem Aufrufer Fehlerinformationen geben. Du kannst zum Beispiel Statuscodes zurückgeben, aber achte darauf, dass du nur relevante Fehler zurückgibst. Der folgende Code zeigt ein Beispiel ohne Rückgabe von Fehlerinformationen:
someFile.h
/* This function operates on the 'user_input', which must not be NULL */voidsomeFunction(char*user_input);
someFile.c
voidsomeFunction(char*user_input){if(user_input==NULL){return;}operateOnData(user_input);}
Konsequenzen
Die sofortige Rückkehr, wenn die Vorbedingungen nicht erfüllt sind, macht den Code im Vergleich zu verschachtelten if Konstrukten einfacher zu lesen. Im Code wird sehr deutlich gemacht, dass die Ausführung der Funktion nicht fortgesetzt wird, wenn die Vorbedingungen nicht erfüllt sind. Dadurch werden die Vorbedingungen sehr gut vom Rest des Codes getrennt.
Einige Kodierrichtlinien verbieten es jedoch, in der Mitte einer Funktion zurückzukehren. Bei Code, der formal bewiesen werden muss, sind Return-Anweisungen zum Beispiel normalerweise nur am Ende der Funktion erlaubt. In einem solchen Fall kann ein Cleanup Record aufbewahrt werden, der auch die bessere Wahl ist, wenn du einen zentralen Ort für die Fehlerbehandlung haben willst.
Bekannte Verwendungszwecke
Die folgenden Beispiele zeigen Anwendungen dieses Musters:
-
Die Guard Clause wird im Portland Pattern Repository beschrieben.
-
Der Artikel "Error Detection" von Klaus Renzel (Proceedings of the 2nd EuroPLoP conference, 1997) beschreibt ein sehr ähnliches Fehlererkennungsmuster, das die Einführung von Vor- und Nachbedingungsprüfungen vorschlägt.
-
Das Spiel NetHack verwendet dieses Muster an mehreren Stellen in seinem Code, zum Beispiel in der Funktion
placebc. Diese Funktion legt dem NetHack-Helden eine Kette an, die seine Bewegungsgeschwindigkeit zur Strafe verringert. Die Funktion kehrt sofort zurück, wenn keine Kettenobjekte vorhanden sind. -
Der OpenSSL-Code verwendet dieses Muster. Zum Beispiel kehrt die Funktion
SSL_newsofort zurück, wenn die Eingabeparameter ungültig sind. -
Der Wireshark-Code
capture_stats, der für das Sammeln von Statistiken beim Schnüffeln von Netzwerkpaketen zuständig ist, prüft zunächst seine Eingabeparameter auf Gültigkeit und kehrt im Falle ungültiger Parameter sofort zurück.
Angewandt auf das laufende Beispiel
Der folgende Code zeigt, wie die Funktion parseFile eine Guard Clause anwendet, um die Vorbedingungen der Funktion zu überprüfen:
intparseFile(char*file_name){intreturn_value=ERROR;FILE*file_pointer=0;char*buffer=0;if(file_name==NULL){returnERROR;}if(file_pointer=fopen(file_name,"r")){if(buffer=malloc(BUFFER_SIZE)){return_value=searchFileForKeywords(buffer,file_pointer);free(buffer);}fclose(file_pointer);}returnreturn_value;}

Wenn ungültige Parameter übergeben werden, kehren wir sofort zurück und es ist keine Bereinigung erforderlich, da noch keine Ressourcen erworben wurden.
Der Code liefert Statuscodes zur Umsetzung der Guard Clause. Er gibt die Konstante ERROR im speziellen Fall eines NULL Parameters zurück. Der Aufrufer könnte nun den Rückgabewert überprüfen, um zu erfahren, ob ein ungültiger NULL Parameter an die Funktion übergeben wurde. Aber ein solcher ungültiger Parameter deutet in der Regel auf einen Programmierfehler hin, und es ist keine gute Idee, nach Programmierfehlern zu suchen und diese Information im Code weiterzugeben. In einem solchen Fall ist es einfacher, einfach das Samurai-Prinzip anzuwenden.
Das Samurai-Prinzip
Problem
Wenn Fehlerinformationen zurückgibt, gehst du davon aus, dass der Aufrufer nach diesen Informationen sucht. Der Aufrufer kann diese Prüfung aber auch einfach weglassen und der Fehler bleibt möglicherweise unbemerkt.
In C ist es nicht zwingend erforderlich, die Rückgabewerte der aufgerufenen Funktionen zu prüfen, und dein Aufrufer kann den Rückgabewert einer Funktion einfach ignorieren. Wenn der Fehler, der in deiner Funktion auftritt, schwerwiegend ist und vom Aufrufer nicht elegant behandelt werden kann, willst du nicht, dass dein Aufrufer entscheidet, ob und wie der Fehler behandelt werden soll. Stattdessen möchtest du sicherstellen, dass auf jeden Fall eine Maßnahme ergriffen wird.
Selbst wenn der Aufrufer eine Fehlersituation behandelt, stürzt das Programm oft trotzdem ab oder es tritt ein Fehler auf. Der Fehler kann einfach an anderer Stelle auftauchen - vielleicht irgendwo im Code des Aufrufers, der Fehlersituationen nicht richtig behandelt. In einem solchen Fall verschleiert die Fehlerbehandlung den Fehler, was es viel schwieriger macht, den Fehler zu debuggen, um die Ursache herauszufinden.
