Chapter 1. Introduction to SQL*Loader
SQL*Loader is an Oracle-supplied utility that allows you to load data from a flat file into one or more database tables. That’s it. That’s the sole reason for SQL*Loader’s existence.
The basis for almost everything you do with SQL*Loader is a file known as the control file . The SQL*Loader control file is a text file into which you place a description of the data to be loaded. You also use the control file to tell SQL*Loader which database tables and columns should receive the data that you are loading.
Do not confuse SQL*Loader control files with database control files. In a way, it’s unfortunate that the same term is used in both cases. Database control files are binary files containing information about the physical structure of your database. They have nothing to do with SQL*Loader. SQL*Loader control files, on the other hand, are text files containing commands that control SQL*Loader’s operation.
Once you have a data file to load and a control file describing the data contained in that data file, you are ready to begin the load process. You do this by invoking the SQL*Loader executable and pointing it to the control file that you have written. SQL*Loader reads the control file to get a description of the data to be loaded. Then it reads the input file and loads the input data into the database.
SQL*Loader is a very flexible utility, and this short description doesn’t begin to do it justice. The rest of this chapter provides a more detailed description of the SQL*Loader environment and a summary of SQL*Loader’s many capabilities.
The SQL*Loader Environment
When we speak of the SQL*Loader environment, we are referring to the database, the SQL*Loader executable, and all the different files that you need to be concerned with when using SQL*Loader. These are shown in Figure 1-1.
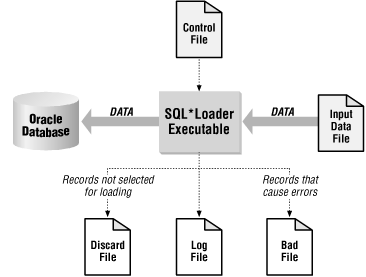
The functions of the SQL*Loader executable, the database, and the input data file are rather obvious. The SQL*Loader executable does the work of reading the input file and loading the data. The input file contains the data to be loaded, and the database receives the data.
Although Figure 1-1 doesn’t show it, SQL*Loader is capable of loading from multiple files in one session. You’ll read more about this in Chapter 2. When multiple input files are used, SQL*Loader will generate multiple bad files and discard files—one set for each input file.
The SQL*Loader Control File
The SQL*Loader control file is the key to any load process. The control file provides the following information to SQL*Loader:
The name and location of the input data file
The format of the records in the input data file
The name of the table or tables to be loaded
The correspondence between the fields in the input record and the columns in the database tables being loaded
Selection criteria defining which records from the input file contain data to be inserted into the destination database tables.
The names and locations of the bad file and the discard file
Some of the items shown in this list may also be passed to SQL*Loader as command-line parameters. The name and location of the input file, for example, may be passed on the command line instead of in the control file. The same goes for the names and locations of the bad files and the discard files.
It’s also possible for the control file to contain the actual data to be loaded. This is sometimes done when small amounts of data need to be distributed to many sites, because it reduces (to just one file) the number of files that need to be passed around. If the data to be loaded is contained in the control file, then there is no need for a separate data file.
The Log File
The log file is a record of SQL*Loader’s activities during a load session. It contains information such as the following:
The names of the control file, log file, bad file, discard file, and data file
The values of several command-line parameters
A detailed breakdown of the fields and datatypes in the data file that was loaded
Error messages for records that cause errors
Messages indicating when records have been discarded
A summary of the load that includes the number of logical records read from the data file, the number of rows rejected because of errors, the number of rows discarded because of selection criteria, and the elapsed time of the load
Always review the log file after a load to be sure that no errors occurred, or at least that no unexpected errors occurred. This type of information is written to the log file, but is not displayed on the terminal screen.
The Bad File and the Discard File
Whenever you insert data into a database, you run the risk of that insert failing because of some type of error. Integrity constraint violations undoubtedly represent the most common type of error. However, other problems, such as the lack of free space in a tablespace, can also cause insert operations to fail. Whenever SQL*Loader encounters a database error while trying to load a record, it writes that record to a file known as the bad file.
Discard files, on the other hand, are used to hold records that do not meet selection criteria specified in the SQL*Loader control file. By default, SQL*Loader will attempt to load all the records contained in the input file. You have the option, though, in your control file, of specifying selection criteria that a record must meet before it is loaded. Records that do not meet the specified criteria are not loaded, and are instead written to a file known as the discard file.
Discard files are optional. You will only get a discard file if you’ve specified a discard file name, and if at least one record is actually discarded during the load. Bad files are not optional. The only way to avoid having a bad file generated is to run a load that results in no errors. If even one error occurs, SQL*Loader will create a bad file and write the offending input record (or records) to that file.
