Chapter 1. Introducing the Service Mesh
What Is a Service Mesh?
Service meshes provide policy-based, network services for network-connected workloads by enforcing desired behavior of the network in the face of constantly changing conditions and topology. Conditions that change can be load, configuration, resources (including those affecting infrastructure and application topology of intracluster and intercluster resources coming and going), and workloads being deployed.
Fundamentals
Service meshes are an addressable infrastructure layer that allow you to manage both modernizing existing monolithic (or other) workloads as well as wrangling the sprawl of microservices. Service meshes are an addressable infrastructure layer brought to bear in full force. They’re beneficial in monolithic environments, but we’ll blame the microservices and containers movement—the cloud native approach to designing scalable, independently delivered services—for their brisk emergence. Microservices have exploded what were internal application communications into a mesh of service-to-service remote procedure calls (RPCs) transported over networks. Among their many benefits, microservices provide democratization of language and technology choice across independent service teams—teams that create new features quickly as they iteratively and continuously deliver software (typically as a service).
The field of networking being so vast, it’s no surprise that there are many subtle, near-imperceptible differences between similar concepts. At their core, service meshes provide a developer-driven, services-first network: one primarily concerned with obviating the need for application developers to build network concerns (e.g., resiliency) into their code; and one that empowers operators with the ability to declaratively define network behavior, node identity, and traffic flow through policy.
This might seem like software-defined networking (SDN) reincarnate, but service meshes differ here most notably by their emphasis on a developer-centric approach, not a network administrator–centric one. For the most part, today’s service meshes are entirely software based (although hardware-based implementations might be coming). Though the term intent-based networking is used mostly in physical networking, given the declarative policy-based control service meshes provide, it’s fair to liken a service mesh to a cloud native SDN. Figure 1-1 shows an overview of the service mesh architecture. (We outline what it means to be cloud native in Chapter 2.)

Figure 1-1. If it doesn’t have a control plane, it ain’t a service mesh.
Service meshes are built using service proxies. Service proxies of the data plane carry traffic. Traffic is transparently intercepted using iptable rules in the pod namespace.