Einige Fehler in deinem Code treten vielleicht nur sehr selten auf. Wenn du für solche Situationen Statuscodes zurückgibst und sie im Code des Aufrufers behandelst, wird dieser Code weniger lesbar, weil er von der eigentlichen Programmlogik und dem eigentlichen Zweck des Codes des Aufrufers ablenkt. Der Aufrufer muss möglicherweise viele Codezeilen schreiben, um sehr selten auftretende Situationen zu behandeln.
Die Rückgabe solcher Fehlerinformationen wirft auch das Problem auf, wie die Informationen tatsächlich zurückgegeben werden können. Die Verwendung des Rückgabewerts oder der Out-Parameter der Funktion zur Rückgabe von Fehlerinformationen macht die Funktionssignatur komplizierter und den Code schwieriger zu verstehen. Aus diesem Grund solltest du keine zusätzlichen Parameter für deine Funktion haben, die nur Fehlerinformationen zurückgeben.
Lösung
Komme aus einer Funktion siegreich oder gar nicht zurück (Samurai-Prinzip). Wenn es eine Situation gibt, bei der du weißt, dass ein Fehler nicht behandelt werden kann, dann brich dasProgramm ab.
Verwende nicht die Out-Parameter oder den Rückgabewert, um Fehlerinformationen zurückzugeben. Du hast alle Fehlerinformationen zur Hand, also behandle den Fehler sofort. Wenn ein Fehler auftritt, lass das Programm einfach abstürzen. Breche das Programm auf strukturierte Weise ab, indem du die Anweisung assert verwendest. Außerdem kannst du mit der Anweisung assert Debug-Informationen bereitstellen, wie im folgenden Code gezeigt:
voidsomeFunction(){assert(checkPreconditions()&&"Preconditions are not met");mainFunctionality();}
Dieses Codestück prüft die Bedingung in der Anweisung assert und wenn sie nicht erfüllt ist, wird die Anweisung assert einschließlich der Zeichenkette auf der rechten Seite auf stderr gedruckt und das Programm wird abgebrochen. Es wäre OK, das Programm auf eine weniger strukturierte Weise abzubrechen, indem du nicht auf NULL Zeiger prüfst und auf solche Zeiger zugreifst. Sorge einfach dafür, dass das Programm an der Stelle abbricht, an der der Fehler auftritt.
Oft sind die Guard Clauses gute Kandidaten, um das Programm im Falle eines Fehlers abzubrechen. Wenn du zum Beispiel weißt, dass ein Kodierungsfehler aufgetreten ist (wenn der Aufrufer dir einen NULL Pointer zur Verfügung gestellt hat), brich das Programm ab und protokolliere Debug-Informationen, anstatt dem Aufrufer Fehlerinformationen zurückzugeben. Breche das Programm jedoch nicht bei jeder Art von Fehler ab. Zum Beispiel sollten Laufzeitfehler wie ungültige Benutzereingaben definitiv nicht zu einem Programmabbruch führen.
Der Aufrufer muss sich über das Verhalten deiner Funktion im Klaren sein. Deshalb musst du in der API der Funktion die Fälle dokumentieren, in denen die Funktion das Programm abbricht. Zum Beispiel muss in der Funktionsdokumentation angegeben werden, ob das Programm abstürzt, wenn der Funktion ein NULL Zeiger als Parameter übergeben wird.
Natürlich ist das Samurai-Prinzip nicht für alle Fehler oder alle Anwendungsbereiche geeignet. Du würdest das Programm nicht abstürzen lassen wollen, wenn du eine unerwartete Benutzereingabe bekommst. Im Falle eines Programmierfehlers kann es jedoch sinnvoll sein, schnell fehlzuschlagen und das Programm abstürzen zu lassen. Das macht es für die Programmierer/innen so einfach wie möglich, den Fehler zu finden.
Ein solcher Absturz muss dem Benutzer jedoch nicht unbedingt angezeigt werden. Wenn dein Programm nur ein unkritischer Teil einer größeren Anwendung ist, möchtest du vielleicht trotzdem, dass dein Programm abstürzt. Aber im Kontext der Gesamtanwendung kann dein Programm auch stillschweigend fehlschlagen, um den Rest der Anwendung oder den Benutzer nicht zu stören.
Asserts in Release Executables
Bei der Verwendung von assert Anweisungen kommt die Diskussion auf, ob sie nur in Debug-Executables oder auch in Release-Executables aktiv sein sollen. Assert Anweisungen können deaktiviert werden, indem du das Makro NDEBUG in deinem Code definierst, bevor du assert.h einfügst, oder indem du das Makro direkt in deiner Toolchain definierst.
Ein Hauptargument für die Deaktivierung der assert Anweisungen für Release-Executables ist, dass du Programmierfehler, die asserts verwenden, bereits beim Testen deiner Debug-Executables abfängst, so dass du nicht riskieren musst, Programme aufgrund von asserts in Release-Executables abzubrechen. Ein Hauptargument dafür, die assert Anweisungen auch in Release-Executables aktiv zu haben, ist, dass du sie ohnehin für kritische Fehler verwendest, die nicht elegant behandelt werden können, und solche Fehler sollten niemals unbemerkt bleiben, auch nicht in Release-Executables, die von deinen Kunden verwendet werden.