The format of your bad files and discard files will exactly match the format of your input files. That’s because SQL*Loader writes the exact records that cause errors, or that are discarded, to those files. If you are running a load with multiple input files, you will get a distinct set of bad files and discard files for each input file.
You’ll read more about bad files and discard files, and how to use them, in Chapter 7.
A Short SQL*Loader Example
This section contains a short example showing how SQL*Loader is used. For this example, we’ll be loading a file of geographic place names taken from the United States Geological Survey’s (USGS) Geographic Name Information System (GNIS).
Tip
Learn more about GNIS data or download it for yourself by visiting
http://mapping.usgs.gov/www/gnis/. The specific
data file used for this example is also available from http://www.oreilly.com/catalog/orsqlloader
and http://gennick.com/sqlldr.
The Data
The particular file used for this example contains the feature name listing for the State of Michigan. It’s a delimited text file containing the official names of the many thousands of lakes, streams, waterfalls, and other geographic features in the state. The following example shows three records from that file. The lines wrap on the printed page in this book, but in the file each name is on its own line:
"MI","Agate Falls","falls","Ontonagon","26","131","462851N","0890527W", "46.48083","-89.09083","","","","","","","Trout Creek" "MI","Agate Harbor","bay","Keweenaw","26","083","472815N","0880329W", "47.47083","-88.05806","","","","","","","Delaware" "MI","Agate Point","cape","Keweenaw","26","083","472820N","0880241W", "47.47222","-88.04472","","","","","","","Delaware"
As you can see, the data in the file is comma-delimited, and each field is enclosed within double quotes. Table 1-1 shows the contents and maximum length of each field.
|
Field Number |
Maximum Length |
Contents |
|
1 |
2 |
Alphanumeric state code |
|
2 |
60 |
Feature name |
|
3 |
9 |
Feature type |
|
4 |
35 |
County name |
|
5 |
2 |
FIPS state code |
|
6 |
3 |
FIPS county code |
|
7 |
7 |
Primary latitude in degrees, minutes, and seconds |
|
8 |
8 |
Primary longitude in degrees, minutes, and seconds |
|
9 |
8 |
Primary latitude in decimal degrees |
|
10 |
8 |
Primary longitude in decimal degrees |
|
11 |
7 |
Source latitude in degrees, minutes, and seconds |
|
12 |
8 |
Source longitude in degrees, minutes, and seconds |
|
13 |
8 |
Source latitude in decimal degrees |
|
14 |
8 |
Source longitude in decimal degrees |
|
15 |
5 |
Elevation (feet above sea level) |
|
16 |
10 |
Estimated population |
|
17 |
30 |
The name of the USGS 7.5 minute series map on which the feature can be found |
We used the following SQL statement to create the table into which all this data will be loaded:
CREATE TABLE gfn_gnis_feature_names (
gfn_state_abbr CHAR(2),
gfn_feature_name VARCHAR2(60),
gfn_feature_type VARCHAR2(9),
gfn_county_name VARCHAR2(35),
gfn_primary_latitude_dms CHAR(7),
gfn_primary_longitude_dms CHAR(8),
gfn_elevation NUMBER(7,2),
gfn_population NUMBER(10),
gfn_cell_name VARCHAR2(30)
) TABLESPACE gnis_data;As you can see, not all fields in the data file are to be loaded into the table. The source latitude and longitude fields will not be loaded, nor will the decimal versions of the primary latitude and longitude. The FIPS coding will also be omitted.
The Control File
The following control file will be used to load the feature name data for the State of Michigan:
LOAD DATA
APPEND INTO TABLE gfn_gnis_feature_names
(
gfn_state_abbr CHAR TERMINATED BY "," ENCLOSED BY '"',
gfn_feature_name CHAR TERMINATED BY "," ENCLOSED BY '"',
gfn_feature_type CHAR TERMINATED BY "," ENCLOSED BY '"',
gfn_county_name CHAR TERMINATED BY "," ENCLOSED BY '"',
gfn_fips_state_code FILLER INTEGER EXTERNAL
TERMINATED BY "," ENCLOSED BY '"',
gfn_fips_county_code FILLER INTEGER EXTERNAL
TERMINATED BY "," ENCLOSED BY '"',
gfn_primary_latitude_dms CHAR TERMINATED BY "," ENCLOSED BY '"',
gfn_primary_longitude_dms CHAR TERMINATED BY "," ENCLOSED BY '"',
gfn_primary_latitude_dec FILLER DECIMAL EXTERNAL
TERMINATED BY "," ENCLOSED BY '"',
gfn_primary_longitude_dec FILLER DECIMAL EXTERNAL
TERMINATED BY "," ENCLOSED BY '"',
gfn_source_latitude_dms FILLER CHAR
TERMINATED BY "," ENCLOSED BY '"',
gfn_source_longitude_dms FILLER CHAR
TERMINATED BY "," ENCLOSED BY '"',
gfn_source_latitude_dec FILLER DECIMAL EXTERNAL
TERMINATED BY "," ENCLOSED BY '"',
gfn_source_longitude_dec FILLER DECIMAL EXTERNAL
TERMINATED BY "," ENCLOSED BY '"',
gfn_elevation DECIMAL EXTERNAL
TERMINATED BY "," ENCLOSED BY '"',
gfn_population INTEGER EXTERNAL
TERMINATED BY "," ENCLOSED BY '"',
gfn_cell_name CHAR TERMINATED BY "," ENCLOSED BY '"'
)Some explanations are in order. The LOAD DATA command tells SQL*Loader that you are going to load data from an operating system file into a database table. Everything else that you see in this particular control file represents a clause of the LOAD DATA command.
