Chapter 4. What’s Code Without Variables?
PL/SQL is a strongly typed language. This means that before you can work with any kind of data structure, you must first declare it. And when you declare it, you specify its type and, optionally, an initial or default value. All declarations of these variables must be made in the declaration section of your anonymous block, procedure, function, or package. I’ve divided the best practices in this chapter into three main categories, described in the following sections:
- Best Practices for Declaring Variables and Data Structures
Presents best practices for specifying %TYPE and %ROWTYPE, declaring SUBTYPEs, and localizing variable initialization.
- Best Practices for Using Variables and Data Structures
Presents best practices for simplifying the specification of business rules and data structures and avoiding implicit datatype conversions.
- Best Practices for Declaring and Using Package Variables
Presents best practices aimed particularly at the use of variables in packages.
Best Practices for Declaring Variables and Data Structures
Use the best practices described in this section when you declare your variables and data structures.
That column’s never going to change!
Always anchor variables to database datatypes using %TYPE and %ROWTYPE.
Problem: Lizbeth writes a “quick-and-dirty” program.
Lizbeth hates doing anything the quick-and-dirty way. In fact, she generally hates to be in a hurry at all. But Sunita comes by with an urgent request: “I need you to write a program to scan through all the flimsy excuses in our system, and display the title and description of each excuse. I need it in 30 minutes, but we’re going to run it only once, so you don’t have to worry about following all the usual best practices.”
Gritting her teeth, Lizbeth puts aside her good judgment and quickly familiarizes herself with the structure of the table:
CREATE TABLE flimsy_excuses (
id INTEGER
, title VARCHAR2(50)
, description VARCHAR2(100)
, ... and many more columns ...
);She then throws together the following program:
PROCEDURE show_excuses
IS
CURSOR quick_cur IS SELECT title, description FROM flimsy_excuses;
l_title VARCHAR2 (50);
l_desc VARCHAR2 (100);
BEGIN
OPEN quick_cur;
LOOP
FETCH quick_cur INTO l_title, l_description;
EXIT WHEN quick_cur%NOTFOUND;
DBMS_OUTPUT.put_line (
'Title/description: ' || l_title || ' - ' || l_desc);
END LOOP;
END show_excuses;Lizbeth runs some tests—it appears to do the job. She finishes in well under 30 minutes and hands over the code to Sunita, who is delighted and hurries off to do whatever she needs to do with it. Quickly putting show_excuses out of her mind, Lizbeth returns to her real work, and slows way down.
Years go by, and one day Lizbeth gets a call from Support: “We’re getting reports of unhandled VALUE_ERROR exceptions in the reporting module. Can you take a look?” She does take a look and much to her combined horror, dismay, and disgust, she finds that old quick-and-dirty, one-off, never-to-be-used-again show_excuses program integrated directly into the production reporting subsystem.
That’s bad enough, but it seems that it has been working for years. Why would it suddenly be experiencing “technical difficulties?” It takes Lizbeth two very frustrating hours, but she finally figures it out: the DBAs just yesterday put in a number of changes to the base tables so that My Flimsy Excuse could support multiple languages (many of which are much more verbose than English).
In particular, the maximum length of the flimsy_excuses.title column was increased to 1,000 and the description column to 4,000. Once the new data went into the table and the program was run, those quick-and-dirty declarations of l_title and l_description were suddenly wholly inadequate.
Solution: Assume that everything will change and that any program you write could be around for decades.
Lizbeth never should have compromised her programming principles. Everyone’s always in a hurry, but we all know that doing things in a hurry doesn’t really save time—it just shifts where the time is spent.
Furthermore, we always underestimate the staying power of our code. We can’t really imagine that the program we write today will be around for years (heck, we don’t even really believe that our code can continue working year after year without our paying any attention to it!). Yet it does. Applications have incredible staying power. And the shortcuts we take today come back to bite us (or whichever poor fool now must maintain the application) later on.
So we should always write our programs expecting them to last a long, long time—and also expecting everything they depend on and use to change.
In the particular case of the show_excuses program, Lizbeth’s big mistake was getting lazy about declaring the two variables. She hardcoded the maximum length of the variables to the current maximum size of the table’s columns. Instead, she should have declared the variables using the %TYPE attribute, as you see in this rewritten declaration section:
PROCEDURE show_excuses IS CURSOR quick_cur IS SELECT title, description FROM flimsy_excuses; l_title flimsy_excuses.title%TYPE; l_desc flimsy_excuses.description%TYPE;
Now this program will automatically adapt to changes in the underlying table. It won’t have a choice in the matter. Whenever the data structure against which a declaration is anchored changes, the program containing the anchoring is marked INVALID. Upon recompilation, it automatically uses the new form of the data structure.