Konsequenzen
Der Fehler kann nicht unbemerkt bleiben, weil er direkt an der Stelle behandelt wird, an der er auftritt. Der Aufrufer muss nicht mehr auf diesen Fehler prüfen, so dass der Aufrufer-Code einfacher wird. Allerdings kann der Aufrufer jetzt nicht mehr wählen, wie er auf den Fehler reagieren will.
In manchen Fällen ist es in Ordnung, die Anwendung abzubrechen, denn ein schneller Absturz ist besser als ein unvorhersehbares Verhalten zu einem späteren Zeitpunkt. Dennoch musst du dir überlegen, wie ein solcher Fehler dem Benutzer präsentiert werden soll. Vielleicht sieht der Benutzer ihn als Abbruchanweisung auf dem Bildschirm. Bei eingebetteten Anwendungen, die Sensoren und Aktoren verwenden, um mit der Umgebung zu interagieren, musst du jedoch mehr Sorgfalt walten lassen und überlegen, welchen Einfluss ein abbrechendes Programm auf die Umgebung hat und ob dies akzeptabel ist. In vielen solchen Fällen muss die Anwendung robuster sein und ein einfacher Abbruch ist nicht akzeptabel.
Wenn du das Programm an der Stelle abbrichst und Fehler protokollierst, an der der Fehler auftritt, ist es einfacher, den Fehler zu finden und zu beheben, weil er nicht verschleiert wird. Langfristig führt die Anwendung dieses Musters also zu einer robusteren und fehlerfreien Software.
Bekannte Verwendungszwecke
Die folgenden Beispiele zeigen Anwendungen dieses Musters:
-
Ein ähnliches Muster, das das Hinzufügen eines Debug-Informationsstrings zu einer
assertAnweisung vorschlägt, heißt Assertion Context und wird im Buch Patterns in C von Adam Tornhill (Leanpub, 2014) beschrieben. -
Der Wireshark Netzwerk-Sniffer wendet dieses Muster in seinem gesamten Code an. Die Funktion
register_capture_dissectorverwendet zum Beispielassert, um zu prüfen, ob die Registrierung eines Dissektors eindeutig ist. -
Der Quellcode des Git-Projekts verwendet
assertAnweisungen. Die Funktionen zum Speichern von SHA1-Hash-Werten verwenden zum Beispielassert, um zu prüfen, ob der Pfad zu der Datei, in der der Hash-Wert gespeichert werden soll, korrekt ist. -
Der OpenWrt-Code, der für den Umgang mit großen Zahlen zuständig ist, verwendet
assertAnweisungen, um Vorbedingungen in seinen Funktionen zu prüfen. -
Ein ähnliches Muster mit dem Namen Let It Crash wird von Pekka Alho und Jari Rauhamäki in dem Artikel "Patterns for Light-Weight Fault Tolerance and Decoupled Design in Distributed Control Systems" vorgestellt . Das Muster zielt auf verteilte Kontrollsysteme ab und schlägt vor, einzelne fehlschlagsichere Prozesse abstürzen zu lassen und dann schnell wieder zu starten.
-
Die C-Standardbibliotheksfunktion
strcpyprüft nicht auf gültige Benutzereingaben. Wenn du der Funktion einenNULL-Zeiger gibst, stürzt sie ab.
Angewandt auf das laufende Beispiel
Die Funktion parseFile sieht jetzt viel besser aus. Anstatt einen Fehlercode zurückzugeben, hast du jetzt eine einfache assert Anweisung. Dadurch wird der folgende Code kürzer, und der Aufrufer des Codes muss nicht mehr den Rückgabewert überprüfen:
intparseFile(char*file_name){intreturn_value=ERROR;FILE*file_pointer=0;char*buffer=0;assert(file_name!=NULL&&"Invalid filename");if(file_pointer=fopen(file_name,"r")){if(buffer=malloc(BUFFER_SIZE)){return_value=searchFileForKeywords(buffer,file_pointer);free(buffer);}fclose(file_pointer);}returnreturn_value;}
Während die if Anweisungen, die keine Ressourcenbereinigung erfordern, eliminiert werden, enthält der Code immer noch verschachtelte if Anweisungen für alles, was eine Bereinigung erfordert. Außerdem behandelst du noch nicht die Fehlersituation, wenn der Aufruf von malloc fehlschlägt. All dies kann durch die Verwendung von Goto Error Handling verbessert werden.
Gehe zu Fehlerbehandlung
Kontext
Du hast eine Funktion, die mehrere Ressourcen erwirbt und aufräumt. Vielleicht hast du bereits versucht, die Komplexität zu reduzieren, indem du Guard Clause, Function Split oder das Samurai-Prinzip angewendet hast, aber du hast immer noch ein tief verschachteltes if Konstrukt im Code, insbesondere wegen der Ressourcenerfassung. Vielleicht hast du sogar doppelten Code für die Ressourcenbereinigung.
Problem
Code wird schwer zu lesen und zu pflegen, wenn er mehrere Ressourcen an verschiedenen Stellen innerhalb einer Funktion erfasst und bereinigt.