This uniform layer of infrastructure combined with service deployments is commonly referred to as a service mesh. Istio turns disparate microservices into an integrated service mesh by systemically injecting a proxy among all network paths, making each proxy cognizant of one another, and bringing these under centralized control; thus forming a service mesh.
Sailing into a Service Mesh
Whether the challenge you face is managing a fleet of microservices or modernizing your existing noncontainerized services, you can find yourself sailing into a service mesh. The more microservices that are deployed, the greater these challenges become.
Client Libraries: The First Service Meshes?
To deal with the complicated task of managing microservices, some organizations have started using client libraries as frameworks to standardize implementations. These libraries are considered by some to be the first service meshes. Figure 1-2 illustrates how the use of a library requires that your architecture has application code either extending or using primitives of the chosen library(ies). Additionally, your architecture needs to accommodate the potential use of multiple language-specific frameworks and/or application servers to run them.
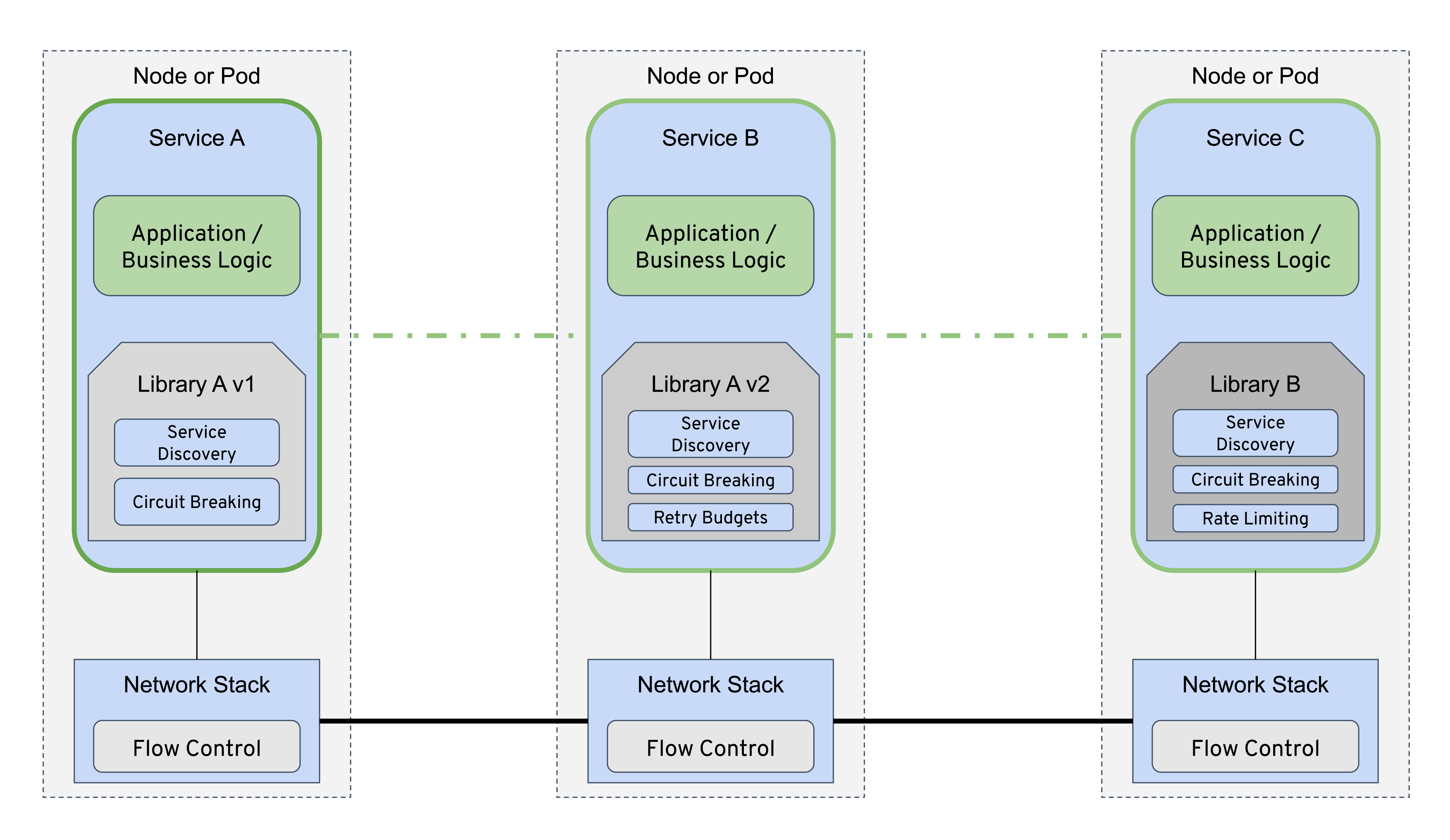
Figure 1-2. Services architecture using client libraries coupled with application logic
The two benefits of creating client libraries are that resources consumed are locally accounted for each and every service, and that developers are empowered to self-service their choice of an existing library or building a new language-specific library. Over time, however, the disadvantages of using client libraries brought service meshes into existence. Their most significant drawback is the tight coupling of infrastructure concerns with application code. Client libraries’ nonuniform, language-specific design makes their functionality and behavior inconsistent, which leads to poor observability characteristics, bespoke practices to augment services that are more or less controllable by one another, and possibly compromised security. These language-specific resilience libraries can be costly for organizations to adopt wholesale, and they can be either difficult to wedge into brownfield applications or entirely impractical to incorporate into existing architectures.
Networking is hard. Creating a client library that eliminates client contention by introducing jitter and an exponential back-off algorithm in the calculation of timing the next retry attempt isn’t necessarily easy, and neither is attempting to ensure the same behavior across different client libraries (with the varying languages and versions of those libraries). Coordinating upgrades of client libraries is difficult in large environments as upgrades require code changes, rolling a new release of the application and, potentially, application downtime.