These declarations are also “self-documenting”: a %TYPE declaration tells anyone who reads it what kind of data this variable is supposed to hold.
You can also use the %ROWTYPE attribute to anchor an entire record to a cursor, table, or view. In fact, this kind of declaration makes much more sense for show_excuses. Let’s rewrite the program using %ROWTYPE:
PROCEDURE show_excuses
IS
CURSOR quick_cur IS SELECT title, description FROM flimsy_excuses;
l_record quick_cur%ROWTYPE;
BEGIN
OPEN quick_cur;
LOOP
FETCH quick_cur INTO l_record;
EXIT WHEN quick_cur%NOTFOUND;
DBMS_OUTPUT.put_line ( 'Title/description: '
|| l_record.title || ' - ' || l_record.description); '
END LOOP;
END show_excuses;Now Lizbeth can declare just a single variable, a record, that has the same structure as the cursor. This code is even more resilient. The lengths of columns can, of course, change without causing the program to raise errors. But Lizbeth can even add more values to the SELECT list of the query, and the record will automatically (after recompilation) have an extra field corresponding to that new element.
Lizbeth could simplify this code even further by using a cursor FOR loop. Since she is iterating through every row, she can avoid the record declaration entirely as follows:
PROCEDURE show_excuses
IS
CURSOR quick_cur IS SELECT title, description FROM flimsy_excuses;
BEGIN
FOR l_record IN quick_cur
LOOP
DBMS_OUTPUT.put_line ( 'Title/description: '
|| l_record.title || ' - ' || l_record.description);
END LOOP;
END show_excuses;Tip
If your variable holds data that is coming from a table or a cursor, use %TYPE or %$ROWTYPE to declare that variable. Aim for a single point of definition for the datatypes that you are using for declarations. And if you can get the Oracle database to do the work for you (implicitly declaring the variable or record), all the better!
There’s more to data than columns in a table.
Use SUBTYPEs to declare program-specific and derived datatypes.
Problem: Lizbeth learns her lesson but then cannot apply it.
No doubt about it, Lizbeth has learned her lesson: even when she is told to hurry, she will take her time and use %TYPE and %ROWTYPE to declare her variables.
Sure enough, Sunita is soon back at her cubicle, asking her to write another program. This time, she needs to display the names of all the people who have requested flimsy excuses. The name of a person must be displayed in the form “LAST, FIRST.” The excuser (a person who makes excuses) table has these columns, among others:
CREATE TABLE excuser ( id INTEGER , first_name VARCHAR2(50) , last_name VARCHAR2(100) , ... and many more columns ... );
She then starts writing the function to construct the full name:
FUNCTION full_name ( last_name IN excuser.last_name%TYPE , first_name IN excuser.first_name%TYPE ) RETURN VARCHAR2
But then it is time to declare a local variable to hold the full name, and she tries to write something like this:
IS l_fullname excuser.???%TYPE;
But what can she use for the column name? There is no column for “full name”: it is a derived value. Lizbeth sighs. Will she just have to hardcode another maximum length and run into another bug years from now?
Solution: Create a new datatype with SUBTYPE and anchor to that.
The SUBTYPE statement allows you to create “aliases” for existing types of information, in effect creating your own specially named datatypes. Use SUBTYPE when you want to standardize on a set of named datatypes that aren’t anchorable back to the database. You can then anchor to those new datatypes instead, and achieve the same, desired goal: if a change must be made to, or takes place in, a datatype, you will have to make that change in only one place.
Let’s apply this technique to Lizbeth’s challenge. Stepping back for a moment, the full_name function really is an encapsulation of a business rule: how to construct the full name for an excuser.
Rather than write a standalone, schema-level function to return that full name, it would make much more sense to create a separate package to hold all the rules-related activity for an excuser. So, Lizbeth can create a package specification like this:
PACKAGE excuser_rp
IS
FUNCTION full_name (
last_name_in IN excuser.last_name%TYPE
, first_name_in IN excuser.first_name%TYPE
)
RETURN VARCHAR2;
END excuser_rp;In addition, she can create a new datatype that is designed to hold full names:
PACKAGE excuser_rp
IS
SUBTYPE full_name_t IS VARCHAR2(1000);
FUNCTION full_name (
last_name_in IN excuser.last_name%TYPE
, first_name_in IN excuser.first_name%TYPE
)
RETURN full_name_t;
END excuser_rp;The SUBTYPE command simply defines another name, an alias, for VARCHAR2(1000). She can then use that type as the return type of the function to clearly document what type of string is being returned.