Ein solcher Code wird schwierig, weil in der Regel jeder Ressourcenerwerb fehlschlagen kann und jede Ressourcenbereinigung nur dann aufgerufen werden kann, wenn die Ressource erfolgreich erworben wurde. Um dies zu realisieren, sind viele if Anweisungen erforderlich, und wenn sie schlecht implementiert sind, machen verschachtelte if Anweisungen in einer einzigen Funktion den Code schwer lesbar und wartbar.
Da du die Ressourcen aufräumen musst, ist es keine gute Option, mitten in der Funktion zurückzukehren, wenn etwas schief läuft. Das liegt daran, dass alle bereits erworbenen Ressourcen vor jeder Rückkehranweisung aufgeräumt werden müssen. Du hast also mehrere Stellen im Code, an denen dieselbe Ressource aufgeräumt wird, aber du willst keine doppelte Fehlerbehandlung und keinen doppelten Aufräumcode haben.
Lösung
Alle Ressourcenbereinigungen und Fehlerbehandlungen sollten am Ende der Funktion stehen. Wenn eine Ressource nicht erfasst werden kann, verwende die Anweisung goto, um zum Code für die Ressourcenbereinigung zu springen.
Nimm die Ressourcen in der Reihenfolge ein, in der du sie brauchst, und räume sie am Ende deiner Funktion in umgekehrter Reihenfolge auf. Für die Ressourcenbereinigung solltest du ein eigenes Label haben, zu dem du für jede Bereinigungsfunktion springen kannst. Springe einfach zum Label, wenn ein Fehler auftritt oder eine Ressource nicht erfasst werden kann, aber springe nicht mehrfach, sondern nur vorwärts, wie im folgenden Code geschehen:
voidsomeFunction(){if(!allocateResource1()){gotocleanup1;}if(!allocateResource2()){gotocleanup2;}mainFunctionality();cleanup2:cleanupResource2();cleanup1:cleanupResource1();}
Wenn dein Kodierungsstandard die Verwendung von goto Anweisungen verbietet, kannst du sie mit einer do{ ... }while(0); Schleife um deinen Code emulieren. Bei einem Fehler springst du mit break an das Ende der Schleife, wo du deine Fehlerbehandlung eingefügt hast. Dieser Workaround ist jedoch in der Regel eine schlechte Idee, denn wenn goto in deinem Codierungsstandard nicht erlaubt ist, solltest du ihn auch nicht emulieren, nur um in deinem eigenen Stil weiter zu programmieren. Du könntest einen Cleanup Record als Alternative zu goto verwenden.
In jedem Fall könnte die Verwendung von goto einfach ein Indikator dafür sein, dass deine Funktion bereits zu komplex ist und eine Aufteilung der Funktion, zum Beispiel mit objektbasierter Fehlerbehandlung, eine bessere Idee wäre.
goto: Gut oder böse?
Es gibt viele Diskussionen darüber, ob die Verwendung von goto gut oder schlecht ist. Der berühmteste Artikel gegen die Verwendung von goto stammt von Edsger W. Dijkstra, der argumentiert, dass sie den Programmfluss verschleiert. Das stimmt, wenn goto verwendet wird, um in einem Programm hin und her zu springen, aber goto kann in C nicht so sehr missbraucht werden wie in den Programmiersprachen, über die Dijkstra geschrieben hat. (In C kannst du goto nur verwenden, um innerhalb einer Funktion zu springen.)
Konsequenzen
Die Funktion ist ein einziger Rücksprungpunkt, und der Hauptprogrammfluss ist gut von der Fehlerbehandlung und dem Aufräumen der Ressourcen getrennt. Um dies zu erreichen, sind keine verschachtelten if Anweisungen mehr erforderlich, aber nicht jeder ist es gewohnt und mag es, gotoAnweisungen zu lesen.
Wenn du goto Anweisungen verwendest, musst du vorsichtig sein, denn es ist verlockend, sie für andere Dinge als Fehlerbehandlung und Bereinigung zu verwenden, und das macht den Code definitiv unlesbar. Außerdem musst du besonders darauf achten, dass die richtigen Bereinigungsfunktionen an den richtigen Stellen eingesetzt werden. Es kommt häufig vor, dass Bereinigungsfunktionen versehentlich an der falschen Stelle eingefügt werden.
Bekannte Verwendungszwecke
Die folgenden Beispiele zeigen Anwendungen dieses Musters:
-
Der Linux-Kernel-Code verwendet hauptsächlich die
goto-basierte Fehlerbehandlung. Das Buch Linux Device Drivers von Alessandro Rubini und Jonathan Corbet (O'Reilly, 2001) beschreibt zum Beispiel diegoto-basierte Fehlerbehandlung für die Programmierung von Linux-Gerätetreibern. -
Der CERT C Coding Standard von Robert C. Seacord (Addison-Wesley Professional, 2014) empfiehlt die Verwendung von
gotofür die Fehlerbehandlung. -
Die
gotoEmulation mit einerdo-whileSchleife wird im Portland Pattern Repository als Trivial Do-While-Loop Muster beschrieben. -
Der OpenSSL-Code verwendet die Anweisung
goto. Die Funktionen, die X509-Zertifikate bearbeiten, verwenden zum Beispielgoto, um zu einem zentralen Fehlerhandler weiterzuspringen. -
Der Wireshark-Code verwendet
gotoAnweisungen, um von seinermainFunktion zu einem zentralen Fehlerhandler am Ende dieser Funktion zu springen.