Figure 1-3 shows how with a service proxy next to each application instance, applications no longer need to have language-specific resilience libraries for circuit breaking, timeouts, retries, service discovery, load balancing, and so on. Service meshes seem to deliver on the promise that organizations implementing microservices could finally realize the dream of using the best frameworks and language for their individual jobs without worrying about the availability of libraries and patterns for every single platform.
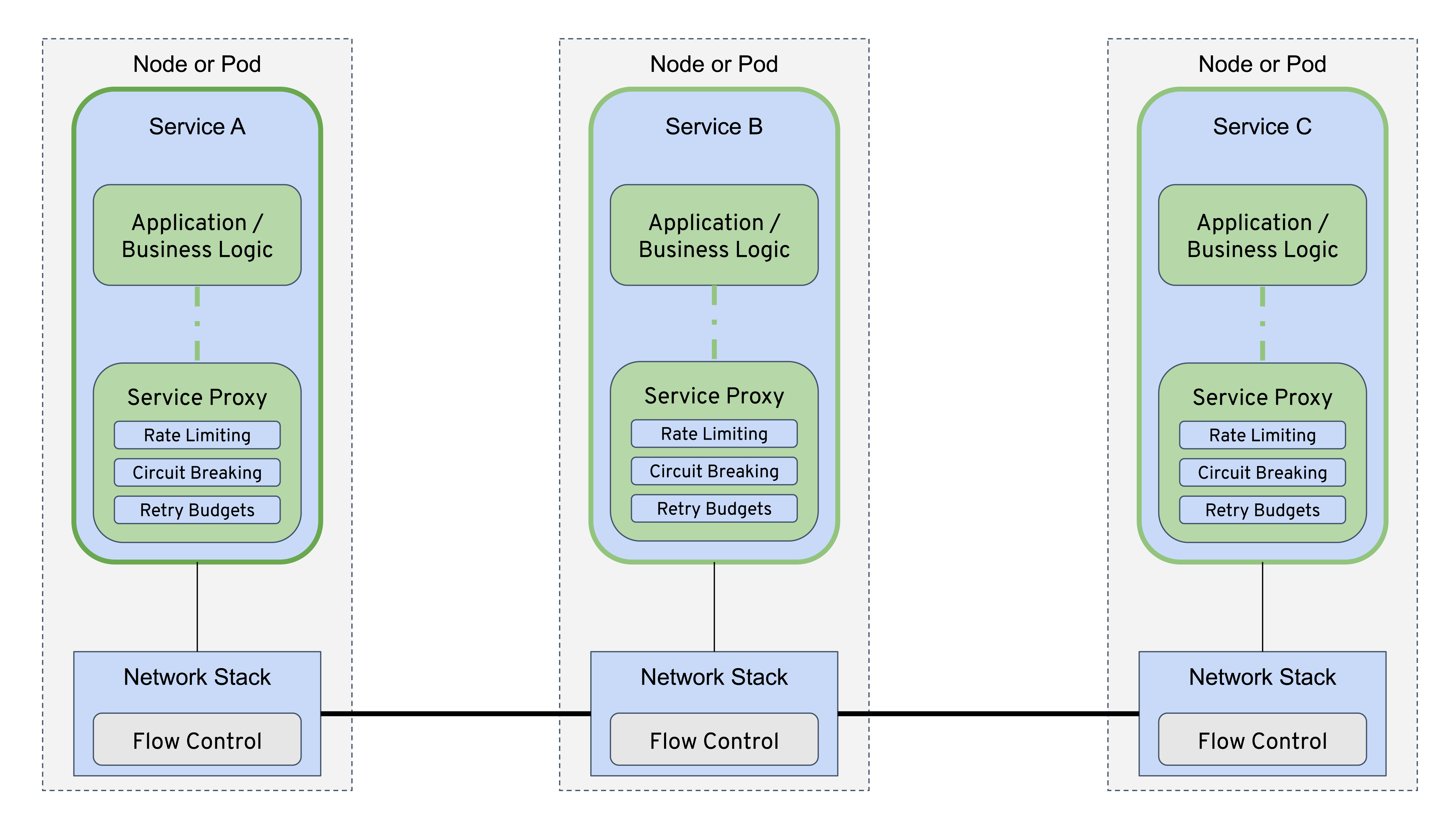
Figure 1-3. Services architecture using service proxies decoupled from application logic
Why Do You Need One?
At this point, you might be thinking, “I have a container orchestrator. Why do I need another infrastructure layer?” With microservices and containers mainstreaming, container orchestrators provide much of what the cluster (nodes and containers) needs. They focus largely on scheduling, discovery, and health, primarily at an infrastructure level (necessarily so), leaving microservices with unmet, service-level needs. A service mesh is a dedicated infrastructure layer for making service-to-service communication safe, fast, and reliable, at times relying on a container orchestrator or integration with another service discovery system. Service meshes might deploy as a separate layer atop container orchestrators, but don’t require them, as control and data-plane components might be deployed independent of containerized infrastructure. In Chapter 3, we look at how a node agent (including a service proxy) as the data-plane component is often deployed in noncontainer environments.
The Istio service mesh is commonly adopted à la carte. Organization staff we’ve spoken to are adopting service meshes primarily for the observability that they bring through instrumentation of network traffic. Many financial institutions in particular are adopting service meshes primarily as a system for managing the encryption of service-to-service traffic.
Whatever the catalyst, organizations are adopting posthaste. And service meshes are not only valuable in cloud native environments, to help with the considerable task of runing microservices. Many organizations that run monolithic services (those running on metal or virtual machines, on- or off-premises) keenly anticipate using service meshes because of the modernizing boost their existing architectures will receive from this deployment.
Figure 1-4 describes the capabilities of container orchestrators (asterisks denotes an essential capability). Service meshes generally rely on these underlying layers. The lower-layer focus is provided by container orchestrators.
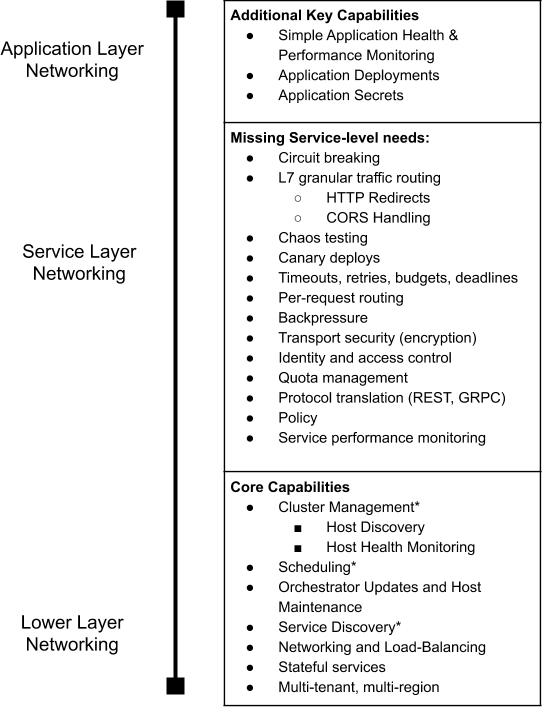
Figure 1-4. Container orchestration capabilities and focus versus service-level needs
Don’t We Already Have This in Our Container Platforms?
