There are many variations to the policy-and model-free algorithms that have become popular for solving RL problems of optimizing predictions of future rewards. As we have seen, many of these algorithms use an advantage function, such as Actor-Critic, where we have two sides of the problem trying to converge to the optimum solution. In this case, the advantage function is trying to find the maximum expected discounted rewards. TRPO and PPO do this by using an optimization method called a Minorize-Maximization (MM) algorithm. An example of how the MM algorithm solves a problem is shown in the following diagram:
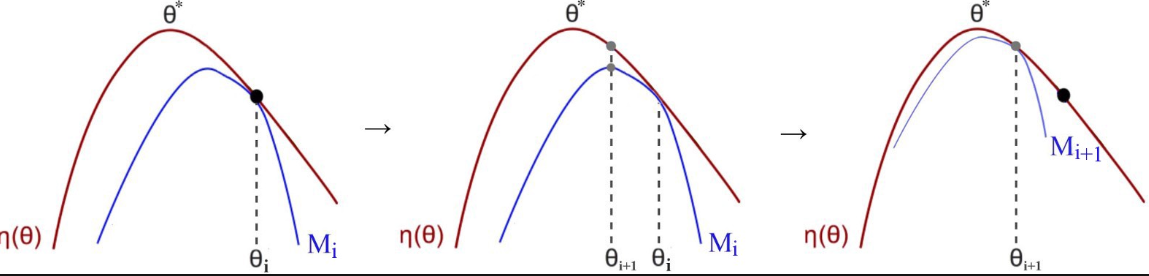 Using ...
Using ...