Angewandt auf das laufende Beispiel
Auch wenn einige Leute die Verwendung von goto Anweisungen missbilligen, ist die Fehlerbehandlung im Vergleich zum vorherigen Codebeispiel besser. Im folgenden Code gibt es keine verschachtelten if Anweisungen, und der Bereinigungscode ist gut vom Hauptprogrammfluss getrennt:
intparseFile(char*file_name){intreturn_value=ERROR;FILE*file_pointer=0;char*buffer=0;assert(file_name!=NULL&&"Invalid filename");if(!(file_pointer=fopen(file_name,"r"))){gotoerror_fileopen;}if(!(buffer=malloc(BUFFER_SIZE))){gotoerror_malloc;}return_value=searchFileForKeywords(buffer,file_pointer);free(buffer);error_malloc:fclose(file_pointer);error_fileopen:returnreturn_value;}
Angenommen, du magst keine goto Anweisungen oder deine Kodierrichtlinien verbieten sie, aber du musst trotzdem deine Ressourcen aufräumen. Es gibt Alternativen. Du kannst z. B. stattdessen einfach einen Cleanup Record haben.
Aufräumaktion
Kontext
Du hast eine Funktion, die mehrere Ressourcen erwirbt und aufräumt. Vielleicht hast du bereits versucht, die Komplexität zu reduzieren, indem du Guard Clause, Function Split oder das Samurai-Prinzip angewendet hast, aber du hast immer noch ein tief verschachteltes if Konstrukt im Code, wegen der Ressourcenerfassung. Vielleicht hast du sogar doppelten Code für die Ressourcenbereinigung. Deine Coding-Standards erlauben es dir nicht, Goto Error Handling zu implementieren, oder du willst goto nicht verwenden.
Problem
Es ist schwierig, einen Code einfach zu lesen und zu pflegen, wenn dieser Code mehrere Ressourcen erfasst und aufräumt, vor allem wenn diese Ressourcen voneinander abhängen.
Das ist schwierig, weil in der Regel jeder Ressourcenerwerb fehlschlagen kann und jede Ressourcenbereinigung nur aufgerufen werden kann, wenn die Ressource erfolgreich erworben wurde. Um dies umzusetzen, sind viele if Anweisungen erforderlich, und wenn sie schlecht implementiert sind, machen verschachtelte if Anweisungen in einer einzigen Funktion den Code schwer lesbar und wartbar.
Da du die Ressourcen aufräumen musst, ist es keine gute Option, mitten in der Funktion zurückzukehren, wenn etwas schief läuft. Das liegt daran, dass alle bereits erworbenen Ressourcen vor jeder Rückkehranweisung aufgeräumt werden müssen. Du hast also mehrere Stellen im Code, an denen dieselbe Ressource aufgeräumt wird, aber du willst keine doppelte Fehlerbehandlung und keinen doppelten Aufräumcode haben.
Lösung
Rufe die Funktionen zur Ressourcenerfassung auf, solange sie erfolgreich sind, und speichere, welche Funktionen bereinigt werden müssen. Rufe die Aufräumfunktionen in Abhängigkeit von diesen gespeichertenWerten auf.
In C kann die faule Auswertung von if Anweisungen verwendet werden, um dies zu erreichen. Rufe einfach eine Reihe von Funktionen innerhalb einer einzigen if Anweisung auf, solange diese Funktionen erfolgreich sind. Für jeden Funktionsaufruf speicherst du die gewonnene Ressource in einer Variablen. Lass den Code, der auf die Ressourcen wirkt, im Hauptteil der if Anweisung stehen und bereinige alle Ressourcen nach der if Anweisung nur, wenn die Ressource erfolgreich erworben wurde. Der folgende Code zeigt ein Beispiel dafür:
voidsomeFunction(){if((r1=allocateResource1())&&(r2=allocateResource2())){mainFunctionality();}if(r1){cleanupResource1();}if(r2){cleanupResource2();}}
Um den Code leichter lesbar zu machen, kannst du diese Prüfungen alternativ in die Aufräumfunktionen einbauen. Das ist ein guter Ansatz, wenn du die Ressourcenvariable ohnehin an die Aufräumfunktion übergeben musst.
Konsequenzen
Du hast jetzt keine verschachtelten if Anweisungen mehr, und du hast immer noch einen zentralen Punkt am Ende der Funktion für die Ressourcenbereinigung. Das macht den Code viel einfacher zu lesen, weil der Hauptprogrammfluss nicht mehr durch die Fehlerbehandlung verdeckt wird.
Außerdem ist die Funktion leicht zu lesen, weil sie einen einzigen Exit-Punkt hat. Die Tatsache, dass du viele Variablen haben musst, um zu verfolgen, welche Ressourcen erfolgreich zugewiesen wurden, macht den Code jedoch komplizierter. Vielleicht kann eine Aggregate Instance helfen, die Ressourcenvariablen zu strukturieren.
Wenn viele Ressourcen erworben werden, werden viele Funktionen in einer einzigen if Anweisung aufgerufen. Das macht die if Anweisung sehr schwer zu lesen und noch schwerer zu debuggen. Wenn viele Ressourcen erfasst werden, ist eine objektbasierte Fehlerbehandlung daher eine viel bessere Lösung.