The destination table is identified by the following INTO TABLE clause:
APPEND INTO TABLE gfn_gnis_feature_names
The APPEND keyword tells SQL*Loader to preserve any preexisting data in the table. Other options allow you to delete preexisting data, or to fail with an error if the table is not empty to begin with.
The field definitions are all contained within parentheses, and are separated from each other by commas. The fields in the data file are delimited by commas, and are also enclosed by double quotes. The following clause is used at the end of each field definition to pass this delimiter and enclosure information to SQL*Loader:
TERMINATED BY "," ENCLOSED BY '"'
The following three datatypes are used in this control file. They have no bearing on, or relationship to, the database datatypes of the columns being loaded. The purpose of the datatypes in the control file is to describe the data being loaded from the input data file:
- CHAR
Tells SQL*Loader that a field is a text field.
- INTEGER EXTERNAL
Tells SQL*Loader that a field is an integer represented using the text digits “0” through “9”.
- DECIMAL EXTERNAL
Tells SQL*Loader that a field is a decimal value represented using the text digits “0” through “9” and an optional decimal point (“.”).
Each field is given a name that is meaningful to SQL*Loader. For the nine fields being loaded into the table, the SQL*Loader name must match the corresponding column name in the table. The keyword FILLER identifies the eight fields that are not being loaded into the database. Their names do not matter, but the same naming convention has been followed as for all the rest of the fields.
The Command Line
The command used to initiate this load needs to invoke SQL*Loader and point it to the control file describing the data. In this case, since the input file name is not provided in the control file, that name needs to be passed in on the command line as well. The following sqlldr command will do the job:
sqlldr gnis/gnis@donna control=gnis log=gnis_michigan data=mi_deci.
There are four parameters for this command:
- gnis/gnis@donna
The first parameter consists of a username, password, and net service name. SQL*Loader uses this information to open a connection to the database. The “gnis” user owns the table to be loaded.
- control = gnis
The second parameter tells SQL*Loader that the control file name is gnis.ctl. The default control file extension is .ctl, so the parameter needs to specify only the file name in this case.
- log = gnis_michigan
The third parameter specifies a log file name of gnis_michigan.log. The default log file extension is .log, so it’s not specified explicitly in the parameter setting.
- data = mi_deci.
The fourth parameter specifies an input file name of mi_deci. This name ends with an explicit period, because the file name has no extension. Without the period on the end, SQL*Loader would assume the default extension of .dat.
By not including the input file name in the control file, but instead passing it as a command-line parameter, we’ve made it easy to use the same control file to load feature name data for all 50 states. All we need to do is change the value of the DATA and LOG parameters on the command line. Here’s what it looks like to issue this sqlldr command and load the data:
$ sqlldr gnis/gnis@donna control=gnis log=gnis_michigan data=mi_deci.
SQL*Loader: Release 8.1.5.0.0 - Production on Wed Apr 5 13:35:53 2000
(c) Copyright 1999 Oracle Corporation. All rights reserved.
Commit point reached - logical record count 28
Commit point reached - logical record count 56
Commit point reached - logical record count 84
...
Commit point reached - logical record count 32001
Commit point reached - logical record count 32029
Commit point reached - logical record count 32056Pretty much all you see on the screen when you run SQL*Loader are these “Commit point” messages. If nothing else, they provide some reassurance that the load is progressing, and that your session is not hung. All other information regarding the load is written to the log file.