Now attention shifts to the package body:
PACKAGE BODY excuser_rp
IS
FUNCTION full_name (
last_name_in IN excuser.last_name%TYPE
, first_name_in IN excuser.first_name%TYPE
)
RETURN full_name_t
IS
l_fullname full_name_t;
BEGIN
l_fullname := last_name_in || ',' || first_name_in;
RETURN l_fullname;
END full_name;
END excuser_rp;And when Lizbeth calls this function, she will also use the full name type:
DECLARE
l_my_name excuser_rp.full_name_t;
BEGIN
l_my_name := excuser_rp.full_name (
l_person.last_name, l_person.first_name);Notice that Lizbeth no longer hardcodes her datatype in the declaration; she simply refers back to her subtype. If 1,000 characters are not enough, she can change the definition of that subtype in the package specification and recompile. Everything will automatically adjust to the new size.
Clearly, Lizbeth could have written this function without declaring a local full name variable altogether, but the example illustrates an important point. Note, however, that you will certainly run into this requirement with much more complex code in which local variables will be required.
I take exception to your declaration section.
Perform complex variable initialization in the execution section.
Problem: The exception section of a block can only trap errors raised in the execution section.
That is a little fact that many PL/SQL developers don’t realize, and one that causes lots of headaches. Delaware writes the following packaged function, a classic “getter” of a private variable:
PACKAGE fe_config
IS
FUNCTION get_worst_excuse RETURN VARCHAR2;
END fe_config;
/
PACKAGE BODY fe_config
IS
c_worst_excuse CONSTANT VARCHAR2 (20) :=
'The dog ate my homework. Really.';
FUNCTION get_worst_excuse RETURN VARCHAR2
IS
BEGIN
RETURN c_worst_excuse;
END get_worst_excuse;
BEGIN
DBMS_OUTPUT.put_line ('Initialization logic here');
... lots of initialization code ...
EXCEPTION
WHEN OTHERS
THEN
fe_errmgr.log_and_raise_error;
END fe_config;
/As far as Delaware can tell, he has set things up so that if anything goes wrong while initializing the package, he will trap and log the error. Yet when he tries to call the function, he gets an unhandled exception:
SQL>BEGIN2DBMS_OUTPUT.PUT_LINE (fe_config.get_worst_excuse ( ));3END;4/BEGIN * ERROR at line 1: ORA-06502: PL/SQL: numeric or value error: character string buffer too small ORA-06512: at "HR.FE_CONFIG", line 3
For a solid five minutes, Delaware stares at this simple package, stumped. Then he groans and smacks his forehead. Of course! The exception section that is underneath the package initialization section will trap only exceptions that occur in that initialization section (the execution section of a package). And 20 characters simply aren’t enough for the world’s worst excuse.
Now Delaware could simply raise the length of that constant’s VARCHAR2 declaration. But he would rather fix the problem in a more long-lasting and fundamental way.
Solution: Don’t trust the declaration section to assign default values.
As we’ve seen, the exception section of a block can trap only errors raised in the execution section of that block. So if the code you run to assign a default value to a variable fails in the declaration section, that error is propagated unhandled out to the enclosing program. It’s difficult to debug these problems, too, so you must either:
Be sure that your initialization logic doesn’t ever raise an error. That’s hard to guarantee, isn’t it?
Perform your initialization at the beginning of the execution section, preferably in a separate “initialization” program.
Here’s what Delaware did with his package:
He did no more hardcoding of the VARCHAR2 length. He anchored to a database column instead.
He moved the assignment of the default value into a separate procedure, and called this procedure in the package’s initialization section.
Tip
It is particularly important to avoid assigning default values in the declaration section if they are function calls or expressions that make it hard to predict the value that will be returned.
Here is Delaware’s new code:
PACKAGE BODY fe_config
IS
g_worst_excuse flimsy_excuse.title%TYPE;
FUNCTION get_worst_excus RETURN VARCHAR2 IS
BEGIN
RETURN g_worst_excuse;
END get_worst_excuse;
PROCEDURE initialize IS
BEGIN
g_worst_excuse := 'The dog ate my homework. Really.';
END initialize;
BEGIN
initialize;
EXCEPTION
WHEN OTHERS
THEN
fe_errmgr.log_and_raise_error;
END fe_config;Now if that string is too long, the exception section will catch the problem and the error logging will come into play.