Ein weiterer Grund, der für eine objektbasierte Fehlerbehandlung spricht, ist, dass der vorangegangene Code immer noch kompliziert ist, weil er eine einzige Funktion enthält, die sowohl die Hauptfunktionalität als auch die Ressourcenzuweisung und die Bereinigung beinhaltet. Eine Funktion hat also mehrere Aufgaben.
Bekannte Verwendungszwecke
Die folgenden Beispiele zeigen Anwendungen dieses Musters:
-
Im Portland Pattern Repository wird eine ähnliche Lösung vorgestellt, bei der jede der aufgerufenen Funktionen einen Cleanup-Handler in einer Callback-Liste registriert. Zum Aufräumen werden alle Funktionen aus der Callback-Liste aufgerufen.
-
Die OpenSSL-Funktion
dh_key2bufnutzt die "Lazy Evaluation" in einerif-Anweisung, um die zugewiesenen Bytes zu verfolgen, die dann später aufgeräumt werden. -
Die Funktion
cap_open_socketdes Wireshark-Netzwerk-Sniffers nutzt die faule Auswertung einerif-Anweisung und speichert die in dieserif-Anweisung zugewiesenen Ressourcen in Variablen. Beim Aufräumen werden diese Variablen dann überprüft, und wenn die Ressourcenzuweisung erfolgreich war, wird die Ressource aufgeräumt. -
Die Funktion
nvram_commitdes OpenWrt-Quellcodes weist ihre Ressourcen innerhalb einerif-Anweisung zu und speichert diese Ressourcen in einer Variablen direkt innerhalb dieserif-Anweisung.
Angewandt auf das laufende Beispiel
Statt von goto Anweisungen und verschachtelten if Anweisungen, hast du jetzt eine einzige if Anweisung. Der Vorteil des Verzichts auf goto Anweisungen im folgenden Code ist, dass die Fehlerbehandlung gut vom Hauptprogrammfluss getrennt ist:
intparseFile(char*file_name){intreturn_value=ERROR;FILE*file_pointer=0;char*buffer=0;assert(file_name!=NULL&&"Invalid filename");if((file_pointer=fopen(file_name,"r"))&&(buffer=malloc(BUFFER_SIZE))){return_value=searchFileForKeywords(buffer,file_pointer);}if(file_pointer){fclose(file_pointer);}if(buffer){free(buffer);}returnreturn_value;}
Trotzdem sieht der Code nicht schön aus. Diese eine Funktion hat viele Aufgaben: Ressourcenzuweisung, Ressourcendeallokation, Dateibehandlung und Fehlerbehandlung. Diese Aufgaben sollten in verschiedene Funktionen mit objektbasierterFehlerbehandlung aufgeteilt werden.
Objektbasierte Fehlerbehandlung
Kontext
Du hast eine Funktion, die mehrere Ressourcen erwirbt und aufräumt. Vielleicht hast du bereits versucht, die Komplexität zu reduzieren, indem du Guard Clause, Function Split oder das Samurai-Prinzip angewendet hast, aber du hast immer noch ein tief verschachteltes if Konstrukt im Code, wegen der Ressourcenerfassung. Vielleicht hast du sogar doppelten Code für die Ressourcenbereinigung. Aber vielleicht hast du die verschachtelten if Anweisungen bereits durch die Verwendung von Goto Error Handling oder einem Cleanup Record beseitigt.
Problem
Wenn eine Funktion für mehrere Aufgaben zuständig ist, z. B. für die Beschaffung von Ressourcen, die Bereinigung von Ressourcen und die Nutzung dieser Ressourcen, ist der Code schwer zu implementieren, zu lesen, zu warten und zu testen.
All das wird schwierig, weil normalerweise jeder Ressourcenerwerb fehlschlagen kann und jede Ressourcenbereinigung nur dann aufgerufen werden kann, wenn die Ressource erfolgreich erworben wurde. Um dies zu realisieren, sind eine Menge if Anweisungen erforderlich, und wenn sie schlecht implementiert sind, machen verschachtelte if Anweisungen in einer einzigen Funktion den Code schwer lesbar und wartbar.
Da du die Ressourcen aufräumen musst, ist es keine gute Option, mitten in der Funktion zurückzukehren, wenn etwas schief läuft. Das liegt daran, dass alle bereits erworbenen Ressourcen vor jeder Rückkehranweisung aufgeräumt werden müssen. Du hast also mehrere Stellen im Code, an denen dieselbe Ressource aufgeräumt wird, aber du willst keine doppelte Fehlerbehandlung und keinen doppelten Aufräumcode haben.
Auch wenn du bereits einen Cleanup Record oder Goto Error Handling hast, ist die Funktion immer noch schwer zu lesen, weil sie verschiedene Verantwortlichkeiten vermischt. Die Funktion ist für die Erfassung mehrerer Ressourcen, die Fehlerbehandlung und die Bereinigung mehrerer Ressourcen zuständig. Eine Funktion sollte aber nur eine Aufgabe haben.
Lösung
Lege die Initialisierung und die Bereinigung in separate Funktionen, ähnlich dem Konzept der Konstruktoren und Destruktoren in der objektorientierten Programmierung.
In deiner Hauptfunktion rufst du einfach eine Funktion auf, die alle Ressourcen beschafft, eine Funktion, die mit diesen Ressourcen arbeitet, und eine Funktion, die die Ressourcen aufräumt.