The Log File
The log file resulting from the load of Michigan’s feature name data begins with the SQL*Loader banner. It goes on to list the names of the files involved in the load, and also the values of some important command-line parameters. For example:
SQL*Loader: Release 8.1.5.0.0 - Production on Wed Apr 5 13:35:53 2000 (c) Copyright 1999 Oracle Corporation. All rights reserved. Control File: gnis.ctl Data File: mi_deci. Bad File: mi_deci.bad Discard File: none specified (Allow all discards) Number to load: ALL Number to skip: 0 Errors allowed: 50 Bind array: 64 rows, maximum of 65536 bytes Continuation: none specified Path used: Conventional
You can see that the names of the control file, bad file, and data file are recorded in the log. This information is invaluable if you ever have problems with a load, or if you ever need to backtrack in order to understand what you really did. The log also displays the number of records to be loaded, the number to be skipped, the number of errors to allow before aborting the load, the size of the bind array, and the data path. The data path is an important piece of information. The load in this example is a conventional path load, which means that SQL*Loader loads the data into the database using INSERT statements. There is another type of load called a direct path load, which has the potential for far better performance than a conventional path load. Direct path loads are discussed in Chapter 10.
The next part of the log file identifies the table being loaded, indicates whether or not preexisting data was preserved, and lists the field definitions from the control file:
Table GFN_GNIS_FEATURE_NAMES, loaded from every logical record. Insert option in effect for this table: APPEND Column Name Position Len Term Encl Datatype ------------------------------ ---------- ----- ---- ---- ------------ GFN_STATE_ABBR FIRST * , " CHARACTER GFN_FEATURE_NAME NEXT * , " CHARACTER GFN_FEATURE_TYPE NEXT * , " CHARACTER GFN_COUNTY_NAME NEXT * , " CHARACTER GFN_FIPS_STATE_CODE NEXT * , " CHARACTER (FILLER FIELD) GFN_FIPS_COUNTY_CODE NEXT * , " CHARACTER (FILLER FIELD) GFN_PRIMARY_LATITUDE_DMS NEXT * , " CHARACTER GFN_PRIMARY_LONGITUDE_DMS NEXT * , " CHARACTER GFN_PRIMARY_LATITUDE_DEC NEXT * , " CHARACTER (FILLER FIELD) GFN_PRIMARY_LONGITUDE_DEC NEXT * , " CHARACTER (FILLER FIELD) GFN_SOURCE_LATITUDE_DMS NEXT * , " CHARACTER (FILLER FIELD) GFN_SOURCE_LONGITUDE_DMS NEXT * , " CHARACTER (FILLER FIELD) GFN_SOURCE_LATITUDE_DEC NEXT * , " CHARACTER (FILLER FIELD) GFN_SOURCE_LONGITUDE_DEC NEXT * , " CHARACTER (FILLER FIELD) GFN_ELEVATION NEXT * , " CHARACTER GFN_POPULATION NEXT * , " CHARACTER GFN_CELL_NAME NEXT * , " CHARACTER
The last part of the log file contains summary information about the load. If there were any errors, or any discarded records, you would see messages for those before the summary. The summary tells you how many rows were loaded, how many had errors, how many were discarded, and so forth. It looks like this:
Table GFN_GNIS_FEATURE_NAMES: 32056 Rows successfully loaded. 0 Rows not loaded due to data errors. 0 Rows not loaded because all WHEN clauses were failed. 0 Rows not loaded because all fields were null. Space allocated for bind array: 65016 bytes(28 rows) Space allocated for memory besides bind array: 0 bytes Total logical records skipped: 0 Total logical records read: 32056 Total logical records rejected: 0 Total logical records discarded: 0 Run began on Wed Apr 05 13:35:53 2000 Run ended on Wed Apr 05 13:36:34 2000 Elapsed time was: 00:00:41.22 CPU time was: 00:00:03.81
You can see from this summary that 32,056 feature names were loaded into the gfn_gnis_feature_names table for the state of Michigan. There were no errors, and no records were discarded. The elapsed time for the load was a bit over 41 seconds.
SQL*Loader’s Capabilities
SQL*Loader is very flexible, and the example in the previous section shows only a small amount of what can be done using the utility. Here are the major SQL*Loader capabilities that you should be aware of:
SQL*Loader can read from multiple input files in a single load session.
SQL*Loader can handle files with fixed-length records, variable-length records, and stream-oriented data.
SQL*Loader supports a number of different datatypes, including text, numeric, zoned decimal, packed decimal, and various machine-specific binary types.
Not only can SQL*Loader read from multiple input files, but it can load that data into several different database tables, all in the same load session.
SQL*Loader allows you to use Oracle’s built-in SQL functions to manipulate the data being read from the input file.
SQL*Loader includes functionality for dealing with whitespace, delimiters, and null data.