Best Practices for Using Variables and Data Structures
Use the best practices described in this section when you reference the data structures you have declared in your programs.
This logic is driving me crazy!
Replace complex expressions with well-named constants, variables, or functions.
Problem: Business rules can be complicated, and it’s hard to keep them straight.
While it’s possible to train our brains to manage and keep straight a very large amount of information, we all have limits. Unfortunately, application requirements don’t always respect those limits. You’ll often encounter business rules with 5, 10, or 20 individual clauses in them. And you’ll have to put all of those together in a way that works and, ideally, can be understood and maintained. And therein lies the rub.
Consider the code below. I need to figure out whether an employee is eligible to receive a raise, so I faithfully translate the various conditions from the requirements document to the code:
IF l_total_salary BETWEEN 10000 AND 50000 AND emp_status (emp_rec.employee_id) = 'H' AND (MONTHS_BETWEEN (emp_rec.hire_date, SYSDATE) > 10) THEN give_raise (emp_rec.empno); END IF;
This code compiles, I do some testing, and it seems to be working all right, so I move on. A week later I come back to this area of my program to fix a bug, and realize: Wow, that’s hard to understand! And because I can’t immediately understand it, I also can’t be very confident of what it does or whether it is correct.
Lucky for me, I don’t need to understand that code right now. It’s not part of the bug. But it does distract me, and make it hard to find and read the code that was causing the problem.
Solution: Simplify code to make the criteria for the business rules more obvious.
So, I put my bug-fixing on hold for a moment and create a local function named eligible_for_raise and simply move all the code there. Then my main execution section is simplified to do nothing more than this:
IF eligible_for_raise (l_total_salary, emp_rec) THEN give_raise (emp_rec.empno); END IF;
With this approach, I have hidden all the detailed logic behind a function interface. If a person working in this program needs to get the details, she can visit the body of the function.
Yet this function still has all the same problems of readability and maintainability, so the best approach of all is to go inside that function and make the criteria behind the rule more obvious:
FUNCTION eligible_for_raise (
total_salary_in IN NUMBER
, emp_rec_in IN employees%ROWTYPE
)
RETURN BOOLEAN
IS
c_salary_in_range CONSTANT BOOLEAN
:= total_salary_in BETWEEN 10000 AND 50000;
c_hired_more_than_a_year CONSTANT BOOLEAN
:= MONTHS_BETWEEN (emp_rec.hire_date, SYSDATE) > 10;
c_hourly_worker CONSTANT BOOLEAN
:= emp_status (emp_rec.employee_id) = 'H';
l_return BOOLEAN;
BEGIN
l_return := c_salary_in_range
AND c_hired_more_than_a_year
AND c_hourly_worker;
RETURN NVL (l_return, FALSE);
END eligible_for_raise;Certainly my code has gotten longer, but now it is so much easier to understand. I don’t have to deduce or infer anything from the code. Instead, it tells me, directly and explicitly, what is going on.
Go ahead and splurge: declare distinct variables for different usages.
Don’t overload data structure usage.
Problem: World weariness infects Lizbeth’s code.
Lizbeth is a good citizen of the world. She read The Nation each week (which is, by the way, the oldest weekly newspaper published in the United States), votes in every election, and contacts her Congressperson about any number of issues. She is, in short, well informed and intelligent, and consequently tends to get rather depressed about the state of affairs in the world.
Usually, she puts that aside when she comes to work (in fact, she looks to her world of programming as a refuge). Today, however, she just feels tired of it all, and still, she must work on a “scan and analyze” that takes a list of excuses and perhaps performs analysis on them. She needs to get the number of excuses in the list, get the length of each title, and so on. So many integer variables, so little time! With a big sigh, she writes the following code:
PROCEDURE scan_and_analyze (
excuses_in IN excuses_tp.excuses_tc — a collection type
)
IS
intval PLS_INTEGER;
BEGIN
intval := excuses_in.COUNT;
IF intval > 0
THEN
FOR indx IN 1 .. excuses_in.COUNT
LOOP
intval := LENGTH (excuses_in (indx).title);
analyze_excuse_usage (intval);
END LOOP;
END IF;
END;Sure, the code will compile. But who would want to maintain code that looks like this?
Solution: Don’t let your weariness show in your code—and don’t recycle!
This is just one entry of a more general category: “Don’t be lazy (in the wrong way)!”