Wenn die erworbenen Ressourcen nicht global sind, musst du die Ressourcen an die Funktionen weitergeben. Wenn du mehrere Ressourcen hast, kannst du eine Aggregat-Instanz mit allen Ressourcen an die Funktionen weitergeben. Wenn du die tatsächlichen Ressourcen vor dem Aufrufer verbergen möchtest, kannst du ein Handle für die Weitergabe der Ressourceninformationen zwischen den Funktionen verwenden.
Wenn die Ressourcenzuweisung fehlschlägt, speichere diese Information in einer Variablen (z. B. einem NULL -Zeiger, wenn die Speicherzuweisung fehlschlägt). Wenn du die Ressourcen verwendest oder aufräumst, prüfe zuerst, ob die Ressource gültig ist. Führe diese Prüfung nicht in deiner Hauptfunktion durch, sondern in den aufgerufenen Funktionen, denn das macht deine Hauptfunktion viel lesbarer:
voidsomeFunction(){allocateResources();mainFunctionality();cleanupResources();}
Konsequenzen
Die Funktion ist jetzt einfach zu lesen. Obwohl sie die Zuweisung und Bereinigung mehrerer Ressourcen sowie die Operationen mit diesen Ressourcen erfordert, sind diese verschiedenen Aufgaben immer noch gut in verschiedene Funktionen aufgeteilt.
Objektähnliche Instanzen, an die du Funktionen weitergibst, werden als "objektbasierter" Programmierstil bezeichnet. Durch diesen Stil wird die prozedurale Programmierung der objektorientierten Programmierung ähnlicher und daher ist der in diesem Stil geschriebene Code auch Programmierern, die an die Objektorientierung gewöhnt sind, vertrauter.
In der Hauptfunktion gibt es keinen Grund mehr für mehrere Return-Anweisungen, weil es keine verschachtelten if Anweisungen für die Logik der Ressourcenzuweisung und der Bereinigung mehr gibt. Die Logik für die Ressourcenzuweisung und das Aufräumen hast du natürlich nicht eliminiert. Diese Logik ist immer noch in den getrennten Funktionen vorhanden, aber sie ist nicht mehr mit der Operation an den Ressourcen vermischt.
Anstatt einer einzigen Funktion hast du jetzt mehrere Funktionen. Das kann sich zwar negativ auf die Leistung auswirken, spielt aber normalerweise keine große Rolle. Die Auswirkungen auf die Leistung sind gering und für die meisten Anwendungen nicht relevant.
Bekannte Verwendungszwecke
Die folgenden Beispiele zeigen Anwendungen dieses Musters:
-
Diese Form der Bereinigung wird in der objektorientierten Programmierung verwendet, wo Konstruktoren und Destruktoren implizit aufgerufen werden.
-
Der OpenSSL-Code nutzt dieses Muster. Die Zuweisung und Bereinigung von Puffern wird zum Beispiel mit den Funktionen
BUF_MEM_newundBUF_MEM_freerealisiert, die im gesamten Code aufgerufen werden, um die Pufferbehandlung abzudecken. -
Die Funktion
show_helpdes OpenWrt-Quellcodes zeigt Hilfeinformationen in einem Kontextmenü an. Die Funktion ruft eine Initialisierungsfunktion auf, um einestructzu erstellen, arbeitet dann mit dieserstructund ruft eine Funktion auf, um diesestructaufzuräumen. -
Die Funktion
cmd__windows_named_pipedes Git-Projekts verwendet ein Handle, um eine Pipe zu erstellen, arbeitet dann mit dieser Pipe und ruft eine separate Funktion auf, um die Pipe aufzuräumen.
Angewandt auf das laufende Beispiel
Unter findest du schließlich den folgenden Code, in dem die Funktion parseFile andere Funktionen aufruft, um eine Parser-Instanz zu erstellen und aufzuräumen:
typedefstruct{FILE*file_pointer;char*buffer;}FileParser;intparseFile(char*file_name){intreturn_value;FileParser*parser=createParser(file_name);return_value=searchFileForKeywords(parser);cleanupParser(parser);returnreturn_value;}intsearchFileForKeywords(FileParser*parser){if(parser==NULL){returnERROR;}while(fgets(parser->buffer,BUFFER_SIZE,parser->file_pointer)!=NULL){if(strcmp("KEYWORD_ONE\n",parser->buffer)==0){returnKEYWORD_ONE_FOUND_FIRST;}if(strcmp("KEYWORD_TWO\n",parser->buffer)==0){returnKEYWORD_TWO_FOUND_FIRST;}}returnNO_KEYWORD_FOUND;}FileParser*createParser(char*file_name){assert(file_name!=NULL&&"Invalid filename");FileParser*parser=malloc(sizeof(FileParser));if(parser){parser->file_pointer=fopen(file_name,"r");parser->buffer=malloc(BUFFER_SIZE);if(!parser->file_pointer||!parser->buffer){cleanupParser(parser);returnNULL;}}returnparser;}voidcleanupParser(FileParser*parser){if(parser){if(parser->buffer){free(parser->buffer);}if(parser->file_pointer){fclose(parser->file_pointer);}free(parser);}}
Im Code gibt es keine if Kaskade mehr im Hauptprogrammfluss. Dadurch ist die Funktion parseFile viel einfacher zu lesen, zu debuggen und zu warten. Die Hauptfunktion kümmert sich nicht mehr um die Ressourcenzuweisung, die Ressourcendeallokation oder die Details der Fehlerbehandlung. Stattdessen sind diese Details in separaten Funktionen untergebracht, so dass jede Funktion nur eine Aufgabe hat.