In addition to standard relational tables, SQL*Loader can load data into object tables, varying arrays (VARRAYs), and nested tables.
SQL*Loader can load data into large object (LOB) columns.
SQL*Loader can handle character set translation between the input data file and the database.
The capabilities in this list describe the types of data that SQL*Loader can handle, and what SQL*Loader can do to with that data. SQL*Loader also implements some strong, performance-related features. SQL*Loader can do direct path loads, which bypass normal SQL statement processing, and which may yield handsome performance benefits. SQL*Loader can also do parallel loads and even direct-path parallel loads; direct path parallel loads allow you to maximize throughput on multiple CPU systems. You’ll read more about these performance-related features in Chapter 9, and in Chapter 10.
Issues when Loading Data
There are a number of issues that you need to be concerned about whenever you use SQL*Loader to load data into your database—indeed, you need to be concerned about these whenever you load data, period. First, there’s the ever-present possibility that the load will fail in some way before it is complete. If that happens, you’ll be left with some data loaded, and some data not loaded, and you’ll need a way to back out and try again. Other SQL*Loader issues include transaction size, data validation (including referential integrity), and data transformation. Transaction size is partly a performance issue, but it also has an impact on how much data you need to reload in the event that a load fails. Data validation and referential integrity both relate to the need for clean, reliable data.
Recovery from Failure
There are really only two fundamental ways that you can recover from a failed load. One approach is to delete all the data that was loaded before the failure occurred, and simply start over again. Of course, you need to fix whatever caused the failure to occur before you restart the load. The other approach is to determine how many records were loaded successfully, and to restart the load from that point forward. Regardless of which method you choose, you need to think things through before you start a load.
Deleting data and restarting a load from scratch really doesn’t require any special functionality on the part of SQL*Loader. The important thing is that you have a reliable way to identify the data that needs to be deleted. SQL*Loader does, however, provide support for continuing an interrupted load from the point where a failure occurred. Using the SKIP command-line parameter, or the SKIP clause in the control file, you can tell SQL*Loader to skip over records that were already processed in order to have the load pick up from where it left off previously. Chapter 6, describes the process for continuing a load in detail, and some of the issues you’ll encounter. It’s a chapter worth reading, because there are some caveats and gotchas, and you’ll want to learn about those before you have a failure, not afterwards.
Transaction Size
Transaction size is an issue related somewhat to performance, and somewhat to recovery from failure. In a conventional load, SQL*Loader allows you to specify the number of rows that will be loaded between commits. The number of rows that you specify has a direct impact on the size of the bind array that SQL*Loader uses, and consequently on the amount of memory required for the load. The bind array is an area in memory where SQL*Loader stores data for rows to be inserted into the database. When the bind array fills, SQL*Loader inserts the data into the table being loaded, and then executes a COMMIT.
The larger the transaction size, the more data you’ll need to reprocess if you have to restart the load after a failure. However, that’s usually not a significant issue unless your bind array size is quite large. Transaction size can also affect performance. Generally, the more data loaded in one chunk the better. So a larger bind array size typically will lead to better performance. However, it will also lead to fewer commits, resulting in the use of more rollback segment space. Chapter 9 describes these issues in detail.
Data Validation
Data validation is always a concern when loading data. SQL*Loader doesn’t provide a lot of support in this area, but there are some features at your disposal that can help you ensure that only good data is loaded into your database.
The one thing that SQL*Loader does do for you is ensure that the data being loaded into a column is valid given the column’s datatype. Text data will not be loaded into NUMBER fields, and numbers will not be loaded into DATE fields. This much, at least, you can count on. Records containing data that doesn’t convert to the destination datatype are rejected and written to the bad file.
SQL*Loader allows you to selectively load data. Using the WHEN clause in your SQL*Loader control file, you can specify conditions under which a record will be accepted. Records not meeting those conditions are not loaded, and are instead written to the discard file.
Finally, you can take advantage of the referential integrity features built into your database. SQL*Loader won’t be able to load data that violates any type of primary key, unique key, foreign key, or check constraint. Chapter 7, discusses using SQL*Loader and Oracle features to ensure that only good data gets loaded.
Data Transformation
Wouldn’t it be great if the data we loaded was always in a convenient format? Unfortunately, it frequently is not. In the real world, you may deal with data from a variety of sources and systems, and the format of that data may not match the format that you are using in your database. Dates, for example, are represented using a wide variety of formats. The date 1/2/2000 means one thing in the United States and quite another in Europe.
For dates and numbers, you can often use Oracle’s built-in TO_DATE and TO_NUMBER functions to convert a character-based representation to a value that can be loaded into a database DATE or NUMBER column. In fact, for date fields, you can embed the date format into your control file as part of the field definition.