Containers simplify and provide generic, non-language-specific, application packaging and essential life cycle management. As a generic, non-language-specific platform, container orchestrators take responsibility for forming clusters, efficiently scheduling their resources, and managing higher-level application constructs (deployments, services, service-affinity, anti-affinity, health checking, scaling, etc.). Table 1-1 shows how container orchestrators generally have service discovery mechanisms—load balancing with virtual IP addresses built in. The supported load-balancing algorithms are typically simplistic in nature (round robin, random) and act as a single virtual IP to communicate with backend pods.
Kubernetes handles the registration/eviction of instances in the group based on their health status and whether they match a grouping predicate (labels and selectors). Then, services can use DNS for service discovery and load balancing regardless of their implementation. There’s no need for special language-specific libraries or registration clients. Container orchestrators have allowed us to move simple networking concerns out of applications and into the infrastructure, freeing the collective infrastructure technology ecosystem to advance our focus to higher layers.
Now you understand how service meshes complement underlying layers: what about other layers?
Landscape and Ecosystem
The service mesh landscape is a burgeoning ecosystem of tooling that’s not relegated to cloud native applications; indeed, it also provides much value to noncontainerized, nonmicroservice workloads. As you come to understand the role a service mesh plays in deployments and the value it provides, you can begin selecting a service mesh and integrating it with your incumbent tooling.
Landscape
How should you select a service mesh? Of the many service meshes currently available, their significant differences don’t make it easy for people to discern what actually is a service mesh and what isn’t. Over time, more of their capabilities are converging, making it easier to characterize and compare them.
Interestingly, but not surprisingly, many service meshes have been based on some of the same proxies, such as Envoy and NGINX.
Ecosystem
As far as how a service mesh fits in with other ecosystem technologies, we’ve already looked at client libraries and container orchestrators. API gateways address some similar needs and are commonly deployed on a container orchestrator as an edge proxy. Edge proxies provide services with Layer 4 (L4) to Layer 7 (L7) management while using the container orchestrator for reliability, availability, and scalability of container infrastructure.
API gateways interact with service meshes in a way that puzzles many, given that API gateways (and the proxies they’re built upon) range from traditional to cloud-hosted to microservices API gateways. The latter can be represented by a collection of microservices-oriented, open source API gateways, which use the approach of wrapping existing L7 proxies that incorporate container orchestrator native integration and developer self-service features (e.g., HAProxy, Traefik, NGINX, or Envoy).
With respect to service meshes, API gateways are designed to accept traffic from outside your organization or network and distribute it internally. API gateways expose your services as managed APIs, focused on transiting north-south traffic (in and out of the service mesh). They aren’t as well suited for traffic management within the service mesh (east-west) necessarily, because they require traffic to travel through a central proxy, and add a network hop. Service meshes are designed primarily to manage east-west traffic internal to the service mesh.
Given their complementary nature, you’ll often find API gateways and service meshes deployed in combination. API gateways wotk with other API management functions to handle analytics, business data, adjunct provider services, and implementation of versioning control. Today, there is overlap as well as gaps between service mesh capabilities, API gateways, and API management systems. As service meshes gain new capabilities, use cases overlap more.
The Critical, Fallible Network
As noted, in microservices deployments, the network is directly and critically involved in every transaction, every invocation of business logic, and every request made to the application. Network reliability and latency are among the chief concerns for modern, cloud native applications. One cloud native application might comprise hundreds of microservices, each with many instances that might be constantly rescheduled by a container orchestrator.
Understanding the network’s centrality, you want your network to be as intelligent and resilient as possible. It should:
-
Route traffic away from failures to increase the aggregate reliability of a cluster.
-
Avoid unwanted overhead like high-latency routes or servers with cold caches.
-
Ensure that the traffic flowing between services is secure against trivial attack.
-
Provide insight by highlighting unexpected dependencies and root causes of service communication failure.
-
Allow you to impose policies at the granularity of service behaviors, not just at the connection level.
Also, you don’t want to write all of this logic into your application.
You want Layer 5 management, a services-first network; you want a service mesh.
The Value of a Service Mesh
Currently, service meshes provide a uniform way to connect, secure, manage, and monitor microservices.
Observability
Service meshes give you visibility, resiliency, and traffic control, as well as security control over distributed application services. Much value is promised here. Service meshes are transparently deployed and give visibility into and control over traffic without requiring any changes to application code (for more details, see Chapter 2).
In this, their first generation, service meshes have great potential to provide value; Istio, in particular. We’ll have to wait and see what second-generation capabilities spawn when service meshes are as ubiquitously adopted as containers and container orchestrators have been.
Traffic control
Service meshes provide granular, declarative control over network traffic to determine, for example, where a request is routed to perform a canary release. Resiliency features typically include circuit-breaking, latency-aware load balancing, eventually consistent service discovery, retries, timeouts, and deadlines (for more details, see Chapter 8).
