Processing Twitter data
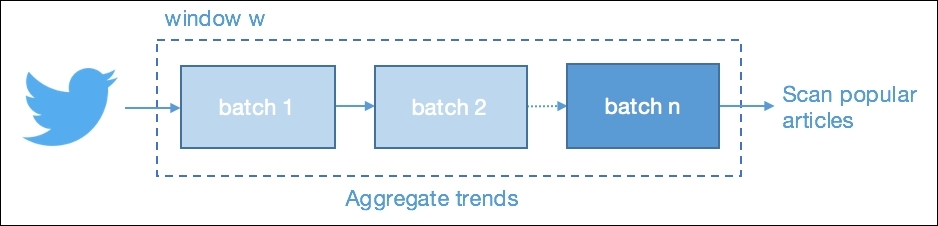
The second main constraint of using Twitter is the constraint of noise. When most classification models are trained against dozens of different classes, we will be working against hundreds of thousands of distinct hashtags per day. We will be focusing on popular topics only, meaning the trending topics occurring within a defined batch window. However, because a 15 minute batch size on Twitter will not be sufficient enough to detect trends, we will apply a 24-hour moving window where all hashtags will be observed and counted, and where only the most popular ones will be kept.
Get Mastering Spark for Data Science now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