SQL*Loader allows you access to Oracle’s entire library of built-in SQL functions. You aren’t limited to just TO_DATE, TO_NUMBER, and TO_CHAR. Not only can you access all the built-in SQL functions, you can also write PL/SQL code to manipulate the data being loaded. This opens up a world of possibilities, which are discussed in Chapter 8.
Invoking SQL*Loader
On Unix systems, the command used to invoke SQL*Loader is sqlldr . On Windows systems running Oracle8i, release 8.1 or higher, the command is also sqlldr. Prior to release 8.1, the SQL*Loader command on Windows systems included the first two digits of the Oracle release number. Thus you had sqlldr80 (Oracle8, release 8.0), sqlldr73 (Oracle7, release 7.3), and so forth.
SQL*Loader can be invoked in one of three ways:
sqlldr sqlldr keyword=value [keyword=value...] sqlldr value [value...]
Issuing the sqlldr command by itself results in a list of valid command-line parameters being displayed. Command-line parameters are usually keyword/value pairs, and may be any combination of the following:
USERID={username[/password][@net_service_name]|/}
CONTROL=control_file_name
LOG=path_file_name
BAD=path_file_name
DATA=path_file_name
DISCARD=path_file_name
DISCARDMAX=logical_record_count
SKIP=logical_record_count
SKIP_INDEX_MAINTENANCE={TRUE | FALSE}
SKIP_UNUSABLE_INDEXES={TRUE | FALSE}
LOAD=logical_record_count
ERRORS=insert_error_count
ROWS=rows_in_bind_array
BINDSIZE=bytes_in_bind_array
SILENT=[(]keyword[,keyword...][)]
DIRECT={TRUE | FALSE}
PARFILE=path_file_name
PARALLEL={TRUE | FALSE}
READSIZE=bytes_in_read_buffer
FILE=database_datafile_name
Command-line parameters may be passed by position instead of by keyword. The rules for doing this are described at the end of the next section.
Command-Line Parameters
The SQL*Loader parameter descriptions are as follows:
- USERID = {username[/password] [@net_service_name]|/}
Specifies the username and password to use when connecting to the database. The net_service_name parameter optionally allows you to connect to a remote database. Use a forward-slash character ( / ) to connect to a local database using operating system authentication. On Unix systems, you may want to omit the password and allow SQL*Loader to prompt you for it. If you omit both the username and the password, SQL*Loader will prompt you for both.
Tip
On Unix systems you should generally avoid placing a password on the command line, because that password will be displayed whenever other users issue a command, such as ps -ef, that displays a list of current processes running on the system. Either let SQL*Loader prompt you for your password, or use operating system authentication. (If you don’t know what operating system authentication is, ask your DBA.)
- CONTROL = control_ file_name
Specifies the name, which may include the path, of the control file. The default extension is .ctl .
- LOG = path_ file_name
Specifies the name of the log file to generate for a load session. You may include a path as well. By default, the log file takes on the name of the control file, but with a .log extension, and is written to the same directory as the control file. If you specify a different name, the default extension is still .log . However, if you use the LOG parameter to specify a name for the log file, it will no longer be written automatically to the directory that contains the control file.
- BAD = path_ file_name
Specifies the name of the bad file. You may include a path as part of the name. By default, the bad file takes the name of the control file, but with a .bad extension, and is written to the same directory as the control file. If you specify a different name, the default extension is still .bad. However, if you use the BAD parameter to specify a bad file name, the default directory becomes your current working directory. If you are loading data from multiple files, then this bad file name only gets associated with the first file being loaded.
- DATA = path_ file_name
Specifies the name of the file containing the data to load. You may include a path as part of the name. By default, the name of the control file is used, but with the .dat extension. If you specify a different name, the default extension is still .dat. If you are loading from multiple files, you can only specify the first file name using this parameter. Place the names of the other files in their respective INFILE clauses in the control file.
- DISCARD = path_ file_name
Specifies the name of the discard file. You may include a path as part of the name. By default, the discard file takes the name of the control file, but it has a .dis extension. If you specify a different name, the default extension is still .dis. If you are loading data from multiple files, then this discard file name only gets associated with the first file being loaded.
- DISCARDMAX = logical_record_count
Sets an upper limit on the number of logical records that can be discarded before a load will terminate. The limit is actually one less than the value specified for DISCARDMAX. When the number of discarded records becomes equal to the value specified for DISCARDMAX, the load will terminate. The default is to allow an unlimited number of discards. However, since DISCARDMAX only accepts numeric values, it is not possible to explicitly specify the default behavior.
