Chapter 4. Common Problems
While caching is a great approach to addressing scale and performance, it comes with its own unique set of issues that could arise. In this chapter we look at some of the most prevalent issues, talk about the root causes, both technical and social, and finally present solutions to these problems.
These are issues that I have personally run into and seen over and over again with different teams and products.
Problem: Bad Response Cached
Picture this: your site is up, the cache is hot, performance is great, and traffic is soaring. You open your browser, and the site comes up, because of course you’ve made it your homepage, and you immediately notice that instead of content, your site is serving up an error message.
No alarms have gone off, your availability report says everything is great, your application performance monitoring (APM) software is reporting no errors from your stack (only a small blip from one of your API dependencies a half hour ago).
So what in the world is going on? What went wrong, why is it showing no evidence, and how do you recover from this?
Cause
The most likely scenario is this: your site called an API or your own middleware tier to load content. This content is usually long lived, so your TTL is set for seven days.
The only problem is, that small blip a half an hour ago was the dependency throwing an error. It wasn’t an HTTP 500 error, but instead an upstream dependency to your API that threw a 500. Your API decided to return an HTTP 200 response but surface the error from its upstream dependency in the response body.
The issue is that HTTP error response codes are not cacheable to protect just this scenario. By wrapping the error response in an HTTP 200, the API has made the error cacheable.
What this means is that your cache layer stored this bad response from your API, and your application has loaded that in and is storing it in cache for the next seven days. All because the HTTP status codes were not being honored in the dependency chain of your application (see Figure 4-1).
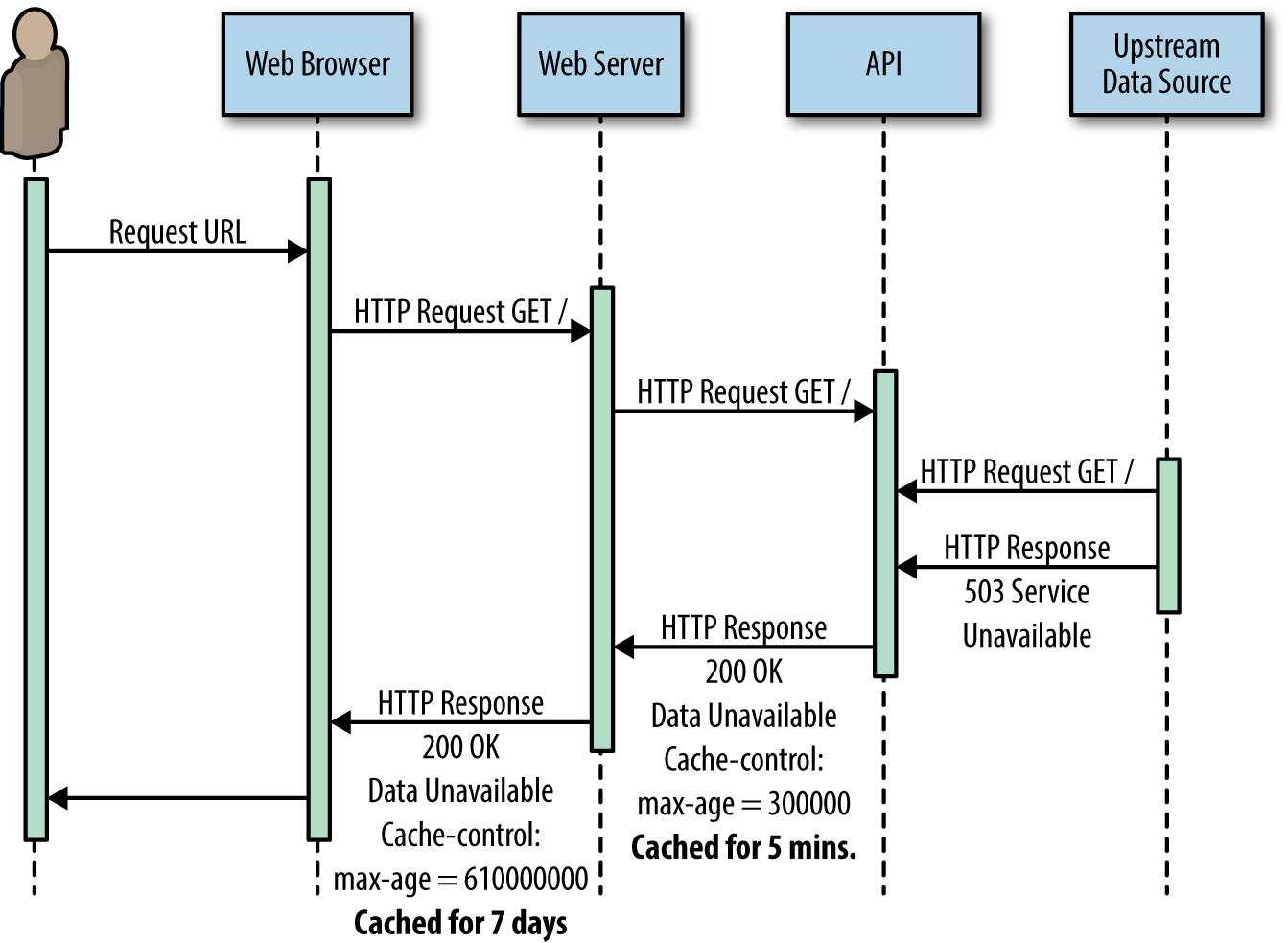
Figure 4-1. A sequence diagram that outlines how a bad response can be cached if the API returning the response does not also surface the error in the HTTP status code that it returns
So the clock is ticking, users are being presented with this error, and your site is essentially down. The calls are starting to come in. Let’s look at how to avoid this situation in the first place.