Security
When organizations use a service mesh, they gain a powerful tool for enforcing security, policy, and compliance requirements across their enterprise. Most service meshes provide a certificate authority (CA) to manage keys and certificates for securing service-to-service communication. Assignment of verifiable identity to each service in the mesh is key in determining which clients are allowed to make requests of different services as well as in encrypting that request traffic. Certificates are generated per service and provide a unique identity for that service. Commonly, service proxies (see Chapter 5) are used to take on the identity of the service and perform life cycle management of certificates (generation, distribution, refresh, and revocation) on behalf of the service (for more on this, see Chapter 6).
Modernizing your existing infrastructure (retrofitting a deployment)
Many people consider that if they’re not running many services, they don’t need to add a service mesh to their deployment architecture. This isn’t true. Service meshes offer much value irrespective of how many services you’re running. The value they provide then only increases with the number of services you run and with the number of locations from which your services deploy.
While some greenfield projects have the luxury of incorporating a service mesh from the start, most organizations will have existing services (monoliths or otherwise) that they’ll need to onboard to the mesh. Rather than a container, these services could be running in VMs or bare-metal hosts. Service meshes help with modernization, allowing organizations to upgrade their services inventory without rewriting applications, adopting microservices or new languages, or moving to the cloud.
You can use facade services to break down monoliths. You could also adopt a strangler pattern of building services around the legacy monolith to expose a more developer-friendly set of APIs.
Organizations can get observability support (e.g., metrics, logs, and traces) as well as dependency or service graphs for each of their services (microservice or not), as they adopt a service mesh. In regard to tracing, the only change required within the service is to forward certain HTTP headers. Service meshes are useful for retrofitting uniform and ubiquitous observability tracing into existing infrastructures with the least amount of code change.
Decoupling at Layer 5
An important consideration when digesting the value of a service mesh is the phenomenon of decoupling service teams and the delivery speed this enables, as demonstrated in Figure 1-5.
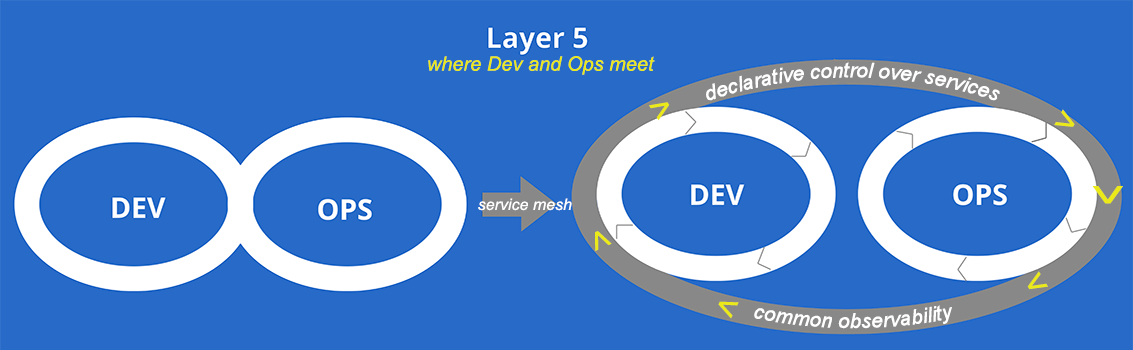
Figure 1-5. Layer 5 (L5), where Dev and Ops meet
Just as microservices help decouple feature teams, creating a service mesh helps decouple operators from application feature development and release processes, in turn giving operators declarative control over how their service layer is running. Creating a service mesh doesn’t just decouple teams, it eliminates the diffusion of responsibility among them and enables uniformity of practice standards across organizations within our industry. Consider this list of tasks:
-
Identify when to break a circuit and facilitate it.
-
Establish end-to-end service deadlines.
-
Ensure distributed traces are generated and propagated to backend monitoring systems.
-
Deny users of “Acme” account access to beta versions of your services.
Whose responsibility is this—the developer or the operator? Answers likely would differ from organization to organization; as an industry, we don’t have commonly accepted practices. Service meshes help keep these responsibilities from falling through the cracks or from one team blaming the other for lack of accountability.
The Istio Service Mesh
Let’s now embark on our journey into the Istio service mesh.
The Origin of Istio
Istio is an open source implementation of a service mesh first created by Google, IBM, and Lyft. What began as a collaborative effort among these organizations has rapidly expanded to incorporating contributions from many other organizations and individuals. Istio is a vast project; in the cloud native ecosystem, it’s second in scope of objectives to Kubernetes. It ingests a number of Cloud Native Computing Foundation (CNCF)–governed projects like Prometheus, OpenTelemetry, Fluentd, Envoy, Jaeger, Kiali, and many contributor-written adapters.
Akin to other service meshes, Istio helps you add resiliency and observability to your services architecture in a transparent way. Service meshes don’t require applications to be cognizant of running on the mesh, and Istio’s design doesn’t depart from other service meshes in this regard. Between ingress, interservice, and egress traffic, Istio transparently intercepts and handles network traffic on behalf of the application.
