Chapter 1. Introduction
MongoDB is a powerful, flexible, and scalable general-purpose database. It combines the ability to scale out with features such as secondary indexes, range queries, sorting, aggregations, and geospatial indexes. This chapter covers the major design decisions that made MongoDB what it is.
Ease of Use
MongoDB is a document-oriented database, not a relational one. The primary reason for moving away from the relational model is to make scaling out easier, but there are some other advantages as well.
A document-oriented database replaces the concept of a “row” with a more flexible model, the “document.” By allowing embedded documents and arrays, the document-oriented approach makes it possible to represent complex hierarchical relationships with a single record. This fits naturally into the way developers in modern object-oriented languages think about their data.
There are also no predefined schemas: a document’s keys and values are not of fixed types or sizes. Without a fixed schema, adding or removing fields as needed becomes easier. Generally, this makes development faster as developers can quickly iterate. It is also easier to experiment. Developers can try dozens of models for the data and then choose the best one to pursue.
Designed to Scale
Dataset sizes for applications are growing at an incredible pace. Increases in available bandwidth and cheap storage have created an environment where even small-scale applications need to store more data than many databases were meant to handle. A terabyte of data, once an unheard-of amount of information, is now commonplace.
As the amount of data that developers need to store grows, developers face a difficult decision: how should they scale their databases? Scaling a database comes down to the choice between scaling up (getting a bigger machine) or scaling out (partitioning data across more machines). Scaling up is often the path of least resistance, but it has drawbacks: large machines are often very expensive, and eventually a physical limit is reached where a more powerful machine cannot be purchased at any cost. The alternative is to scale out: to add storage space or increase throughput for read and write operations, buy additional servers, and add them to your cluster. This is both cheaper and more scalable; however, it is more difficult to administer a thousand machines than it is to care for one.
MongoDB was designed to scale out. The document-oriented data model makes it easier to split data across multiple servers. MongoDB automatically takes care of balancing data and load across a cluster, redistributing documents automatically and routing reads and writes to the correct machines, as shown in Figure 1-1.
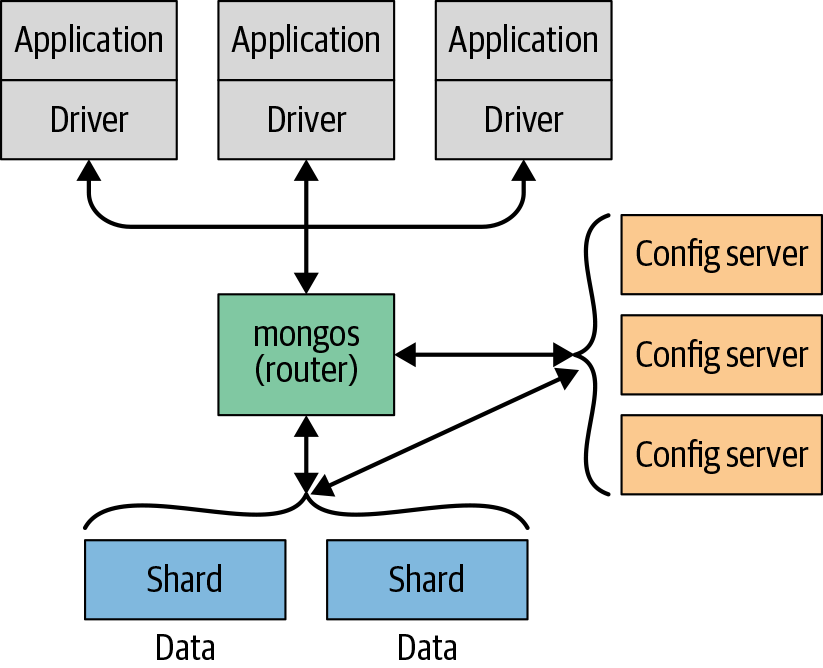
Figure 1-1. Scaling out MongoDB using sharding across multiple servers
The topology of a MongoDB cluster, or whether there is in fact a cluster rather than a single node at the other end of a database connection, is transparent to the application. This allows developers to focus on programming the application, not scaling it. Likewise, if the topology of an existing deployment needs to change in order to, for example, scale to support greater load, the application logic can remain the same.
Rich with Features…
MongoDB is a general-purpose database, so aside from creating, reading, updating, and deleting data, it provides most of the features you would expect from a database management system and many others that set it apart. These include:
- Indexing
MongoDB supports generic secondary indexes and provides unique, compound, geospatial, and full-text indexing capabilities as well. Secondary indexes on hierarchical structures such as nested documents and arrays are also supported and enable developers to take full advantage of the ability to model in ways that best suit their applications.
- Aggregation
MongoDB provides an aggregation framework based on the concept of data processing pipelines. Aggregation pipelines allow you to build complex analytics engines by processing data through a series of relatively simple stages on the server side, taking full advantage of database optimizations.
- Special collection and index types
MongoDB supports time-to-live (TTL) collections for data that should expire at a certain time, such as sessions and fixed-size (capped) collections, for holding recent data, such as logs. MongoDB also supports partial indexes limited to only those documents matching a criteria filter in order to increase efficiency and reduce the amount of storage space required.
- File storage
MongoDB supports an easy-to-use protocol for storing large files and file metadata.
Some features common to relational databases are not present in
MongoDB, notably complex joins. MongoDB supports joins in a very limited
way through use of the $lookup
aggregation operator introduced in the 3.2 release. In the 3.6 release,
more complex joins are possible using multiple join conditions as well as
unrelated subqueries. MongoDB’s treatment of joins were architectural
decisions to allow for greater scalability, because both of those features
are difficult to provide efficiently in a distributed system.
…Without Sacrificing Speed
Performance is a driving objective for MongoDB, and has shaped much of its design. It uses opportunistic locking in its WiredTiger storage engine to maximize concurrency and throughput. It uses as much RAM as it can as its cache and attempts to automatically choose the correct indexes for queries. In short, almost every aspect of MongoDB was designed to maintain high performance.
Although MongoDB is powerful, incorporating many features from relational systems, it is not intended to do everything that a relational database does. For some functionality, the database server offloads processing and logic to the client side (handled either by the drivers or by a user’s application code). Its maintenance of this streamlined design is one of the reasons MongoDB can achieve such high performance.
The Philosophy
Throughout this book, we will take the time to note the reasoning or motivation behind particular decisions made in the development of MongoDB. Through those notes we hope to share the philosophy behind MongoDB. The best way to summarize the MongoDB project, however, is by referencing its main focus—to create a full-featured data store that is scalable, flexible, and fast.
Get MongoDB: The Definitive Guide, 3rd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