The problem with Lizbeth’s code is that it’s pretty much impossible to look at any use of the intval variable and understand what is going on. You have to go back to the most recent assignment to make sense of the code. Compare that to the following:
PROCEDURE scan_and_analyze (
excuses_in IN excuses_tp.excuses_tc -- a collection type
)
IS
l_excuse_count PLS_INTEGER;
l_page_length PLS_INTEGER;
BEGIN
l_excuse_count := excuses_in.COUNT;
IF l_excuse_count > 0
THEN
FOR indx IN 1 .. excuses_in.COUNT
LOOP
l_page_length := LENGTH (excuses_in (indx).title);
analyze_excuse_usage (l_page_length);
END LOOP;
END IF;
END;When you declare a variable, you should give it a name that accurately reflects its purpose in a program. If you then use that variable in more than one way (“recycling”), you create confusion and, very possibly, introduce bugs.
The solution is to declare and manipulate separate data structures for each distinct requirement. With this approach, you can also make a change to one variable’s usage without worrying about its ripple effect to other areas of your code.
Here is a final, general piece of advice: reliance on a “time-saver” shortcut should raise a red flag. You’re probably doing (or avoiding) something now for which you will pay later.
Didn’t your parents teach you to clean up after yourself?
Clean up data structures when your program terminates (successfully or with an error).
Problem: Sometimes you really do need to clean up in a PL/SQL block.
PL/SQL does an awful lot of cleanup for you automatically, but there are a number of scenarios in which it’s absolutely crucial for you to take your own cleanup actions.
Consider the following program: it manipulates a packaged cursor, declares a DBMS_SQL cursor, and writes information to a file:
PROCEDURE busy_busy
IS
fileid UTL_FILE.FILE_TYPE;
dyncur PLS_INTEGER;
BEGIN
dyncur := DBMS_SQL.OPEN_CURSOR;
OPEN book_pkg.all_books_by ('FEUERSTEIN');
fileid := UTL_FILE.FOPEN ('/apps/library', 'bestsellers.txt', 'R');
... use all that good stuff in here ...
EXCEPTION
WHEN OTHERS
THEN
err.log;
RAISE;
END busy_busy;At first glance, you might want to congratulate the author for including an exception section that logs the error and then raises that exception again. Hey, at least he gave some thought to the fact that something actually could go wrong.
With a second glance, however, we uncover some drawbacks: after this program terminates (even without an error), the dynamic SQL cursor floats away, uncloseable, because the handle is erased from memory. Yet the cursor itself continues to consume SGA memory, which could cause serious problems if this kind of error is widespread. And that’s not all. The package-based cursor (all_books_by) stays open, which means that the next time this program is called, the still-open packaged cursor causes an ORA-06511: PL/SQL: cursor already open error. Wait, there’s more! The file is not closed, but the handle to the file is cleaned up, thereby making it impossible to close this file without closing all files with UTL_FILE.FCLOSE_ALL or with a disconnect.
Yuck! That program is as messy as my son’s bedroom when he was a teenager. Clearly, we need to do some cleanup. How about this?
PROCEDURE busy_busy
IS
fileid UTL_FILE.FILE_TYPE;
dyncur PLS_INTEGER;
BEGIN
dyncur := DBMS_SQL.OPEN_CURSOR;
OPEN book_pkg.all_books_by ('FEUERSTEIN');
fileid := UTL_FILE.FOPEN ('/apps/library', 'bestsellers.txt', 'R');
... use all that good stuff in here ...
DBMS_SQL.CLOSE_CURSOR;
UTL_FILE.FCLOSE (fileid);
CLOSE book_pkg.all_books_by;
EXCEPTION
WHEN OTHERS
THEN
err.log;
RAISE;
END busy_busy;Now, that’s really great—as long as no error is raised. Because if the program terminates with an exception, then all the same problems occur. No problem! I will simply copy and paste those three cleanup lines into the exception section. Really? No! Terrible idea! Whenever you find yourself thinking about copying and pasting code, ask yourself: do I really want to have multiple copies of this code running around in my application?
Maybe, just maybe, it would be better to create a single program and call it wherever it is needed. I have taken that approach in my third implementation of busy_busy (below). I now have a local procedure that performs all cleanup operations. I call it at the end of the execution section (clean up on success) and in the WHEN OTHERS clause (clean up on failure).
