In this recipe, we solve the Blackjack game with on-policy MC control by exploring starts. This accomplishes our policy optimization goal by alternating between evaluation and improvement with each episode we simulate.
In Step 2, we run an episode and take actions under a Q-function by performing the following tasks:
- We initialize an episode.
- We take a random action as an exploring start.
- After the first action, we take actions based on the current Q-function, that is,
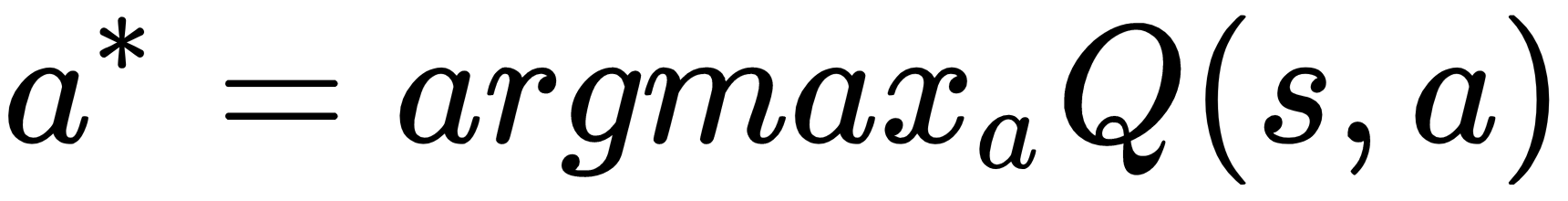 .
. - We record the states, actions, and rewards for all steps in the episode, which will be used in the evaluation phase.
It is important to note that the first ...