Using Envoy as the data-plane component, Istio helps you to configure your applications to have an instance of the service proxy deployed alongside it. Istio’s control plane is composed of a few components that provide configuration management of the data-plane proxies, APIs for operators, security settings, policy checks, and more. We cover these control-plane components in later chapters of this book.
Although it was originally built to run on Kubernetes, Istio’s design is deployment-platform agnostic. So, an Istio-based service mesh can also be deployed across platforms like OpenShift, Mesos, and Cloud Foundry, as well as traditional deployment environments like VMs and bare-metal servers. Consul’s interoperability with Istio can be helpful in VM and bare-metal deployments. Whether running monoliths or microservices, Istio is applicable—the more services you run, the greater the benefit.
The Current State of Istio
As an evolving project, Istio has a healthy release cadence, this being one way in which open source project velocity and health are measured. Figure 6-1 presents the community statistics from May 2017, when Istio was publicly announced as a project, to February 2019. During this period, there were roughly 2,400 forks (GitHub users who have made a copy of the project—either in the process of contributing to the project or using its code as a base for their own projects) and around 15,000 stars (users who have favorited the project and see project updates in their activity feed).
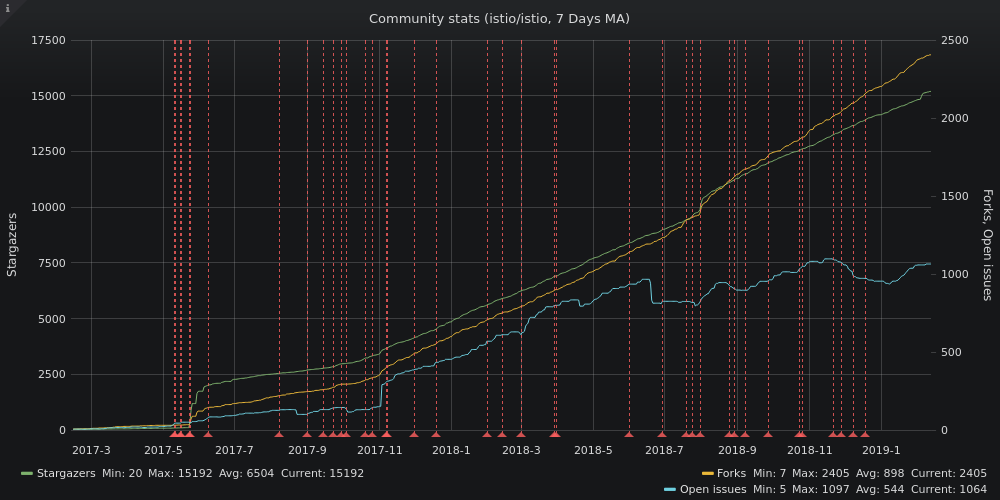
Figure 1-6. Istio contribution statistics
A simple number of stars, forks, and commits is moderately indicative of project health in terms of velocity, interest, and support. Each of these raw metrics can be improved upon. Reporting the rates of commits, reviews, and merges over time perhaps better indicates project velocity, which is most accurately measured relative to itself, and relative to its own timeline. When determining a project’s health, you should look at whether the rates of these activities are increasing or decreasing, whether the the release cadence is consistent; and how frequently and how many patches are released to improve a low-quality major or minor feature release?
Cadence
Like many software projects, Istio’s versioning semantics are laid out in a familiar (to Semantic Versioning) style (e.g., version 1.1.1), and, like other projects, Istio defines its own nuances to release frequency, setting expectations of longevity of support (see Table 1-1). Though daily and weekly releases are available, these aren’t supported and might not be reliable. However, as Table 1-1 shows, the monthly snapshots are relatively safe and are usually packed with new features. But, if you are looking to use Istio in production, look for releases tagged as “LTS” (Long-Term Support). As of this writing, 1.2.x is the latest LTS release.
| Type | Support level | Quality and recommended use |
|---|---|---|
Daily build |
No support |
Dangerous; might not be fully reliable. Useful for experimentation. |
Snapshot release |
Support is provided for only the latest snapshot release. |
Expected to be stable, but use in production should be limited to an as-needed basis. Usually only adopted by bleeding-edge users or users seeking specific features. |
LTS release |
Support is provided until three months after the next LTS. |
Safe to deploy in production. Users are encouraged to upgrade to these releases as soon as possible. |
Patches |
Same as the corresponding Snapshot/LTS release. |
Users are encouraged to adopt patch releases as soon as they are available for a given release. |
As a frame of reference, Kubernetes minor releases occur approximately every three months, so each minor release branch is maintained for approximately nine months.
By comparison, because it is an operating system, Ubuntu quite necessarily needs to prioritize stability over speed of feature release, and thus publishes its LTS releases every two years in April. It’s worth noting that the LTS releases are much more heavily used (something like 95% of all Ubuntu installations are LTS releases).
Docker uses a time-based release schedule, with time frames generally as follows:
-
Docker CE Edge releases happen monthly.