PROCEDURE busy_busy
IS
fileid UTL_FILE.FILE_TYPE;
dyncur PLS_INTEGER;
PROCEDURE cleanup IS
BEGIN
IF book_pkg.all_books_by%ISOPEN THEN
CLOSE book_pkg.all_books_by;
END IF;
IF DBMS_SQL.IS_OPEN (dyncur) THEN
DBMS_SQL.CLOSE_CURSOR (dyncur);
END IF;
IF UTL_FILE.ISOPEN (fileid) THEN
UTL_FILE.FCLOSE (fileid);
END IF;
END cleanup;
BEGIN
dyncur := DBMS_SQL.OPEN_CURSOR;
OPEN book_pkg.all_books_by ('FEUERSTEIN');
fileid := UTL_FILE.FOPEN (
'/apps/library', 'bestsellers.txt', 'R');
... use all that good stuff in here ...
cleanup;
EXCEPTION
WHEN NO_DATA_FOUND
THEN
err.log;
cleanup;
RAISE;
END;Notice that as I moved my cleanup logic into its own program, I also took the time to enhance it, so that I close only those things that are actually open. This increased attention to detail and completeness often happens quite naturally when you focus on creating a single-purpose program.
A common cleanup procedure offers several important advantages:
Your programs are less likely to have memory leaks (open cursors) and to cause problems in other programs by leaving data structures in an uncertain state.
Future developers can easily add new cleanup operations in one place and be certain that they will be run at all exit points.
When and if I add another WHEN clause, I will be very likely to follow the “model” in WHEN OTHERS and perform cleanup there as well.
Programmers are (or should be) control freaks.
Beware of and avoid implicit datatype conversions.
Problem: PL/SQL performs implicit conversions—but they’re not always what you want.
Sometimes, PL/SQL makes life just too darn easy for us developers. It will, for example, allow you to write and execute code like this:
DECLARE my_birthdate DATE := '09-SEP-58';
In this case, the runtime engine automatically converts the string to a date, using the default format mask.
You should, however, avoid implicit conversions in your code (Figure 4-1 shows the types of implicit conversions that PL/SQL attempts to perform). There are at least two big problems with relying on PL/SQL to convert data on your behalf:
- Conversion behavior can be unintuitive
PL/SQL may convert data in ways that you don’t expect, resulting in problems, especially within SQL statements.
- Conversion rules aren’t under the control of the developer
These rules can change with an upgrade to a new version of Oracle or by changing database-wide parameters, such as NLS_DATE_FORMAT.
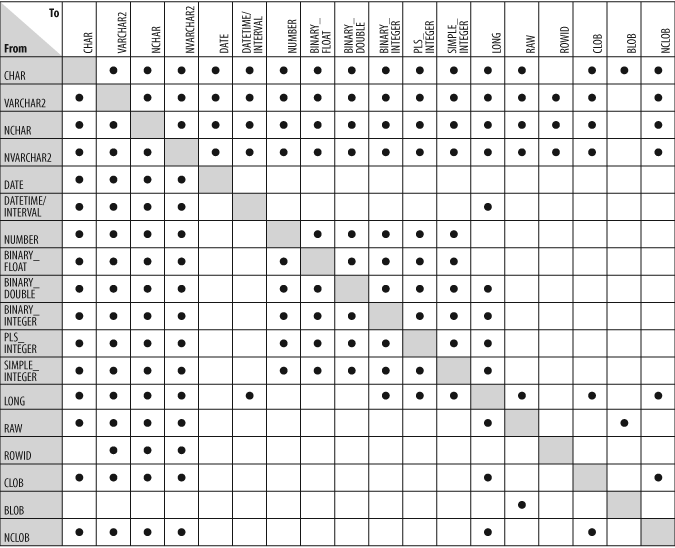
You can convert explicitly using one of the many built-in functions, including TO_DATE, TO_CHAR, TO_NUMBER, and CAST.
Solution: Perform explicit conversions rather than relying on implicit conversions.
Let’s see how I would move from implicit to explicit conversion of the previous declaration.
This code raises an error if the default format mask for the instance is anything but DD-MON-YY or DD-MON-RR. That format is set (and changed) by a database initialization parameter—well beyond the control of most PL/SQL developers. It can also be modified for a specific session. A much better approach, therefore, is:
DECLARE
my_birthdate DATE :=
TO_DATE ('09-SEP-58', 'DD-MON-RR');Taking this approach makes the behavior of my code more consistent and predictable, since I am not making any assumptions about factors external to my program. Explicit conversions, by the way, would have prevented the vast majority of Y2K issues found within PL/SQL code.
Best Practices for Declaring and Using Package Variables
Use the best practices described in this section when you are declaring variables for use in packages.
Danger, Will Robinson! Globals in use!
Use package globals sparingly and only in package bodies.
Problem: Jasper needs Lizbeth’s program data. Delaware needs Jasper’s program data.
