40 Preparing for DB2 Near-Realtime Business Intelligence
to apply this batch of data to the data warehouse concurrently with executing
queries. This may seem counterintuitive while discussing near-realtime data
warehousing, but could be an effective way of reaching a near-realtime feed to
the data warehouse. There are many factors that may lead us to more of a batch
type Transform function. First of all, the data may be delivered in batches. Some
of the required transformations or auditing functions can only be performed on a
batch of data. The data could be supplied in typical batch fashion or may be
provided continuously - but will be staged in a message queue or relational table
until ready to be processed as a batch. These batch Transform functions may be
scheduled to run at some periodic interval ranging from every minute or so to
every few hours, while some will be automatically invoked, on-demand, based on
the arrival of specific data or conditions.
There are businesses today using a batch method in which they receive batch
files around the clock, and must get that data into the 24x7 data warehouse
within a certain time after receiving the data file. This is most definitely a form of
near-realtime data warehousing.
The continuous architecture is similar to what is done today in an EAI system.
When a data record, probably in the form of a message, is available, it is acted on
as soon as it is received. There is typically some type of application that is
looking at, or listening to, a message queue. Then, when a message appears on
the queue, it will be acted upon. There are many different approaches, from an
implementation viewpoint, for detecting that a message has appeared in the
queue and how it should be processed. While some mainstream ETL processes
can access message queues as a source, some of these tools may still have to
operate on a batch basis. However, this is the area where EAI tools, or message
brokers, excel. They can take a message from a message queue, processing it,
and put it into a queue and/or a relational table. However, these EAI tools are
sometimes limited in the transformations they can perform. The trend is to blend
the capabilities of these two types of tools.
As discussed, you can effectively perform the Transform function using a batch
style architecture or a continuous architecture.
3.5.4 Apply
The Apply function has a specific but very important purpose. That is to take the
changed data from the data buffer and apply those to the data warehouse. This
function is where the concurrency issues arise. The data warehouse tables will
need to be updated along with concurrent query activity. There are a number of
ways to accomplish this task.
One technique is to set aside a special area in the data warehouse to contain the
realtime data to which the changed data will be applied. This is depicted in
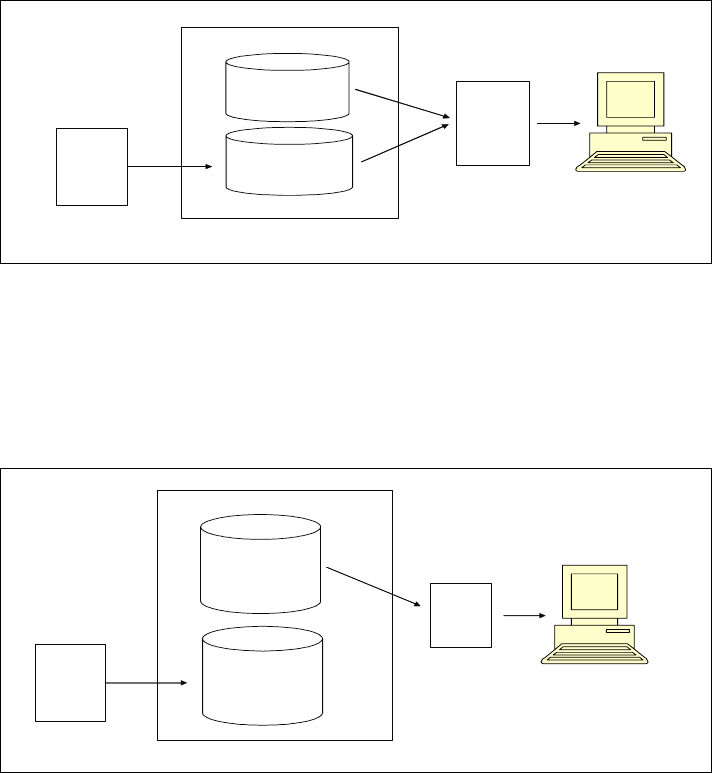
Chapter 3. Architectural considerations 41
Figure 3-9 on page 41. This will help limit locking contention to the realtime data
and only those queries that access the realtime component will have locking
issues. Of course, the fact that there is a realtime component will have to be
taken into consideration by the end-users. Or, it will have to be hidden by the use
of cursors or within the query tool. At some point in time, however, you may want
this realtime data applied to the data warehouse tables.
Figure 3-9 Separate realtime component
Another technique is to have two copies of your data, as depicted in Figure 3-10.
One copy of the data is accessible to the end-users, and the other is used to
house the new realtime data. Then at some periodic interval, you can perform a
switch and the end-users can begin accessing the newest data. This can be
accomplished, for example, with views and/or aliases - or even table renames.
Figure 3-10 Load and switch
There are many variations on these techniques that businesses have used.
Ideally, you would like to be able to apply the realtime data directly to its target
Apply
Data
Warehouse
Realtime
Component
View
Or
Query
Tool
Apply
Data
Warehouse
Table A
Data
Warehouse
Table A’
View
Or
Alias
Get Preparing for DB2 Near-Realtime Business Intelligence now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