-
Docker CE Stable releases happen quarterly, with patch releases as needed.
-
Docker EE releases happen twice per year, with patch releases as needed.
Updates and patches release as follows:
-
Docker EE releases receive patches and updates for at least one year after they are released.
-
Docker CE Stable releases receive patches and updates for one month after the next Docker CE Stable release.
-
Docker CE Edge releases do not receive any patches or updates after a subsequent Docker CE Edge or Stable release.
Releases
The original plan was that Istio would have one point release every quarter, followed by n patch releases. Snapshots were intended as monthly releases that would mostly meet the same quality bar as a point release, except that it’s not a supported release and can have breaking changes. A history of all releases is available on Istio’s Releases page on GitHub. Table 1-2 presents Istio’s release cadence over a 10-month period.
| Release date | Release number | Days from last release |
|---|---|---|
4/16/19 |
1.1.3 |
11 |
4/5/19 |
1.1.2 |
0 |
4/5/19 |
1.0.7 |
11 |
3/25/19 |
1.1.1 |
6 |
3/19/19 |
1.1.0 |
3 |
3/16/19 |
1.1.0-rc.6 |
2 |
3/14/19 |
1.1.0-rc.5 |
2 |
3/12/19 |
1.1.0-rc.4 |
4 |
3/8/19 |
1.1.0-rc.3 |
4 |
3/4/19 |
1.1.0-rc.2 |
5 |
2/27/19 |
1.1.0-rc.1 |
6 |
2/21/19 |
1.1.0-rc.0 |
8 |
2/13/19 |
1.1.0-snapshot.6 |
0 |
2/13/19 |
1.0.6 |
19 |
1/25/19 |
1.1.0-snapshot.5 |
0 |
1/25/19 |
1.1.0-snapshot.4 |
48 |
12/8/18 |
1.0.5 |
11 |
11/27/18 |
1.1.0-snapshot.3 |
6 |
11/21/18 |
1.0.4 |
26 |
10/26/18 |
1.0.3 |
3 |
10/23/18 |
1.1.0-snapshot.2 |
26 |
9/27/18 |
1.1.0-snapshot.1 |
21 |
9/6/18 |
1.0.2 |
8 |
8/29/18 |
1.1.0-snapshot.0 |
5 |
8/24/18 |
1.0.1 |
24 |
7/31/18 |
1.0.0 |
8 |
7/23/18 |
1.0.0-snapshot.2 |
3 |
7/20/18 |
1.0.0-snapshot.1 |
22 |
6/28/18 |
1.0.0-snapshot.0 |
27 |
6/1/18 |
0.8.0 |
Feature Status
In true Agile style, Istio features individually go through their own life cycle (dev/alpha/beta/stable). Some features are stabilizing while others are being added or improved upon, as demonstrated in Table 1-3.
| Alpha | Beta | Stable | |
|---|---|---|---|
Purpose |
Demo-able; works end-to-end but has limitations |
Usable in production, not a toy anymore |
Dependable, production hardened. |
API |
No guarantees on backward compatibility |
APIs are versioned |
Dependable, production-worthy. APIs are versioned, with automated version conversion for backward compatibility. |
Performance |
Not quantified or guaranteed |
Not quantified or guaranteed |
Performance (latency/scale) is quantified, documented, with guarantees against regression. |
Deprecation policy |
None |
Weak: three months |
Dependable, firm. One-year notice will be provided before changes. |
Future
Working groups are iterating on designs toward a v2 architecture, incorporating learnings from running Istio at scale and usability feedback from users. With more and more people learning about service meshes in the future, ease of adoption will be key to helping the masses successfully reach the third phase of their cloud native journey → containers → orchestrators → meshes.
What Istio Isn’t
Istio doesn’t account for specific capabilities that you might find in other service meshes, or offered by management plane software. This is because it’s subject to change or to be commonly augmented with third-party software.
With the prominent exception of facilitating distributed tracing, Istio is not a white-box application performance monitoring (APM) solution. The generation of additional telemetry surrounding and introspecting network traffic and service requests that is available with Istio does provide additional black-box visibility. Of the metrics and logs available with Istio, these provide insight into network traffic flows, including source, destination, latency, and errors; top-level service metrics, not custom application metrics exposed by individual workloads or cluster-level logging.
Istio plug-ins integrate service-level logs with the same backend monitoring system you might be using for cluster-level logging (e.g., Fluentd, Elasticsearch, Kibana). Also, Istio uses the same metrics collection and alarming, which might well be the same utility (e.g., Prometheus) that you’re using already.
It’s Not Just About Microservices
Kubernetes doesn’t do it all. Will the infrastructure of the future be entirely Kubernetes-based? Not likely. Not all applications, notably those designed to run outside of containers, are a good fit for Kubernetes (currently, anyway). The tail of information technology is quite long considering that mainframes from decades ago are still in use today.
No technology is a panacea. Monoliths are easier to comprehend, because much of the application is in one place. You can trace the interactions of its different parts within one system (or a limited more or less stagnant set of systems). However, monoliths don’t scale, in terms of development teams and lines of code.