Everyone is working very hard in the final week or two of the coding cycle. Packages are constructed quickly, and everyone needs to reference “stuff” in everyone else’s packages. Here’s one example:
Lizbeth creates a package named mfe_reports to consolidate all reporting-related functionality, including a function that returns the standard header for a report. This header is composed of a top line, a bottom line, and a report-specific string sandwiched in between. Here is Lizbeth’s package specification:
PACKAGE mfe_reports IS topline VARCHAR2(100) := 'My Flimsy Excuse - We Report for You!!!!!!'; bottomline VARCHAR2(100) := '== Report Generation Engine Version 4.3 =='; ... END mfe_reports;
Jasper builds a report in his mfe_acceptability package. He doesn’t like the exclamation marks at the end of the top line, but he can’t get Lizbeth to change it (“Sorry, Jasper, that’s the standard.”). He also thinks putting “=” at the beginning and end of the bottom line is dumb. So he writes the following code:
PACKAGE BODY mfe_acceptability
IS
PROCEDURE acceptance_report IS
c_carriage_return CONSTANT VARCHAR2(1) := CHR(10);
BEGIN
mfe_reports.topline := replace (mfe_reports.topline, '!', '');
mfe_reports.topline := replace (mfe_reports.bottomline, '=', '');
DBMS_OUTPUT.PUT_LINE (
mfe_reports.topline || c_carriage_return ||
'Acceptance Report' || c_carriage_return ||
mfe_reports.bottomline);
... rest of report logic ...
END acceptance_report;And now Jasper can create the report just the way he likes it.
Unfortunately for Jasper, the users are dismayed. They like the exclamation marks and the equals signs. They asked for those characters. And so they complain to Sunita, and Jasper gets in trouble. Jasper’s response? “If you didn’t want me to change it, why didn’t you stop me from changing it?”
A very good question.
Solution: Don’t expose program data in package specifications, letting everyone see and change it.
Lizbeth realizes now that she should have ensured that neither Jasper nor any other developer could change the elements of the header. At first, she thinks to herself: “Well, fine. I will make the variables constants and then Jasper will not be able to change the values.”
PACKAGE mfe_reports
IS
topline CONSTANT VARCHAR2(100) :=
'My Flimsy Excuse - We Report for You!!!!!!';
bottomline CONSTANT VARCHAR2(100) :=
'== Report Generation Engine Version 4.3 ==';
END mfe_reports;This is true. Now Jasper has no choice: he will have to accept the top and bottom lines and use them as is. Otherwise, he will get this error:
PLS-00363: expression 'MFE_REPORTS.TOPLINE' cannot be used as an assignment target
Looking at Jasper’s code, though, Lizbeth realizes that she needs to do more. If she is truly supposed to help people produce standard headers, it doesn’t make any sense for them to be concatenating the various pieces together with line breaks.
So she decides to take things a step further and build a function that does all the work for the user of the mfe_reports package:
PACKAGE mfe_reports
IS
FUNCTION standard_header (text_in in VARCHAR2) RETURN VARCHAR2;
END mfe_reports;
PACKAGE BODY mfe_reports
IS
FUNCTION standard_header (text_in in VARCHAR2) RETURN VARCHAR2
IS
c_carriage_return CONSTANT VARCHAR2(1) := CHR(10);
c_topline CONSTANT VARCHAR2(100) :=
'My Flimsy Excuse - We Report for You!!!!!!';
c_bottomline CONSTANT VARCHAR2(100) :=
'== Report Generation Engine Version 4.3 ==';
BEGIN
RETURN c_topline
|| c_carriage_return
|| text_in
|| c_carriage_return
|| c_bottomline;
END standard_header;
END mfe_reportWith this function in place, Jasper can add the header to his report with nothing more than this:
PACKAGE BODY mfe_acceptability
IS
PROCEDURE acceptance_report IS
BEGIN
DBMS_OUTPUT.PUT_LINE (
mfe_reports.standard_header ('Acceptance Report'));
... rest of report logic ...
END acceptance_report;Sure, he might still gripe a bit about the lack of control over the report header, but at least now he doesn’t have to write nearly as much code. Instead, the central report package does most of the work for him.
Jasper’s direct references (and changes) to the package variables in mfe_reports demonstrated some of the problems associated with global variables. A global variable is a data structure that can be referenced outside the scope or block in which it is declared. A variable declared at the package level (outside any individual procedure or function in that package) is global at one of two levels:
If the variable is declared in the package body, then it is globally accessible to all programs defined within that package.