Tip
There is also an undocumented parameter named DISCARDS that functions the same as DISCARDMAX. The use of DISCARDMAX is preferred, but you may occasionally encounter references to DISCARDS.
- SKIP = logical_record_count
Allows you to continue an interrupted load by skipping the specified number of logical records. If you are continuing a multiple table direct path load, you may need to use the CONTINUE_LOAD clause in the control file rather than the SKIP parameter on the command line. CONTINUE_LOAD allows you to specify a different number of rows to skip for each table that you are loading.
- SKIP_INDEX_MAINTENANCE = {TRUE | FALSE}
Controls whether or not index maintenance is done for a direct path load. This parameter does not apply to conventional path loads. A value of TRUE causes index maintenance to be skipped. Any index segments (partitions) that should have been updated will be marked as unusable. A value of FALSE causes indexes to be maintained as they normally would be. The default is FALSE.
- SKIP_UNUSABLE_INDEXES = {TRUE | FALSE}
Controls the manner in which a load is done when a table being loaded has indexes in an unusable state. A value of TRUE causes SQL*Loader to load data into tables even when those tables have indexes marked as unusable. The indexes will remain unusable at the end of the load. One caveat is that if a UNIQUE index is marked as unusable, the load will not be allowed to proceed.
A value of FALSE causes SQL*Loader not to insert records when those records need to be recorded in an index marked as unusable. For a conventional path load, this means that any records that require an unusable index to be updated will be rejected as errors. For a direct path load, this means that the load will be aborted the first time such a record is encountered. The default is FALSE.
- LOAD = logical_record_count
Specifies a limit on the number of logical records to load. The default is to load all records. Since LOAD only accepts numeric values, it is not possible to explicitly specify the default behavior.
- ERRORS = insert_error_count
Specifies a limit on the number of errors to tolerate before the load is aborted. The default is to abort a load when the error count exceeds 50. There is no way to allow an unlimited number of errors. The best you can do is to specify a very high number for this parameter.
- ROWS = rows_in_bind_array
The precise meaning of this parameter depends on whether you are doing a direct path load or a conventional load. If you are doing a conventional load, then you can use this parameter to control the number of rows in the bind array. This represents the number of rows that SQL*Loader loads with each INSERT statement, and also represents the commit frequency. The default is 64 rows.
If you are doing a direct path load, then ROWS specifies the number of rows to read from the input file before saving the data to the database. SQL*Loader will round up the ROWS value to coincide with an even number of database blocks. A data save in a direct path load is analogous to a commit in a conventional path load. The default, when a direct path load is done, is to do one save at the end of the load.
Tip
The BINDSIZE and ROWS parameters both affect the size of the bind array. Chapter 9 discusses this topic in greater detail.
- BINDSIZE = bytes_in_bind_array
Specifies the maximum size, in bytes, of the bind array. This parameter overrides any bind array size computed as a result of using the ROWS parameter. The default bind array size is 65,536 bytes, or 64K.
- SILENT = [( ]keyword [,keyword... ] [ )]
Allows you to suppress various header and feedback messages that SQL*Loader normally displays during a load session. Table 1-2 describes the effect of each of the keywords.
There are two ways you can specify values for the SILENT parameter. If you have only one keyword, you can supply it following the equals sign (=), as follows:
SILENT = ALL
If you have several keywords to use, you can place them in a comma-delimited list. You may optionally place that list inside parentheses. For example:
SILENT = (DISCARDS,ERRORS)
|
Keyword |
Effect |
|
ALL |
Is the same as specifying all the other keywords. |
|
DISCARDS |
Suppresses the message that is normally written to the log file each time a record is discarded. |
|
ERRORS |
Suppresses the error messages that are normally written to the log file when a record generates an Oracle error. |
|
FEEDBACK |
Suppresses the “commit point reached” messages that are normally displayed each time SQL*Loader executes a commit or a save. |
|
HEADER |
Suppresses the messages that SQL*Loader displays on the screen when you first launch the executable. Note, however, that the header messages are always written to the log file. |
|
PARTITIONS |
Suppresses the per-partition statistics that are normally written to the log file when doing a direct path load of a partitioned table. |
- DIRECT = {TRUE | FALSE}
Determines the data path used for the load. A value of FALSE results in a conventional path load. A value of TRUE results in a direct path load. The default is FALSE.
- PARFILE = path_ file_name
Tells SQL*Loader to read command-line parameter values from a text file. This text file is referred to as a parameter file , and contains keyword/value pairs. Usually, the keyword/value pairs are separated by line breaks. Use of the PARFILE parameter can save a lot of typing if you need to perform the same load several times, because you won’t need to retype all the command-line parameters each time. There is no default extension for parameter files.