How to Avoid This
It may seem obvious, but the way to avoid this in the first place is to have a conversation with your partner teams. Review their documentation, and how they handle errors, and organize war games where you simulate outages up and down the dependency chain.
At the very least this will make you aware that this situation could occur, but ideally you will be able to convince or influence your partner teams to respect and surface the HTTP status codes of their upstream services. Anecdotally this is the most prevalent issue I’ve run into with service providers, and it’s usually either just a philosophical difference of opinion (why would I return an error; my service isn’t erroring out) or because the team has been incentivized through goals or an SLA to avoid anything resembling an error. These are all solved through communication and compromise.
Problem: Storing Private Content in Shared Cache
Here is another scenario: imagine you have a site that calls an API that loads in user data via an API call. This user data is presented to the user on your homepage, maybe innocuously as a welcome message, or more seriously as account, billing, or order information.
Cause
This is private data, intended for the specific user. But you just deployed an update and didn’t realize that your CDN by default applies a 15-minute cache to all content unless otherwise specified, including the new end point you just made to make the user data call.
A few minutes after you deploy the new end point, the calls start coming in, with customers complaining that they are seeing the wrong user information. The data from the call is being cached, so users are seeing previous users’ session information (see Figure 4-2).

Figure 4-2. A sequence diagram showing how inappropriately caching private content can result in exposing a user’s personal information to another user
How to Avoid This
There are two big things you can do to avoid this issue:
- Education: educate everyone on your team about how your CDN works, how cache works, and how important customer privacy is.
- Test in your CDN: chances are your lower environments are not in your CDN, which means that they don’t necessarily have the same cache rules, which then means that your testing will miss this test case completely. You can solve for this by having either a testing environment or ideally a dark portion of your production nodes in your CDN to test on.
Problem: GTM Is Ping-Ponging Between Data Centers
You’ve offloaded your scale to the frontend, and you are maintaining a lean, minimal backend infrastructure. Everything is lovely, deployments are fast because files don’t have to be cascaded across hundreds of machines, your operating costs are low, performance is beautiful, and all of your world is in harmony.
Except your application performance monitoring software has started sending throughput alerts. You take a look and see that your throughput is spiking high in one cluster of nodes for a little while, then drops to nothing, then the same happens in a different cluster of nodes. These groupings of nodes correspond to data center allocation. Essentially the Global Traffic Management service in your CDN is ping-ponging traffic between data centers.
You look at your nodes and they range from being up, down, starting back up, and having HTTP requests spiking.
Cause
What’s happened is that you have either deployed a change or made a configuration change that accidentally turned off caching for certain assets. In addition you have made your infrastructure too lean, so that it can’t withstand your full traffic for any significant amount of time.
The sheer number of requests coming in has caused your HTTP request pool to fill up, requests are stacking up, and your responses are drastically slowing down. Some machines are even running out of memory and are being unresponsive. Your CDN’s GTM service notices that the health checks for a given data center are not loading, and it sees your data center as being down, so it begins to direct all incoming requests to your other data center(s). This exacerbates the problem, and soon those machines are becoming unresponsive. The GTM service looks for a better data center to point traffic to, and it just so happens that was enough time for some of the requests in your downed data center to drain off. Therefore, it has started to become responsive again, so the GTM begins to point traffic there.
And the cycle continues.
How to Avoid This
Once again, education and awareness of how cache works and impacts your site should head off the change that started this in the first place. But there is a more insidious problem present: your infrastructure is too lean.
Capacity testing and planning ahead of time without cache turned on would have let you know your upper limits of scale.
Solution: Invalidating Your Cache
Once you are in the middle of most of the given scenarios, your path forward is to fix the underlying issue, then invalidate your cache.
A Word of Caution
Invalidating your cache forces your cache layer to refresh itself, so it is imperative to first make sure that the underlying issue is fixed.
In the case of the API returning an HTTP 200 with a body that contains an error, either get the team to surface the HTTP response of the upstream service or just don’t cache that API call. For the cached user data call, either don’t cache that call, or add a fingerprint to the URL.
Fingerprint the URLs
Fingerprinting the URL involves adding a unique ID to a URL. This can be done several ways for different reasons:
- Build life
As part of your application build-and-deploy process, you can have your build life added to the path to your static files as well as the links to them in your pages. This creates a brand new cache key and guarantees that previous versions are no longer referenced even in a user’s local browser cache.
- Hashed user ID
In the case of private data API calls, you may still want to cache the call. In that case you can add an ID that is unique to the user as part of the user call.
Kill Switch
When all else fails your CDN should provide you with a way to purge your edge cache. This is will systematically remove one or more items from cache. This is the nuclear option to the situation because it will cause a cache refresh to your origins for all incoming requests for that item(s).
Summary
We have just talked about a number of potential pitfalls you might run in to, and all were either due to misconfigured cache or from not following the HTTP specification. The key to recovering from these issues is having a way to invalidate cache.
Armed with the information in this chapter, from identifying issues to their fixes, you should be prepared to handle these issues when they arise in your own environments.
Get Intelligent Caching now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