Nondistributed monoliths will be around for a long time. Service meshes help in their modernization and can provide facades to facilitate evolutionary architecture. Deployment of a service mesh gateway as an intelligent facade in front of the monolith will be an approach many take to strangle their monolith by siphoning path-based (or otherwise) requests away. This approach is gradual, leading to migrating parts of the monolith into modern microservices, or simply acting as a stopgap measure pending a fully cloud native redesign.
Terminology
Here are some important Istio-related terms to know and keep in mind:
- Cloud
- Cluster
- Config store
-
A system that stores configuration outside of the control plane itself for example, etcd in a Kubernetes deployment of Istio or even a simple filesystem.
- Container management
-
Loosely defined as OS virtualization provided by software stacks like Kubernetes, OpenShift, Cloud Foundry, Apache Mesos, and so on.
- Environment
-
The computing environment presented by various vendors of infrastructure as a service (IaaS), like Azure Cloud Services, AWS, Google Cloud Platform, IBM Cloud, Red Hat Cloud computing, or a group of VMs or physical machines running on-premises or in hosted datacenters.
- Mesh
-
A set of workloads with common administrative control; under the same governing entity (e.g., a control plane).
- Multienvironment (aka hybrid)
-
Describes heterogeneous environments where each might differ in the implementation and deployment of the following infrastructure components:
- Network boundaries
-
Example: one component uses on-premises ingress, and the other uses ingress operating in the cloud.
- Identity systems
-
Example: one component has LDAP, the other has service accounts.
- Naming systems like DNS
- VM/container/process orchestration frameworks
-
Example: one component has on-premises locally managed VMs, and the other has Kubernetes-managed containers running services.
- Multitenancy
-
Logically isolated, but physically integrated services running under the same Istio service mesh control plane.
- Network
-
A set of directly interconnected endpoints (can include a virtual private network [VPN]).
- Secure naming
-
Provides mapping between a service name and the workload principals authorized to run the workloads implementing a service.
- Service
-
A delineated group of related behaviors within a service mesh. Services are named using a service name, and Istio policies such as load balancing and routing are applied to service names. A service is typically materialized by one or more service endpoints.
- Service endpoint
-
The network-reachable manifestation of a service. Endpoints are exposed by workloads. Not all services have service endpoints.
- Service mesh
-
A shared set of names and identities that allows for common policy enforcement and telemetry collection. Service names and workload principals are unique within a mesh.
- Service name
-
A unique name for a service that identifies it within the service mesh. A service may not be renamed and maintain its identity: each service name is unique. A service can have multiple versions, but a service name is version-independent. Service names are accessible in Istio configuration as the
source.serviceanddestination.serviceattributes. - Service proxy
-
The data-plane component that handles traffic management on behalf of application services.
- Sidecar
-
A methodology of coscheduling utility containers with application containers grouped in the same logical unit of scheduling. In Kubernetes’s case, a pod.
- Workload
-
Process/binary deployed by operators in Istio, typically represented by entities such as containers, pods, or VMs. A workload can expose zero or more service endpoints; a workload can consume zero or more services. Each workload has a single canonical service name associated with it, but can also represent additional service names.
- Workload name
-
Unique name for a workload, identifying it within the service mesh. Unlike service name and workload principal, workload name is not a strongly verified property and should not be used when enforcing access control lists (ACLs). Workload names are accessible in Istio configuration as the
source.nameand thedestination.nameattributes. - Workload principal
-
Identifies the verifiable authority under which a workload runs. Istio service-to-service authentication is used to produce the workload principal. By default, workload principals are compliant with the SPIFFE ID format. Multiple workloads may share a workload principal, but each workload has a single canonical workload principal. These are accessible in Istio configuration as the
source.userand thedestination.userattributes. - Zone (Istio control plane)
-
Running set of components required by Istio. This includes Galley, Mixer, Pilot, and Citadel.
-
A single zone is represented by a single logical Galley store.
-
All Mixers and Pilots connected to the same Galley are considered part of the same zone, regardless of where they run.
-
A single zone can operate independently, even if all other zones are offline or unreachable.
-
Zones are not used to identify services or workloads in the service mesh. Each service name and workload principal belongs to the service mesh as a whole, not an individual zone.
-
Each zone belongs to a single service mesh. A service mesh spans one or more zones.
-
In relation to clusters (e.g., Kubernetes clusters) and support for multienvironments, a zone can have multiple instances of these. But Istio users should prefer simpler configurations. It should be relatively trivial to run control-plane components in each cluster or environment and limit the configuration to one cluster per zone.
-
Operators need independent control and a flexible toolkit to ensure they’re running secure, compliant, observable, and resilient microservices. Developers require freedom from infrastructure concerns and the ability to experiment with different production features, and deploy canary releases without affecting the entire system. Istio adds traffic management to microservices and creates a basis for value-add capabilities like security, monitoring, routing, connectivity management, and policy.
Get Istio: Up and Running now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