Sieh dir an, wie schön dieses letzte Codebeispiel im Vergleich zum ersten Codebeispiel ist. Die angewandten Muster haben Schritt für Schritt dazu beigetragen, dass der Code leichter zu lesen und zu pflegen ist. In jedem Schritt wurde die verschachtelte if Kaskade entfernt und die Methode zur Fehlerbehandlung verbessert.
Zusammenfassung
In diesem Kapitel hast du gelernt, wie du Fehler in C behandelst. Function Split sagt dir, wie du deine Funktionen in kleinere Teile aufteilen kannst, um die Fehlerbehandlung dieser Teile zu vereinfachen. Eine Schutzklausel für deine Funktionen überprüft die Vorbedingungen deiner Funktion und kehrt sofort zurück, wenn sie nicht erfüllt sind. Dadurch müssen weniger Fehlerbehandlungen für den Rest der Funktion durchgeführt werden. Anstatt aus der Funktion zurückzukehren, könntest du das Programm auch abbrechen, um das Samurai-Prinzip zu befolgen. Wenn es um einekomplexere Fehlerbehandlung geht - vor allem in Kombination mit der Beschaffung und Freigabe von Ressourcen - hast du mehrere Möglichkeiten. Goto Error Handling ermöglicht es, in deiner Funktion zu einem Abschnitt mit Fehlerbehandlung zu springen. Anstatt zu springen, speichert Cleanup Record die Information, welche Ressourcen bereinigt werden müssen, und führt sie am Ende der Funktion aus. Eine Methode der Ressourcenerfassung, die näher an der objektorientierten Programmierung ist, ist die objektbasierte Fehlerbehandlung, die getrennte Initialisierungs- und Aufräumfunktionen ähnlich dem Konzept der Konstruktoren und Destruktoren verwendet.
Mit diesen Fehlerbehandlungsmustern in deinem Repertoire hast du jetzt die Fähigkeit, kleine Programme zu schreiben, die Fehlersituationen so behandeln, dass der Code wartbar bleibt.
Weitere Lektüre
Wenn du bereit bist für mehr, findest du hier einige Ressourcen, die dir helfen können, dein Wissen über Fehlerbehandlung zu erweitern.
-
Das Portland Pattern Repository bietet viele Muster und Diskussionen zur Fehlerbehandlung und zu anderen Themen. Die meisten der Fehlerbehandlungsmuster zielen auf die Behandlung von Ausnahmen oder die Verwendung von Assertions ab, aber eswerden auch einige C-Mustervorgestellt.
-
Einen umfassenden Überblick über die Fehlerbehandlung im Allgemeinen bietet die Masterarbeit "Error Handling in Structured and Object-Oriented Programming Languages" von Thomas Aglassinger (University of Oulu, 1999). In dieser Arbeit wird beschrieben, wie verschiedene Arten von Fehlern entstehen; es werden Mechanismen zur Fehlerbehandlung in den Programmiersprachen C, Basic, Java und Eiffel erörtert und bewährte Methoden für die Fehlerbehandlung in diesen Sprachen vorgestellt, z. B. die Umkehrung der Reihenfolge, in der die Ressourcen bereinigt werden, im Vergleich zur Reihenfolge ihrer Zuweisung. In der Arbeit werden auch einige Lösungen von Drittanbietern in Form von C-Bibliotheken erwähnt, die erweiterte Funktionen zur Fehlerbehandlung für C bieten, wie z. B. die Behandlung von Ausnahmen mit den Befehlen
setjmpundlongjmp. -
In dem Artikel "Error Handling for Business Information Systems" von Klaus Renzel werden fünfzehn objektorientierte Muster für die Fehlerbehandlung vorgestellt, die auf Wirtschaftsinformationssysteme zugeschnitten sind. Die meisten der Muster können auch in nicht-objektorientierten Bereichen angewendet werden. Die vorgestellten Muster decken die Bereiche Fehlererkennung, Fehlerprotokollierung und Fehlerbehandlung ab.
-
Im Buch Patterns in C von Adam Tornhill (Leanpub, 2014) werden Implementierungen einschließlich C-Code-Schnipseln für einige Gang of Four-Entwurfsmuster vorgestellt. Das Buch enthält außerdem bewährte Methoden in Form von C-Mustern, von denen einige die Fehlerbehandlung abdecken.
-
Eine Sammlung von Mustern für die Fehlerprotokollierung und Fehlerbehandlung wird in den Artikeln "Patterns for Generation, Handling and Management of Errors" und "More Patterns for the Generation, Handling and Management of Errors" von Andy Longshaw und Eoin Woods vorgestellt. Die meisten Muster zielen auf eine ausnahmebasierte Fehlerbehandlung ab.
Ausblick
Das nächste Kapitel zeigt dir, wie du mit Fehlern umgehst, wenn du größere Programme betrachtest, die Fehlerinformationen über Schnittstellen zu anderen Funktionen zurückgeben. Die Muster sagen dir, welche Art von Fehlerinformationen du zurückgeben sollst und wie du sie zurückgeben kannst.
Get Fließend C now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