- PARALLEL = {TRUE | FALSE}
Indicates whether or not you are doing a direct path parallel load. If you are loading the same object from multiple direct path load sessions, then set this to TRUE. Otherwise, set it to FALSE. The default is FALSE.
- READSIZE = bytes_in_read_buffer
Specifies the size of the buffer used by SQL*Loader when reading data from the input file. The default value is 65,536 bytes, or 64K. The values of the READSIZE and BINDSIZE parameters should match. If you supply values for these two parameters that do not match, SQL*Loader will adjust them.
- FILE = database_datafile_name
Specifies the database data file from which to allocate extents. Use this parameter when doing parallel loads, to ensure that each load session is using a different disk. If you are not doing a direct path load, this parameter will be ignored.
In addition to being passed by keyword, parameters may also be passed by position. To do this, you simply list the values after the sqlldr command in the correct order. For example, the following two SQL*Loader commands yield identical results:
sqlldr system/manager profile.ctl profile.log sqlldr userid=system/manager control=profile.ctl log=profile.log
You can even mix the positional and keyword methods of passing command-line parameters. The one rule when doing this is that all positional parameters must come first. Once you start using keywords, you must continue to do so. For example:
sqlldr system/manager control=profile.ctl log=profile.ctl
When you pass parameters positionally, you must not skip any. Also, be sure to get the order right. You must supply parameter values in the order shown earlier in this section. Given the fact that you typically will use only a few parameters out of the many that are possible, it’s usually easier to pass those parameters as keyword/value pairs than it is to pass them positionally. Using keyword/value pairs also makes long SQL*Loader commands somewhat self-documenting. The one exception to this rule is that you might wish to pass the username and password positionally, since they come first, and then pass in the rest of the parameters by name.
Command-Line Syntax Rules
There are several syntax rules to be aware of when writing SQL*Loader commands. These rules fall into the following areas:
Case-sensitivity
Separation of parameters
Special characters in the command line
SQL*Loader itself is not case-sensitive. Keywords on the command line may be in either upper- or lowercase—it doesn’t matter. However, some operating systems, notably Unix, are case-sensitive. When running SQL*Loader on a case-sensitive operating system, you do need to be careful of the case used in file names. You also need to pay attention to the case used for the command to invoke SQL*Loader. On Unix and other case-sensitive operating systems, the SQL*Loader executable name is usually lowercase. So on Unix, Linux, and so forth, use sqlldr. Under Windows, and other operating systems where case doesn’t matter, you can use SQLLDR or sqlldr as you prefer.
Parameters on the command line may be separated by spaces, by commas, or by both spaces and commas. All three of the following commands for example, are legitimate:
sqlldr system/manager,control=product.ctl,log=product.log sqlldr system/manager, control=product.ctl, log=product.log sqlldr system/manager control=product.ctl log=product.log
Spaces are acceptable as well, on either side of the equals sign (=), in keyword/value pairs.
Special characters are rarely needed on the command line, but when you do use them in an option value, you must enclose that value within quotes. For example, beginning with release 8.1.7, if you connect as the user SYS, you also need to specify “AS SYSDBA” as part of your connect string. Because of the spaces, you’ll need to enclose your entire connect string within quotes. For example, for Windows:
sqlldr 'sys/password AS SYSDBA' control=product.ctl (Windows)
And for Unix:
sqlldr \'sys/password AS SYSDBA\' control=product.ctl (Unix)
The backslash characters that you see in the second command are there because some Unix operating systems require that quotes on the command line be escaped. In this example, the backslash was used as the escape character.
Parameter Precedence
The term “command-line” notwithstanding, most SQL*Loader command-line parameters can actually be specified in three different places:
On the command line
In a parameter file, which is then referenced using the PARFILE parameter
In the control file
Parameters on the command line, including those read in from a parameter file, will always override values specified in the control file. In the case of the bad and discard file names, though, the control file syntax allows for each distinct input file to have its own bad file and discard files. The command line syntax does not allow for this, so bad file and discard file names specified on the command line only apply to the first input file. For any other input files, you need to specify these bad and discard file names in the control file or accept the defaults.
The FILE parameter adds a bit of confusion to the rules stated in the previous paragraph. As with the bad file and discard file names, you can have multiple FILE values in the control file. However, when you specify the FILE parameter on the command line, it does override any and all FILE values specified in the control file.
Parameters read from a parameter file as a result of using the PARFILE parameter may override those specified on the command line. Whether or not that happens depends on the position of the PARFILE parameter with respect to the others. SQL*Loader processes parameters from left to right, and the last setting for a given parameter is the one that SQL*Loader uses.
Get Oracle SQL*Loader: The Definitive Guide now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