If the variable is declared in the package specified, then it is accessible to (and directly referenceable by) any program executed from a schema that has EXECUTE authority on that package.
Globals can also be defined in any PL/SQL block. In the following block, for example, the l_publish_date is global to the local display_book_info procedure:
DECLARE
l_publish_date DATE;
...
PROCEDURE display_book_info IS
BEGIN
DBMS_OUTPUT.PUT_LINE (l_publish_date);
END;Globals are dangerous and should be avoided, because they create hidden “dependencies” or side effects. A global doesn’t have to be passed through the parameter list, so it’s hard for you to even know that a global is referenced in a program without looking at the implementation.
Furthermore, if that global is a variable (not a constant) and is declared in the package specification, then you have in effect lost control of your data. You cannot guarantee the integrity of its value, since any program run from a schema that has EXECUTE authority on the package can change the package however the developer of that program desires.
You can avoid using globals, and uncontrolled modifications to globals, in a number of ways:
- Pass the global as a parameter in your procedures and functions
Don’t reference it directly within the program (circumventing the structure and visibility of the parameter list).
- Declare variables, cursors, functions, and other objects as “deeply” as possible
That would be in the block nearest to where, or within which, that object will be used). Doing this will reduce the chance of unintended use by other sections of the code.
- Hide your package data behind “gets and sets”
These are subprograms that control access to the data. This approach is covered in the next best practice.
- Scope declarations as locally as possible
If your variable is used only in a single subprogram, declare it there. If it needs to be shared among multiple programs in a package body, declare it at the package level (but never put the declaration in the package specification).
Packages should have a strong sense of personal space.
Control access to package data with “get and set” modules.
Problem: Data structures declared in a package specification may end up bypassing business rules.
Data structures (scalar variables, collections, cursors) declared in the package specification (not within any specific program) are able to be referenced directly from any program run from a session with EXECUTE authority on the package. This is almost always a bad idea and should be avoided.
Solution: Declare data in the package body, and hide the data structures via functions in the package specification.
Instead, declare all package-level data in the package body and provide “get and set” programs—a function to GET the value and a procedure to SET the value—in the package specification. Developers can then access the data through these programs, and automatically follow whatever rules you establish for manipulating that data.
Suppose that I’ve created a package to calculate fines for overdue books. The fine is, by default, $.10 per day, but it can be changed according to this rule: the fine can never be less than $.05 or more than $.25 per day. Here’s my first version:
PACKAGE overdue_pkg
IS
g_daily_fine NUMBER DEFAULT .10;
FUNCTION days_overdue (isbn_in IN book.isbn%TYPE)
RETURN INTEGER;
-- Relies on g_daily_fine for calculation
FUNCTION fine (isbn_in IN book.isbn%TYPE)
RETURN INTEGER;
END overdue_pkg;You can easily see the problem with this package in the following block:
BEGIN
overdue_pkg.g_daily_fine := .50;
DBMS_OUTPUT.PUT_LINE ('Your overdue fine is ' ||
overdue_pkg.fine (' 1-56592-375-8'));
END;Here I bypassed the business rule and applied a daily fine of $.50! By “publishing” the daily fine variable, I lost control of my data structure and the ability to enforce my business rules.
The following rewrite of overdue_pkg (available on the book’s web site) fixes the problem; for the sake of the trees, I show only the replacement of the g_daily_fine variable with its “get and set” programs:
PACKAGE overdue_pkg IS PROCEDURE set_daily_fine (fine_in IN NUMBER); FUNCTION daily_fine RETURN NUMBER;
and the implementation:
PACKAGE BODY overdue_pkg
IS
g_daily_fine NUMBER DEFAULT .10;
PROCEDURE set_daily_fine (fine_in IN NUMBER)IS
BEGIN
g_daily_fine :=
GREATEST (LEAST (fine_in, .25), .05);
END;
FUNCTION daily_fine RETURN NUMBER IS
BEGIN
RETURN g_daily_fine;
END;Now it’s impossible to bypass the business rule for the daily fine.
Tip
In this particular example, by the way, you will be even better off if you put your maximum and minimum fine information in a table. You could then use the package initialization section to load these limits into package data structures. This way, if (more likely when) the data points change, you won’t have to change the program itself, just some rows and columns in a table.
The only way to change a value is through the set procedure. The values of your data structures are protected; business rules can be enforced without exception.
By hiding the data structure, you also give yourself the freedom to change how that data is defined without affecting all accesses to the data.
Get Oracle PL/SQL Best Practices, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

